

- Performance tips and parallel execution
- Thread-safety of user-defined expressions
- Parallel execution of multiple RDataFrame event loops
- Performance considerations
- Memory usage
- Cheat sheet
- Transformations
- Actions
- Queries
- Logging
- Using the service
- Root Logger
- Configuring the service
- Discovery
- Using the service
- Database
- Using the service
- Stick tables
- Multiprocessing
- Синтаксис
- Хранение данных
- Использование значений
- Просмотр содержимого
- Примеры
- Root Lifecycle
- Configure the service
- URL Readers
- Using the service
- Distributed execution
- Connecting to a Spark cluster
- Connecting to a Dask cluster
- Choosing the number of distributed tasks
- Distributed Snapshot
- Distributed RunGraphs
- Histogram models in distributed mode
- Lifecycle
- Using the service
- Карты (maps)
- map()
- Обновление карты
- Примеры
- Paths rate limit
- Чёрный список
- Identity
- Using the service
- Configuring the service
- Cache
- Using the service
- Working with collections and object selections
- For the impatient user
- Crash course
- Creating an RDataFrame
- Filling a histogram
- Applying a filter
- Defining custom columns
- Running on a range of entries
- Executing multiple actions in the same event loop
- Going parallel
- Root HTTP Router
- Using the service
- Configuring the service
- Permissions
- Using the service
- Кластер
- Синхронизация конфигурации
- More features
- Systematic variations
- RDataFrame objects as function arguments and return values
- Storing RDataFrame objects in collections
- Executing callbacks every N events
- Default column lists
- Special helper columns: rdfentry_ and rdfslot_
- Just-in-time compilation: column type inference and explicit declaration of column types
- User-defined custom actions
- Implementing custom actions with Book()
- Injecting arbitrary code in the event loop with Foreach() and ForeachSlot()
- Friend trees
- Reading data formats other than ROOT trees
- Computation graphs (storing and reusing sets of transformations)
- Visualizing the computation graph
- Activating RDataFrame execution logs
- Creating an RDataFrame from a dataset specification file
- Scheduler
- Using the service
- Manipulating data
- Filters
- Named filters and cutflow reports
- Ranges
- Custom columns
- Custom columns as function of slot and entry number
- Логи
- HTTP Router Service
- Using the service
- Configuring the service
- Config
- Using the service
- Configuring the service
- Efficient analysis in Python
- User code in the RDataFrame workflow
- C++ code
- Python code
- Interoperability with NumPy
- Conversion to NumPy arrays
- Processing data stored in NumPy arrays
- Construct histogram and profile models from a tuple
- AsRNode helper function
- ACL
- Выборка (fetch)
- Конвертер
- Флаги
- Сравнения
- Выборки со встроенным сравнением
- Сравнения с числами
- Значения
- Действия
- Переменные
- Карты и ACL-файлы
- ACL-файлы
- Карты
Performance tips and parallel execution
- Warning
- By default, RDataFrame will use as many threads as the hardware supports, using up all the resources on a machine. This might be undesirable on shared computing resources such as a batch cluster. Therefore, when running on shared computing resources, use replacing
iwith the number of CPUs/slots that were allocated for this job.
Thread-safety of user-defined expressions
Note that simple Filter() and Define() transformations will inherently satisfy this requirement: Filter() / Define() expressions will often be pure in the functional programming sense (no side-effects, no dependency on external state), which eliminates all risks of race conditions.
Parallel execution of multiple RDataFrame event loops
A complex analysis may require multiple separate RDataFrame computation graphs to produce all desired results. This poses the challenge that the event loops of each computation graph can be parallelized, but the different loops run sequentially, one after the other. On many-core architectures it might be desirable to run different event loops concurrently to improve resource usage. ROOT::RDF::RunGraphs() allows running multiple RDataFrame event loops concurrently:
histo1 = df1.Histo1D();
histo2 = df2.Histo1D();
unsigned int RunGraphs(std::vector< RResultHandle > handles)
Trigger the event loop of multiple RDataFrames concurrently.
Performance considerations
Python applications cannot easily specify template parameters or pass C++ callables to RDataFrame. See Efficient analysis in Python for possible ways to speed up hot paths in this case.
Just-in-time compilation happens once, right before starting an event loop. To reduce the runtime cost of this step, make sure to book all operations for all RDataFrame computation graphs before the first event loop is triggered: just-in-time compilation will happen once for all code required to be generated up to that point, also across different computation graphs.
Also make sure not to count the just-in-time compilation time (which happens once before the event loop and does not depend on the size of the dataset) as part of the event loop runtime (which scales with the size of the dataset). RDataFrame has an experimental logging feature that simplifies measuring the time spent in just-in-time compilation and in the event loop (as well as providing some more interesting information). See Activating RDataFrame execution logs.
Memory usage
There are two reasons why RDataFrame may consume more memory than expected. Firstly, each result is duplicated for each worker thread, which e.g. in case of many (possibly multi-dimensional) histograms with fine binning can result in visible memory consumption during the event loop. The thread-local copies of the results are destroyed when the final result is produced. Reducing the number of threads or using coarser binning will reduce the memory usage.
Secondly, just-in-time compilation of string expressions or non-templated actions (see the previous paragraph) causes Cling, ROOT‘s C++ interpreter, to allocate some memory for the generated code that is only released at the end of the application. This commonly results in memory usage creep in long-running applications that create many RDataFrames one after the other. Possible mitigations include creating and running each RDataFrame event loop in a sub-process, or booking all operations for all different RDataFrame computation graphs before the first event loop is triggered, so that the interpreter is invoked only once for all computation graphs:
h1 = df1.Histo1D();
h2 = df2.Histo1D();
h1 = df1.Histo1D();
h2 = df2.Histo1D();
Cheat sheet
These are the operations which can be performed with RDataFrame.
Transformations
Transformations are a way to manipulate the data.
Actions
Actions aggregate data into a result. Each one is described in more detail in the reference guide.
Lazy actions only trigger the event loop when one of the results is accessed for the first time, making it easy to produce many different results in one event loop. Instant actions trigger the event loop instantly.
Queries
These operations do not modify the dataframe or book computations but simply return information on the RDataFrame object.
Logging
This service allows plugins to output logging information. There are actually two logger services: a root logger, and a plugin logger which is bound to individual plugins, so that you will get nice messages with the plugin ID referenced in the log lines.
Using the service
"Here's a nice log line that's a warning!"
Root Logger
The root logger is the logger that is used by other root services. It’s where the implementation lies for creating child loggers around the backstage ecosystem including child loggers for plugins with the correct metadata and annotations.
If you want to override the implementation for logging across all of the backend, this is the service that you should override.
Configuring the service
// here's some additional information that is not part of the
// original implementation
Discovery
When building plugins, you might find that you will need to look up another plugin’s base URL to be able to communicate with it. This could be for example an HTTP route or some ws protocol URL. For this we have a discovery service which can provide both internal and external base URLs for a given a plugin ID.
Using the service
// can also use discovery.getBaseUrl to retrieve external URL
Database
This service lets your plugins get a knex client hooked up to a database which is configured in your app-config YAML files, for your persistence needs.
If there’s no config provided in backend.database then you will automatically get a simple in-memory SQLite 3 database for your plugin whose contents will be lost when the service restarts.
This service is scoped per plugin too, so that table names do not conflict across plugins.
Using the service
Stick tables
Хранилище «ключ-значение». Ключом может быть IP, Integer, String, Binary.
Популярные значения — conn_cur, conn_rate, http_req_rate, http_err_rate, server_id.
Привязки клиента к серверу
SSL session ID
Login brute force
API key usage
Таблица может быть только одна в секции frontend/backend/listen.
Данные в неё добавляются с помощью действия track-sc0 в командах tcp-request connect, tcp-request content, http-request, http-response.
В примере используется пустой бэкенд с таблицей, на который идёт ссылка как на таблицу из фронтенда.
backend st_src_global stick-table 1m expire 10s store http_req_rate10s frontend fe_main : http-request track-sc0 src table st_src_global http-request deny sc_http_req_rate gt
Multiprocessing
Если используется nbproc (версия 1.8 и старее), то у каждого процесса будет свой набор таблиц.
Если используется nbthread (версия 1.9 и новее), то все процессы используют один и тот же набор таблиц.
Синтаксис
backend st_ip# stick-table тип <ключ> размер <кол-во строк> истекает <время> хранить <значение,значение,значение> stick-table 1m expire 10s store http_req_rate10s,conn_cur,gpc0За типами string и binary идёт параметр len (длина) — это число байт для захвата, если входное значение больше, оно урезается.
Размер — кол-во строк в таблице (здесь 1 млн), нужен, чтобы не забить всю память. Из практических соображений не нужно задавать слишком много значений, т. к. может понадобиться сделать ещё несколько таблиц. На одну строку нужно 50 байт + размер ключа + размер значений.
Истечение срока хранения — максимальное время, прошедшее с момента добавления, обновления или сравнения записи в таблице, после истечения запись удаляется. В случае с таблицей, хранящей частоту запросов (rate), срок хранения должен равняться периоду изменения частоты запросов, чтобы срок хранения и окончание периода измерения совпадали.
Хранение данных
http-request track-sc0 src table st_ip
sc0 — sticky counter 0
src — выборка, ключ для отслеживания
Частота запросов/сканирование: src, base32 (IP + URL), req.hdr(Authorization)
Статистика: req.hdr(host), ssl_fc_protocol, path
Привязка: src, req.cook(sessionid)
table — какую таблицу использовать. Этот параметр не нужен, если таблица находится в той же секции.
В рамках одной сессии нужен уникальный номер sc для каждой записи.
Здесь нужны разные номера, т. к. они активны для каждой сессии:
http-request track-sc0 src table st_src http-request track-sc1 base32 table st_base32
А здесь — нет, т. к. они никогда не пересекаются:
http-request track-sc0 src st_src_get METH_GET http-request track-sc0 src st_src_post METH_POST
Номер задаётся флагом компиляции
MAX_SESS_STKCTR, в HAPEE 12 номеров.
Использование значений
1) С помощью выборки. Выборка, ссылающаяся на счётчик (sc), чаще всего имеет префикс sc_, и соответствующий номер как аргумент.
http-request deny sc_http_req_rate gt
Популярные выборки: sc_http_req_rate, sc_conn_cur, sc_conn_rate.
2) С помощью конвертера, если не задействованы счётчики. На входе — ключ, аргумент конвертера — имя таблицы.
http-request deny src,table_http_req_ratest_src gt
Применяется для таблиц, если используется peers.
Просмотр содержимого
С помощью API-запросов. В версии Enterprise есть веб-интерфейс.
"show table st_src_global" socat stdio varhaproxyadmin.sock# Обновлять каждые 5 секунд
Примеры
Постоянное подключение к одному из серверов (привязка) + peers
# Протокол peers позволяет передавать данные из таблицы на все сервера-партнёрыpeers mypeers # Имя партнёра должно совпадать с его hostname, либо с заданным в секции global его конфигурации haproxy peer haproxy1 192.168.1.11: peer haproxy2 192.168.1.12: backend mybackend mode tcp balance roundrobin # Здесь нет указания значений, т. к. server ID добавляется автоматически stick-table 20k peers mypeers # К чему привязываться при закреплении пользователя к серверу stick on src server srv1 192.168.1.101: server srv2 192.168.1.102:
backend st_src_global stick-table 1m expire 10s store http_req_rate10s frontend fe_main : http-request track-sc0 src table st_src_global http-request deny sc_http_req_rate gt
Web scraping — в этом примере блокируются те IP, которые зашли на более чем 15 разных URL за последние 24 часа.
backend per_ip_and_url_rates stick-table binary len 1m expire 24h store http_req_rate24h backend per_ip_rates stick-table 1m expire 24h store gpc0,gpc0_rate30s frontend fe_main : http-request track-sc0 src table per_ip_rates http-request track-sc1 url32+src table per_ip_and_url_rates unless path_end .css .js .png .jpeg .gif acl exceeds_limit sc_gpc0_rate gt # Увеличить gpc0, если http_req_rate = 1 (он равен единице, когда кто-то запрашивает url первый раз) # Если url запрашивается не в первый раз, то http_req_rate будет больше 1, и это не сработает http-request sc-inc-gpc0 sc_http_req_rate eq exceeds_limit http-request deny exceeds_limit default_backend web_servers
Root Lifecycle
This service is the same as the lifecycle service, but should only be used by the root services. This is also where the implementation for the actual lifecycle hooks are collected and executed, so if you want to override the implementation of how those are processed, you should override this service.
Configure the service
Shutdown hook succeeded
URL Readers
These URL readers are basically wrappers with authentication for files and folders that could be stored in these VCS repositories.
Using the service
Distributed execution
RDataFrame applications can be executed in parallel through distributed computing frameworks on a set of remote machines thanks to the Python package ROOT.RDF.Experimental.Distributed. This experimental, Python-only package allows to scale the optimized performance RDataFrame can achieve on a single machine to multiple nodes at the same time. It is designed so that different backends can be easily plugged in, currently supporting Apache Spark and Dask. To make use of distributed RDataFrame, you only need to switch ROOT.RDataFrame with the backend-specific RDataFrame of your choice, for example:
RDataFrame = ROOT.RDF.Experimental.Distributed.Spark.RDataFrame
df = RDataFrame(, )
sum = df.Filter(«x > 10»).Sum()
h = df.Histo1D((, , 10, 0, 10), )
The main goal of this package is to support running any RDataFrame application distributedly. Nonetheless, not all parts of the RDataFrame API currently work with this package. The subset that is currently available is:
Connecting to a Spark cluster
In order to distribute the RDataFrame workload, you can connect to a Spark cluster you have access to through the official Spark API, then hook the connection instance to the distributed RDataFrame object like so:
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
RDataFrame = ROOT.RDF.Experimental.Distributed.Spark.RDataFrame
df = RDataFrame(, , sparkcontext = sc)
If an instance of SparkContext is not provided, the default behaviour is to create one in the background for you.
Connecting to a Dask cluster
Similarly, you can connect to a Dask cluster by creating your own connection object which internally operates with one of the cluster schedulers supported by Dask (more information in the Dask distributed docs):
dask.distributed Client
RDataFrame = ROOT.RDF.Experimental.Distributed.Dask.RDataFrame
__name__ == :
client = Client()
df = RDataFrame(,, daskclient=client)
df.Define(,).Histo1D((, , 10, 0, 10), )
If an instance of distributed.Client is not provided to the RDataFrame object, it will be created for you and it will run the computations in the local machine using all cores available.
Choosing the number of distributed tasks
A distributed RDataFrame has internal logic to define in how many chunks the input dataset will be split before sending tasks to the distributed backend. Each task reads and processes one of said chunks. The logic is backend-dependent, but generically tries to infer how many cores are available in the cluster through the connection object. The number of tasks will be equal to the inferred number of cores. There are cases where the connection object of the chosen backend doesn’t have information about the actual resources of the cluster. An example of this is when using Dask to connect to a batch system. The client object created at the beginning of the application does not automatically know how many cores will be available during distributed execution, since the jobs are submitted to the batch system after the creation of the connection. In such cases, the logic is to default to process the whole dataset in 2 tasks.
The number of tasks submitted for distributed execution can be also set programmatically, by providing the optional keyword argument npartitions when creating the RDataFrame object. This parameter is accepted irrespectively of the backend used:
__name__ == :
df = RDataFrame(,, npartitions=NPARTITIONS)
df.Define(,).Histo1D((, , 10, 0, 10), )
Note that when processing a TTree or TChain dataset, the npartitions value should not exceed the number of clusters in the dataset. The number of clusters in a TTree can be retrieved by typing rootls -lt myfile.root at a command line.
Distributed Snapshot
The Snapshot operation behaves slightly differently when executed distributedly. First off, it requires the path supplied to the Snapshot call to be accessible from any worker of the cluster and from the client machine (in general it should be provided as an absolute path). Another important difference is that n separate files will be produced, where n is the number of dataset partitions. As with local RDataFrame, the result of a Snapshot on a distributed RDataFrame is another distributed RDataFrame on which we can define a new computation graph and run more distributed computations.
Distributed RunGraphs
Submitting multiple distributed RDataFrame executions is supported through the RunGraphs function. Similarly to its local counterpart, the function expects an iterable of objects representing an RDataFrame action. Each action will be triggered concurrently to send multiple computation graphs to a distributed cluster at the same time:
RDataFrame = ROOT.RDF.Experimental.Distributed.Dask.RDataFrame
RunGraphs = ROOT.RDF.Experimental.Distributed.RunGraphs
.Histo1D((, , 10, 0, 100), )
_ range(4)
Every distributed backend supports this feature and graphs belonging to different backends can be still triggered with a single call to RunGraphs (e.g. it is possible to send a Spark job and a Dask job at the same time).
Histogram models in distributed mode
When calling a Histo*D operation in distributed mode, remember to pass to the function the model of the histogram to be computed, e.g. the axis range and the number of bins:
__name__ == :
df = RDataFrame(,).Define(,)
df.Histo1D((, , 10, 0, 10), )
A struct which stores the parameters of a TH1D.
Without this, two partial histograms resulting from two distributed tasks would have incompatible binning, thus leading to errors when merging them. Failing to pass a histogram model will raise an error on the client side, before starting the distributed execution.
Lifecycle
This service allows your plugins to register hooks for cleaning up resources as the service is shutting down (e.g. when a pod is being torn down, or when pressing Ctrl+C during local development). Other core services also leverage this same mechanism internally to stop themselves cleanly.
Using the service
// some example work that we want to stop when shutting down
// do some other stuff.
Карты (maps)
Направления трафика на бэкенды
Лимитов для доменов/путей
Карта выглядит примерно так:
# key valueexample.com be_example
haproxy.com be_haproxy
test.ru be_testfrontend fe_main : ssl crt etcsslcertsmain # Взять хост из заголовка, перевести в нижний регистр, искать значение в карте. # Если значения нет, использовать значение по умолчанию (здесь: be_static) use_backend req.hdrhost,lower,map_dometchaproxymapshosts.map,be_static
map()
На вход в конвертер карты подаётся образец, который нужно найти, например,
src,map(/etc/haproxy/ips.map). Конвертер он потому, что, в отличие от обычной выборки, он значение даёт не сам, а ищет его в стороннем файле.Обязательным значением является путь к файлу карты.
Необязательный аргумент — значение по умолчанию.
Возвращает значение из второй колонки, если найдено совпадение строки в первой.
Варианты сравнения — str, beg, sub, dir, dom, end, reg, regm, int, ip
Обновление карты
Так как haproxy читает файлы только во время инициализации, нужен метод для обновления карт без перезапуска haproxy.
Все методы не обновляют самих файлов карт на диске! Чтобы обновлять сами файлы, нужно отдельно запускать show map и дамп в файл (например, в кроне).
Первый метод — модуль LB-Update (только для версии enterprise). Его легко настраивать, он хорошо работает в кластерах.
dynamic-update update etchapee-mapssample.map url http:10.0.0.1sample.map delay 300s
Второй метод — через сокет (см. https://www.haproxy.com/blog/dynamic-configuration-haproxy-runtime-api/).
"show map /etc/haproxy/domains.map" socat stdio varrunhaproxyadmin.sock "clear map /etc/haproxy/domains.map" socat stdio varrunhaproxyadmin.sock "del map /etc/haproxy/domains.map example.com" socat stdio varrunhaproxyadmin.sock# add map не проверяет, есть ли добавляемое уже в карте, есть риск получить дубль,# поэтому надо сочетать это в скрипте с show map, чтобы проверить наличие до добавления "add map /etc/haproxy/domains.map example.com be_example" socat stdio varrunhaproxyadmin.sock "set map /etc/haproxy/domains.map example.com be_example" socat stdio varrunhaproxyadmin.sock
При использовании nbproc у каждого процесса haproxy свой взгляд на файлы карт. В отличие от модуля lb-update здесь у каждого процесса свой сокет, и нужно обновлять карты для каждого процесса. С версии 1.9 используется усовершенствованный nbthread, позволяющий работать без потерь производительности при нескольких процессах haproxy.
https://www.haproxy.com/blog/multithreading-in-haproxy/
Третий — через ACL (неприменимо, если используется nbproc)
frontend fe_main : # при запросе определённого url из определённой сети acl in_network src 192.168.122.0 acl is_map_add path_beg mapadd # задать запись в карте (в памяти) http-request set-mapetchaproxymapshosts.map url_paramdomain url_parambackend is_map_add in_network # не передавать этот запрос на бэкенд http-request deny deny_status is_map_add in_network # использовать бэкенд с картой при всех прочих запросах use_backend req.hdrhost,lower,mapetchaproxymapshosts.map
Примеры
Paths rate limit
/api/routeA 40 /api/routeB 20
frontend api_gateway : default_backend api_servers # Set up stick table to track request rates stick-table binary len 1m expire 10s store http_req_rate10s # Track client by base32+src (Host header + URL path + src IP) http-request track-sc0 base32+src # Check map file to get rate limit for path http-request set-varreq.rate_limit path,map_begetchaproxymapsrates.map # Client's request rate is tracked http-request set-varreq.request_rate base32+src,table_http_req_rateapi_gateway # Subtract the current request rate from the limit # If less than zero, set rate_abuse to true acl rate_abuse varreq.rate_limit,subreq.request_rate lt # Deny if rate abuse http-request deny deny_status rate_abuse
Чёрный список
Пример файла ACL.
acl is_admin_ip src 192.168.122.0 127.0.0.0# добавляем-удаляем значения с админских диапазоновhttp-request add-acletchaproxyblacklist.acl url_param is_admin_ip path_beg blacklistadd http-request del-acletchaproxyblacklist.acl url_param is_admin_ip path_beg blacklistdel # не пробрасывать никуда, если правится чёрный списокhttp-request deny deny_status is_admin_ip path_beg blacklist # блочить, собственно, значения из спискаhttp-request deny src etchaproxyblacklist.acl
Identity
Using the service
Configuring the service
There’s additional configuration that you can optionally pass to setup the identity core service.
issuer— Set an optional issuer for validation of the JWT tokenalgorithms—algheader for validation of the JWT token, defaults toES256. More info on supported algorithms can be found in thejoselibrary documentation
Cache
This service lets your plugin interact with a cache. It is bound to your plugin too, so that you will only set and get values in your plugin’s private namespace.
Using the service
// .. some other stuff.
Working with collections and object selections
RDataFrame reads collections as the special type ROOT::RVec: for example, a column containing an array of floating point numbers can be read as a ROOT::RVecF. C-style arrays (with variable or static size), STL vectors and most other collection types can be read this way.
RVec is a container similar to std::vector (and can be used just like a std::vector) but it also offers a rich interface to operate on the array elements in a vectorised fashion, similarly to Python’s NumPy arrays.
And in Python:
For the impatient user
You can directly see RDataFrame in action in our tutorials, in C++ or Python.
Crash course
All snippets of code presented in the crash course can be executed in the ROOT interpreter. Simply precede them with
ROOT;
This file contains a specialised ROOT message handler to test for diagnostic in unit tests.
which is omitted for brevity. The terms «column» and «branch» are used interchangeably.
Creating an RDataFrame
RDataFrame d2(, f);
RDataFrame d6(, );
A chain is a collection of files containing TTree objects.
static TFile * Open(const char *name, Option_t *option=»», const char *ftitle=»», Int_t compress=ROOT::RCompressionSetting::EDefaults::kUseCompiledDefault, Int_t netopt=0)
Create / open a file.
This is useful to generate simple datasets on the fly: the contents of each event can be specified with Define() (explained below). For example, we have used this method to generate Pythia events and write them to disk in parallel (with the Snapshot action).
For data sources other than TTrees and TChains, RDataFrame objects are constructed using ad-hoc factory functions (see e.g. FromCSV(), FromSqlite(), FromArrow()):
Factory method to create a CSV RDataFrame.
Filling a histogram
Let’s now tackle a very common task, filling a histogram:
h = d.Histo1D();
The first line creates an RDataFrame associated to the TTree «myTree». This tree has a branch named «MET».
Histo1D() is an action; it returns a smart pointer (a ROOT::RDF::RResultPtr, to be precise) to a TH1D histogram filled with the MET of all events. If the quantity stored in the column is a collection (e.g. a vector or an array), the histogram is filled with all vector elements for each event.
You can use the objects returned by actions as if they were pointers to the desired results. There are many other possible actions, and all their results are wrapped in smart pointers; we’ll see why in a minute.
Applying a filter
Let’s say we want to cut over the value of branch «MET» and count how many events pass this cut. This is one way to do it:
c = d.Filter(«MET > 4.»).Count();
std::cout << *c << std::endl;
The filter string (which must contain a valid C++ expression) is applied to the specified columns for each event; the name and types of the columns are inferred automatically. The string expression is required to return a bool which signals whether the event passes the filter (true) or not (false).
You can think of your data as «flowing» through the chain of calls, being transformed, filtered and finally used to perform actions. Multiple Filter() calls can be chained one after another.
std::cout << *c << std::endl;
RResultPtr< ULong64_t > Count()
Return the number of entries processed (lazy action).
An example of a more complex filter expressed as a string containing C++ code is shown below
.Filter(«double p2 = 0.0; for (auto&& x : p) p2 += x*x; return sqrt(p2) < 10.0;»);
The code snippet above defines a column p that is a fixed-size array using the component column names and then filters on its magnitude by looping over its elements. It must be noted that the usage of strings to define columns like the one above is currently the only possibility when using PyROOT. When writing expressions as such, only constants and data coming from other columns in the dataset can be involved in the code passed as a string. Local variables and functions cannot be used, since the interpreter will not know how to find them. When capturing local state is necessary, it must first be declared to the ROOT C++ interpreter.
More information on filters and how to use them to automatically generate cutflow reports can be found below.
Defining custom columns
Let’s now consider the case in which «myTree» contains two quantities «x» and «y», but our analysis relies on a derived quantity z = sqrt(x*x + y*y). Using the Define() transformation, we can create a new column in the dataset containing the variable «z»:
std::cout << *zMean << std::endl;
RResultPtr< double > Mean(std::string_view columnName=»»)
Return the mean of processed column values (lazy action).
Define() creates the variable «z» by applying sqrtSum to «x» and «y». Later in the chain of calls we refer to variables created with Define() as if they were actual tree branches/columns, but they are evaluated on demand, at most once per event. As with filters, Define() calls can be chained with other transformations to create multiple custom columns. Define() and Filter() transformations can be concatenated and intermixed at will.
As with filters, it is possible to specify new columns as string expressions. This snippet is analogous to the one above:
zMean = d.Define(, «sqrt(x*x + y*y)»).Mean();
std::cout << *zMean << std::endl;
Again the names of the columns used in the expression and their types are inferred automatically. The string must be valid C++ and it is just-in-time compiled. The process has a small runtime overhead and like with filters it is currently the only possible approach when using PyROOT.
x = -1;
Define a new column.
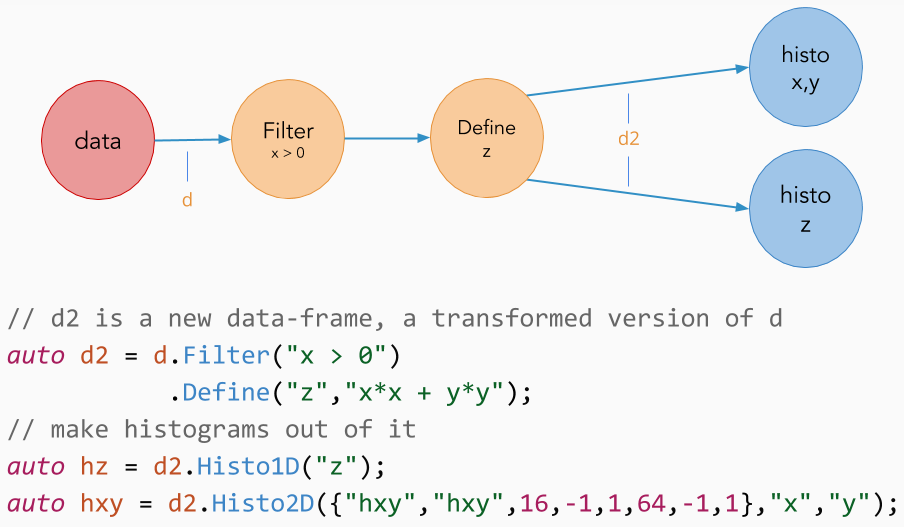
A graph composed of two branches, one starting with a filter and one with a define. The end point of a branch is always an action.
Running on a range of entries
It is sometimes necessary to limit the processing of the dataset to a range of entries. For this reason, the RDataFrame offers the concept of ranges as a node of the RDataFrame chain of transformations; this means that filters, columns and actions can be concatenated to and intermixed with Range()s. If a range is specified after a filter, the range will act exclusively on the entries passing the filter – it will not even count the other entries! The same goes for a Range() hanging from another Range(). Here are some commented examples:
d30 = d.Range(30);
d15on = d.Range(15, 0);
d15each3 = d.Range(0, 15, 3);
Note that ranges are not available when multi-threading is enabled. More information on ranges is available here.
Executing multiple actions in the same event loop
As a final example let us apply two different cuts on branch «MET» and fill two different histograms with the «pt_v» of the filtered events. By now, you should be able to easily understand what is happening:
h1 = d.Filter(«MET > 10»).Histo1D();
h2 = d.Histo1D();
void Draw(Option_t *option=»») override
Draw this histogram with options.
RDataFrame executes all above actions by running the event-loop only once. The trick is that actions are not executed at the moment they are called, but they are lazy, i.e. delayed until the moment one of their results is accessed through the smart pointer. At that time, the event loop is triggered and all results are produced simultaneously.
It is therefore good practice to declare all your transformations and actions before accessing their results, allowing RDataFrame to run the loop once and produce all results in one go.
Going parallel
Let’s say we would like to run the previous examples in parallel on several cores, dividing events fairly between cores. The only modification required to the snippets would be the addition of this line before constructing the main dataframe object:
Simple as that. More details are given below.
Root HTTP Router
The root HTTP router is a service that allows you to register routes on the root of the backend service. This is useful for things like health checks, or other routes that you want to expose on the root of the backend service. It is used as the base router that backs the httpRouter service. Most likely you won’t need to use this service directly, but rather use the httpRouter service.
Using the service
Configuring the service
There’s additional options that you can pass to configure the root HTTP Router service. These options are passed when you call createBackend.
indexPath— optional path to forward all unmatched requests to. Defaults to/api/appwhich is theapp-backendplugin responsible for serving the frontend application through the backend.configure— this is an optional function that you can use to configure theexpressinstance. This is useful if you want to add your own middleware to the root router, such as logging, or other things that you want to do before the request is handled by the backend. It’s also useful to override the order in which middleware is applied.
You can configure the root HTTP Router service by passing the options to the createBackend function.
// the built in middleware is provided through an option in the configure function
// you can add you your own middleware in here
// here the routes that are registered by other plugins
// some other middleware that comes after the other routes
Permissions
Using the service
// use the identity service to pull out the token from request headers
// ask the permissions framework what the decision is for the permission
Кластер
Active-Passive: 1 виртуальный IP.

Active-Active: 2 виртуальных IP, на входе DNS Round Robin.

Синхронизация конфигурации
Сначала нужно настроить ssh.
Синхронизация между двумя нодами, rsync работает в режиме archive и update, т. е., обновления существующих файлов.
Выдаёт статистику, которая парсится по слову transferred: и потом удаляется всё, кроме числового значения.
Помимо каталога с конфигурацией, синхронизируется каталог с сертификатами. Так как сертификаты выпускает только одна нода,
строку с переменной certs на ней нужно закомментировать. Чтобы не было ошибки при сложении в all, подставляется 0 как значение по умолчанию.
Если были скопированы какие-то файлы, HAProxy перечитывает конфигурацию.
- /scripts/sync-config.sh
rsyncConfig =rsync transferred: =rsyncConfig vmls-haproxy1:etchaproxy etchaproxy =rsyncConfig vmls-haproxy1:etcsslcertscompanyname etcsslcertscompanyname =$ + systemctl reload haproxy "HAProxy has been reloaded" " files transferred, no need to do anything"
Добавить в cron
"# Sync HAProxy config*/5 ** * *root/scripts/sync-config.sh" etccrontabMore features
Here is a list of the most important features that have been omitted in the «Crash course» for brevity. You don’t need to read all these to start using RDataFrame, but they are useful to save typing time and runtime.
Systematic variations
Starting from ROOT v6.26, RDataFrame provides a flexible syntax to define systematic variations. This is done in two steps: a) variations for one or more existing columns are registered via Vary() and b) variations of normal RDataFrame results are extracted with a call to VariationsFor(). In between these steps, no other change to the analysis code is required: the presence of systematic variations for certain columns is automatically propagated through filters, defines and actions, and RDataFrame will take these dependencies into account when producing varied results. VariationsFor() is included in header ROOT/RDFHelpers.hxx, which compiled C++ programs must include explicitly.
An example usage of Vary() and VariationsFor() in C++:
nominal_hx =
Append a filter to the call graph.
RResultMap< T > VariationsFor(RResultPtr< T > resPtr)
Produce all required systematic variations for the given result.
A list of variation «tags» is passed as last argument to Vary(): they give a name to the varied values that are returned as elements of an RVec of the appropriate type. The number of variation tags must correspond to the number of elements the RVec returned by the expression (2 in the example above: the first element will correspond to tag «down», the second to tag «up»). The full variation name will be composed of the varied column name and the variation tags (e.g. «pt:down», «pt:up» in this example). Python usage looks similar.
Note how we use the «pt» column as usual in the Filter() and Define() calls and we simply use «x» as the value to fill the resulting histogram. To produce the varied results, RDataFrame will automatically execute the Filter and Define calls for each variation and fill the histogram with values and cuts that depend on the variation.
Varying multiple columns in lockstep**
The call above will produce variations «ptAndEta:down» and «ptAndEta:up».
Combining multiple variations**
df = _df.Vary(,
nom_h = df.Histo2D(histoModel, , );
RInterface< RDFDetail::RLoopManager, DS_t > Vary(std::string_view colName, F &&expression, const ColumnNames_t &inputColumns, const std::vector< std::string > &variationTags, std::string_view variationName=»»)
Register systematic variations for an existing column.
Note how we passed the integer 2 instead of a list of variation tags to the second Vary() invocation: this is a shorthand that automatically generates tags 0 to N-1 (in this case 0 and 1).
- Note
- As of v6.26, VariationsFor() and RResultMap are in the
ROOT::RDF::Experimentalnamespace, to indicate that these interfaces might still evolve and improve based on user feedback. We expect that some aspects of the related programming model will be streamlined in future versions. - As of v6.26, the results of a Snapshot(), Report() or Display() call cannot be varied (i.e. it is not possible to call VariationsFor() on them. These limitations will be lifted in future releases.
RDataFrame objects as function arguments and return values
RDataFrame variables/nodes are relatively cheap to copy and it’s possible to both pass them to (or move them into) functions and to return them from functions. However, in general each dataframe node will have a different C++ type, which includes all available compile-time information about what that node does. One way to cope with this complication is to use template functions and/or C++14 auto return types:
< RDF>
ApplySomeFilters(RDF df)
A possibly simpler, C++11-compatible alternative is to take advantage of the fact that any dataframe node can be converted (implicitly or via an explicit cast) to the common type ROOT::RDF::RNode:
RNode MaybeAddRange(RNode df, mustAddRange)
mustAddRange ? df.Range(1) : df;
maybeRangedDF = MaybeAddRange(df, );
Storing RDataFrame objects in collections
ROOT::RDF::RNode also makes it simple to store RDataFrame nodes in collections, e.g. a std::vector<RNode> or a std::map<std::string, RNode>:
Executing callbacks every N events
It’s possible to schedule execution of arbitrary functions (callbacks) during the event loop. Callbacks can be used e.g. to inspect partial results of the analysis while the event loop is running, drawing a partially-filled histogram every time a certain number of new entries is processed, or displaying a progress bar while the event loop runs.
For example one can draw an up-to-date version of a result histogram every 100 entries like this:
h = df.Histo1D();
1-D histogram with a double per channel (see TH1 documentation)}
Callbacks are registered to a ROOT::RDF::RResultPtr and must be callables that takes a reference to the result type as argument and return nothing. RDataFrame will invoke registered callbacks passing partial action results as arguments to them (e.g. a histogram filled with a part of the selected events).
Default column lists
When constructing an RDataFrame object, it is possible to specify a default column list for your analysis, in the usual form of a list of strings representing branch/column names. The default column list will be used as a fallback whenever a list specific to the transformation/action is not present. RDataFrame will take as many of these columns as needed, ignoring trailing extra names if present.
RResultPtr< RDFDetail::MinReturnType_t< T > > Min(std::string_view columnName=»»)
Return the minimum of processed column values (lazy action).
double min(double x, double y)
Special helper columns: rdfentry_ and rdfslot_
Every instance of RDataFrame is created with two special columns called rdfentry_ and rdfslot_. The rdfentry_ column is of type ULong64_t and it holds the current entry number while rdfslot_ is an unsigned int holding the index of the current data processing slot. For backwards compatibility reasons, the names tdfentry_ and tdfslot_ are also accepted. These columns are ignored by operations such as Cache or Snapshot.
- Warning
- Note that in multi-thread event loops the values of
rdfentry_do not correspond to what would be the entry numbers of a TChain constructed over the same set of ROOT files, as the entries are processed in an unspecified order.
Just-in-time compilation: column type inference and explicit declaration of column types
C++ is a statically typed language: all types must be known at compile-time. This includes the types of the TTree branches we want to work on. For filters, defined columns and some of the actions, column types are deduced from the signature of the relevant filter function/temporary column expression/action function:
If we specify an incorrect type for one of the columns, an exception with an informative message will be thrown at runtime, when the column value is actually read from the dataset: RDataFrame detects type mismatches. The same would happen if we swapped the order of «b1» and «b2» in the column list passed to Filter().
Certain actions, on the other hand, do not take a function as argument (e.g. Histo1D()), so we cannot deduce the type of the column at compile-time. In this case RDataFrame infers the type of the column from the TTree itself. This is why we never needed to specify the column types for all actions in the above snippets.
When the column type is not a common one such as int, double, char or float it is nonetheless good practice to specify it as a template parameter to the action itself, like this:
Deducing types at runtime requires the just-in-time compilation of the relevant actions, which has a small runtime overhead, so specifying the type of the columns as template parameters to the action is good practice when performance is a goal.
When strings are passed as expressions to Filter() or Define(), fundamental types are passed as constants. This avoids certaincommon mistakes such as typing x = 0 rather than x == 0:
df.Define(, ).Filter(«x = 0»);
User-defined custom actions
Implementing custom actions with Book()
Result_t = int;
Exec( slot)
*fFinalResult = std::accumulate(fPerThreadResults.begin(), fPerThreadResults.end(), 0);
std::cout << «Number of processed entries: « << resultPtr.GetValue() << std::endl;
Smart pointer for the return type of actions.
const T & GetValue()
Get a const reference to the encapsulated object.
CPYCPPYY_EXTERN bool Exec(const std::string &cmd)
Injecting arbitrary code in the event loop with Foreach() and ForeachSlot()
sumSq = 0.;
n = 0;
std::cout << «rms of x: « << std::sqrt(sumSq / n) << std::endl;
nSlots = df.GetNSlots();
std::vector<double> sumSqs(nSlots, 0.);
std::vector<unsigned int> ns(nSlots, 0);
sumSq = std::accumulate(sumSqs.begin(), sumSqs.end(), 0.);
n = std::accumulate(ns.begin(), ns.end(), 0);
std::cout << «rms of x: « << std::sqrt(sumSq / n) << std::endl;
Notice how we created one double variable for each processing slot and later merged their results via std::accumulate.
Friend trees
Friend TTrees are supported by RDataFrame. Friend TTrees with a TTreeIndex are supported starting from ROOT v6.24.
To use friend trees in RDataFrame, it is necessary to add the friends directly to the tree and instantiate an RDataFrame with the main tree:
f = d.Filter(«myFriend.MyCol == 42»);
virtual TFriendElement * AddFriend(const char *treename, const char *filename=»»)
Add a TFriendElement to the list of friends.
Columns coming from the friend trees can be referred to by their full name, like in the example above, or the friend tree name can be omitted in case the column name is not ambiguous (e.g. «MyCol» could be used instead of «myFriend.MyCol» in the example above).
Reading data formats other than ROOT trees
RDataFrame can be interfaced with RDataSources. The ROOT::RDF::RDataSource interface defines an API that RDataFrame can use to read arbitrary columnar data formats.
RDataFrame calls into concrete RDataSource implementations to retrieve information about the data, retrieve (thread-local) readers or «cursors» for selected columns and to advance the readers to the desired data entry. Some predefined RDataSources are natively provided by ROOT such as the ROOT::RDF::RCsvDS which allows to read comma separated files:
filteredEvents =
tdf.Filter(«Q1 * Q2 == -1»)
.Define(, «sqrt(pow(E1 + E2, 2) — (pow(px1 + px2, 2) + pow(py1 + py2, 2) + pow(pz1 + pz2, 2)))»);
h = filteredEvents.Histo1D();
See also FromNumpy (Python-only), FromRNTuple(), FromArrow(), FromSqlite().
Computation graphs (storing and reusing sets of transformations)
As we saw, transformed dataframes can be stored as variables and reused multiple times to create modified versions of the dataset. This implicitly defines a computation graph in which several paths of filtering/creation of columns are executed simultaneously, and finally aggregated results are produced.
RDataFrame detects when several actions use the same filter or the same defined column, and only evaluates each filter or defined column once per event, regardless of how many times that result is used down the computation graph. Objects read from each column are built once and never copied, for maximum efficiency. When «upstream» filters are not passed, subsequent filters, temporary column expressions and actions are not evaluated, so it might be advisable to put the strictest filters first in the graph.
Visualizing the computation graph
It is possible to print the computation graph from any node to obtain a DOT (graphviz) representation either on the standard output or in a file.
Invoking the function ROOT::RDF::SaveGraph() on any node that is not the head node, the computation graph of the branch the node belongs to is printed. By using the head node, the entire computation graph is printed.
.Filter(«col0 % 1 == col0»)
count = df2.Count();
std::string SaveGraph(NodeType node)
Create a graphviz representation of the dataframe computation graph, return it as a string.
$ dot -Tpng computation_graph.dot -ocomputation_graph.png

Activating RDataFrame execution logs
ROOT::Experimental::RLogChannel & RDFLogChannel()
Informational messages; used for instance for tracing.
or in Python:
More information (e.g. start and end of each multi-thread task) is printed using ELogLevel.kDebug and even more (e.g. a full dump of the generated code that RDataFrame just-in-time-compiles) using ELogLevel.kDebug+10.
Creating an RDataFrame from a dataset specification file
RDataFrame can be created using a dataset specification JSON file:
ROOT::RDataFrame FromSpec(const std::string &jsonFile)
Factory method to create an RDataFrame from a JSON specification file.
=
=
The metadata information from the specification file can be then accessed using the DefinePerSample function. For example, to access luminosity information (stored as a double):
or sample_category information (stored as a string):
or directly the filename:
An example implementation of the «FromSpec» method is available in tutorial: df106_HiggstoFourLeptons.py, which also provides a corresponding exemplary JSON file for the dataset specification.
Scheduler
When writing plugins, you sometimes want to have things running on a schedule, or something similar to cron jobs that are distributed through instances that your backend plugin is running on. We supply a task scheduler for this purpose that is scoped per plugin so that you can create these tasks and orchestrate their execution.
Using the service
Manipulating data
Filters
RDataFrame only evaluates filters when necessary: if multiple filters are chained one after another, they are executed in order and the first one returning false causes the event to be discarded and triggers the processing of the next entry. If multiple actions or transformations depend on the same filter, that filter is not executed multiple times for each entry: after the first access it simply serves a cached result.
Named filters and cutflow reports
An optional string parameter name can be passed to the Filter() method to create a named filter. Named filters work as usual, but also keep track of how many entries they accept and reject.
Statistics are retrieved through a call to the Report() method:
- when Report() is called on the main RDataFrame object, it returns a ROOT::RDF::RResultPtr<RCutFlowReport> relative to all named filters declared up to that point
- when called on a specific node (e.g. the result of a Define() or Filter()), it returns a ROOT::RDF::RResultPtr<RCutFlowReport> relative all named filters in the section of the chain between the main RDataFrame and that node (included).
Stats are stored in the same order as named filters have been added to the graph, and refer to the latest event-loop that has been run using the relevant RDataFrame.
Ranges
When RDataFrame is not being used in a multi-thread environment (i.e. no call to EnableImplicitMT() was made), Range() transformations are available. These act very much like filters but instead of basing their decision on a filter expression, they rely on begin,end and stride parameters.
begin: initial entry number considered for this range.end: final entry number (excluded) considered for this range. 0 means that the range goes until the end of the dataset.stride: process one entry of the [begin, end) range everystrideentries. Must be strictly greater than 0.
The actual number of entries processed downstream of a Range() node will be (end - begin)/stride (or less if less entries than that are available).
Note that ranges act «locally», not based on the global entry count: Range(10,50) means «skip the first 10 entries
that reach this node*, let the next 40 entries pass, then stop processing». If a range node hangs from a filter node, and the range has a begin parameter of 10, that means the range will skip the first 10 entries that pass the preceding filter.
Ranges allow «early quitting»: if all branches of execution of a functional graph reached their end value of processed entries, the event-loop is immediately interrupted. This is useful for debugging and quick data explorations.
Custom columns
A new variable is created called name, accessible as if it was contained in the dataset from subsequent transformations/actions.
Use cases include:
- caching the results of complex calculations for easy and efficient multiple access
- extraction of quantities of interest from complex objects
- branch aliasing, i.e. changing the name of a branch
An exception is thrown if the name of the new column/branch is already in use for another branch in the TTree.
It is also possible to specify the quantity to be stored in the new temporary column as a C++ expression with the method Define(name, expression). For example this invocation
df.Define(, «sqrt(px*px + py*py)»);
Custom columns as function of slot and entry number
It is possible to create custom columns also as a function of the processing slot and entry numbers. The methods that can be invoked are:
DefineSlot(name, f, columnList). In this case the callable f has this signatureR(unsigned int, T1, T2, ...): the first parameter is the slot number which ranges from 0 to ROOT::GetThreadPoolSize() — 1.DefineSlotEntry(name, f, columnList). In this case the callable f has this signatureR(unsigned int, ULong64_t,: the first parameter is the slot number while the second one the number of the entry being processed.
T1, T2, ...)
Логи
# Дата сервер процесс[PID]: IP-адрес:порт [время запроса] фронтенд бекэнд/сервер тай/мин/ги/зап/роса код_статуса размер_запроса куки(- -) состояние_при_завершении(----) Mar 10 11:13:42 vmls-haproxy1 haproxy[919886]: 77.232.165.18:2437 [10/Mar/2022:11:13:42.511] fe_web~ be_waf/vmls-waf 0/0/0/15/15 404 399 - - ---- 219/219/83/17/0 0/0 "GET https://www.domain.ru/common/img/uploaded/articles/cdhem/6-1.jpg HTTP/2.0"
Состояние при завершении, расшифровка: https://cbonte.github.io/haproxy-dconv/2.5/configuration.html#8.5
HTTP Router Service
One of the most common services is the HTTP router service which is used to expose HTTP endpoints for other plugins to consume.
Using the service
// Registers the router at the /api/example path
Configuring the service
There’s additional configuration that you can optionally pass to setup the httpRouter core service.
getPath— Can be used to generate a path for each plugin. Currently defaults to/api/${pluginId}
Config
This service allows you to read configuration values out of your app-config YAML files.
Using the service
Configuring the service
There’s additional configuration that you can optionally pass to setup the config core service.
argv— Override the arguments that are passed to the config loader, instead of usingprocess.argvremote— Configure remote configuration loading
Efficient analysis in Python
sum = df.Filter(«x > 10»).Sum()
User code in the RDataFrame workflow
C++ code
In the simple example that was shown above, a C++ expression is passed to the Filter() operation as a string ("x > 0"), even if we call the method from Python. Indeed, under the hood, the analysis computations run in C++, while Python is just the interface language.
return x > 10;
sum = df.Filter().Sum()
sum = df.Filter().Sum()
A more thorough explanation of how to use C++ code from Python can be found in the PyROOT manual.
Python code
ROOT also offers the option to compile Python functions with fundamental types and arrays thereof using Numba. Such compiled functions can then be used in a C++ expression provided to RDataFrame.
x > 10
sum = df.Filter().Sum()
It also works with collections: RVec objects of fundamental types can be transparently converted to/from numpy arrays:
pypowarray(numpyvec, pow):
.Define(, )
Note that this functionality requires the Python packages numba and cffi to be installed.
Interoperability with NumPy
Conversion to NumPy arrays
Eventually, you probably would like to inspect the content of the RDataFrame or process the data further with Python libraries. For this purpose, we provide the AsNumpy() function, which returns the columns of your RDataFrame as a dictionary of NumPy arrays. See a simple example below or a full tutorial here.
Processing data stored in NumPy arrays
In case you have data in NumPy arrays in Python and you want to process the data with ROOT, you can easily create an RDataFrame using ROOT.RDF.FromNumpy. The factory function accepts a dictionary where the keys are the column names and the values are NumPy arrays, and returns a new RDataFrame with the provided columns.
Only arrays of fundamental types (integers and floating point values) are supported and the arrays must have the same length. Data is read directly from the arrays: no copies are performed.
df.Define(, «x + y»).Snapshot(, )
Construct histogram and profile models from a tuple
The Histo1D(), Histo2D(), Histo3D(), Profile1D() and Profile2D() methods return histograms and profiles, respectively, which can be constructed using a model argument.
In Python, we can specify the arguments for the constructor of such histogram or profile model with a Python tuple, as shown in the example below:
h = df.Histo1D((, , 64, 0., 128.), )
AsRNode helper function
The ROOT::RDF::AsRNode function casts an RDataFrame node to the generic ROOT::RDF::RNode type. From Python, it can be used to pass any RDataFrame node as an argument of a C++ function, as shown below:
df2 = df.Filter(«x > 42»)
RNode AsRNode(NodeType node)
Cast a RDataFrame node to the common type ROOT::RDF::RNode.
Definition at line 41 of file RDataFrame.hxx.
ACL
ACLs — правила доступа, кто может получать доступ.
use_backend be_example req.hdrhost dom example.com # генерация имени бэкенда из запроса с помощью карты.use_backend be_req.hdrhost,lower,mapetchaproxyhosts.map http-request redirect scheme https unless ssl_fc # именованное правилоacl is_admin_range src 10.0.48.0 http-request deny is_admin_range path_beg admin # посылать на /login, если нет клиентского сертификата или через lua.http-request redirect location unless ssl_c_used lua.is_auth_valid # не совсем acl, захват значения кол-ва запросов в логи, полезно для оценки и предварительных измерений (https://cbonte.github.io/haproxy-dconv/2.5/configuration.html#http-request%20capture).http-request capture sc_http_req_rate len
Линейные (inline) ACL состоит из действия (action), выборки (fetch) и необязательных конвертеров, флагов и т. д.
use_backend be_example req.hdrhost dom example.com
У именных (named) acl после имени идёт выборка
acl is_example req.hdrhost dom example.com use_backend be_example is_example
Выборка (fetch)
Выборка получает данные, обычно из запроса или ответа. Полученная информация может быть передана конвертеру и затем посылается на сравнение (match). Некоторые выборки принимают аргументы, например, req.hdr(host), некоторые — нет ssl_fc_session_id. Самые популярные выборки: url_param, src (IP источника), req.hdr (заголовок источника), cook (выборка по имени кук, возвращает значение), rand (случайное число), nbsrv (возвращает кол-во активных серверов на указанном бэкенде), payload (тело запроса TCP, нужно для определения протокола, сравнение).
Конвертер
Конвертеры необязательны, идут за выборкой или за предыдущим конвертером, отделяются запятыми, например
# имя хоста в нижний регистр, взять первые 5 символовreq.hdrhost,lower,bytes,Некоторые конвертеры также принимают аргументы. Популярные конвертеры: lower, bytes, hex, base64, map (лезет в карту «ключ-значение» и выдаёт значение), field (часть строки при заданном разделителе), mod (сравнение по модулю), regsub (регулярка).
Флаги
Флаги находятся между выборками/конвертерами и значениями.
use_backend be_example path beg
Часто используются: -i (нечувствительность к регистру), -m (match), -f (смотреть в acl-файл), менее популярные: -n (запрет разрешения имени в DNS), -M (читать указанный файл как карту), -u (задать acl ID).
Сравнения
Варианты сравнения: beg, end, sub, dom, len, reg, found.
use_backend be_static path reg logina-z+failed. # reg может сочетаться с -fuse_backend be_static path reg etchaproxystatic_patterns.acl # регулярные выражения ресурсоёмки, надо следить за производительностью # found - если заголовка host нет, отклонить запросhttp-request deny unless req.hdrhost found
Выборки со встроенным сравнением
Выборки со встроенным сравнением: path_beg = path -m beg, path_end, path_reg, path_sub и т. д. Не все выборки имеют такие варианты. Часто используются beg, dir, dom, end, len, reg, sub.
Сравнения с числами
Сравнения с числами — eq, ge, gt, le, lt.
http-request deny sc_http_req_rate gt # диапазон разделён двоеточием, например 10:30acl ssl req.ssl_ver :Значения
Значения должны быть статическими, т. е., не другими выборками/конвертерами/переменными.
# Строки, их может быть несколькоuse_backend be_static path_beg images icons # ip или их диапазоныhttp-request deny unless src 192.168.0.0 127.0.0.0 # Двоичные данныеuse_backend be_multiplayer payload, bin 3f021bca
Действия
Собственно, для чего и затеваются ACLs. Одно из наиболее популярных — http-request и use_backend.
http-request redirect scheme https code unless ssl_fc http-request redirect location unless req.cooksessionid found # переделать путь на лету - не редирект, т. е., клиент не узнает, что бэкенд получает другой путьhttp-request set-path legacypath req.hdrhost old.example.com # добавить заголовок из stick tablehttp-request set-header x-pages-viewed sc_gpc0_rate# использовать кэшhttp-request cache-use static path_beg static # отправлять на бэкенд be_example в соответствии с заголовком hostuse_backend be_example req.hdrhost dom www.example.com # динамически создавать имя бэкенда из заголовка в нижнем регистреuse_backend be_req.hdrhost,lower# дополнительно задействовать картуuse_backend be_req.hdrhost,lower,map_endetchaproxyhosts.map,default
Порядок срабатывания действий в соответствии с фазами соединения:
tcp-request connection (на раннем этапе полезно отшибать DoS-атаки с кучей соединений, чтобы не тратить ресурсы на их обработку)
tcp-request content (используемый протокол, режим)
http-request (например, добавить заголовки, изменить путь перед передачей запроса клиента на бэкенд)
http-response (например, добавить заголовки перед отправкой ответа бэкенда клиенту)
use_backend может быть использован на любом этапе и останавливает обработку.
tcp-request accept или http-request accept останавливают обработку на своих фазах.
Переменные
Не требуются, если только не нужно делать чего-то сложного. Некоторые случаи, когда они используются:
Пути или заголовки из запроса на этапе ответа
В выборках/lua, которые принимают значения переменных (например, concat)
Задание записи в карте с sessionid cookie на основe заголовка ответа:
http-request set-var(txn.sessionid) req.cook(sessionid) use_backend %[req.cook(sessionid),map(/etc/haproxy/sessions.map)] if { req.cook(sessionid),map(/etc/haproxy/sessions.map) -m found } http-response set-map(/etc/haproxy/sessions.map) var(txn.sessionid) res.hdr(x-sessionid-backend) if { res.hdr(x-sessionid-backend) -m found }
Как их использовать
Scope может быть txn (самый частый случай), proc, sess, req, res
Name может состоять из чисел, букв, точек и подчёркиваний.
Во всех случаях переменная будет иметь имя txn.name, никогда как просто name
Значение переменной извлекается в выборке как
var(txn.name)В LUA —
txn:set_var("txn.name","value")иtxn:get_var("txn.name")
Карты и ACL-файлы
ACL-файлы — это просто список для сравнения, а карта при совпадении значения при сравнении возвращает другое значение из второй колонки.
Все они являются файлами на диске, который читаются на этапе запуска
Все они могут быть прочитаны и изменены через runtime API:
add acl,del acl,show acladd map,del map,show map,set map
Все они могут быть изменены через модуль
lb_update(в версии enterprise)
ACL-файлы
Одна строка на образец
Может быть использован с режимами сравнения
-m beg,-m end,-m regИспользуется с помощью ключа
-fhttp-request deny path_beg admin src etchaproxyadmins.acl
Действия и ACL-файлы
http-request add-acletchaproxyblock.acl url_param src 10.0.0.0 url_paramaction add http-request add-acletchaproxyblock.acl url_param src 10.0.0.0 url_paramaction remove
Карты
Используются через «конвертер карт»
Подбирает образец, например
src,map(/etc/haproxy/ip_types.mapВозвращает результат поиска
Сравнивать можно практически любым способом — beg, dir, dom, end, len, reg, sub
Действия http-request/response содержат варианты set-map, add-map, del-map
Сопоставления имён хостов бэкендам
Хранения лимитов для ключей
")




")