

- Описание свойств
- WriteSection
- Описание методов
- EnumerateChildren()
- G2Protocol()
- ReadNextChild()
- ReadNextPacket()
- ReadPacket()
- ReadPayload()
- ResetPacket()
- WriteFinish()
- WritePacket()
- WriteToFile()
- Материал из Xgu.ru
- Отличия STP и RSTP
- Флаги в BPDU
- Роли и состояния портов
- Выбор корневого моста
- Определение корневых портов
- Определение назначенных портов
- Скачать приложение Baidu Root
- Обычные файлы и каталоги
- Особенности
- Hawman код дерева
- STP в D-Link
- Текстура Hawman
- STP в Allied Telesyn AT-8000
- Rapid PVST+ (Cisco)
- 1 Hawman
- Файлы и их индексные дескрипторы (inod)
- STP в OpenVswitch
- STP в Linux
- STP в ProCurve
- STP в Cisco
- Установка и использование
- Принцип реализации сжатия Hafman
- 4.1Что такое сжатие Habvman
- 4.2Harfman сжатияизвыполнить
Описание свойств
WriteSection
Показать файл
Открыть проект
Примеры использования класса
При создании Linux, одной из основных мыслей было то, что «Всё есть файл«. И это действительно так. Здесь вы узнаете про типы файлов в Linux.
Описание методов
EnumerateChildren()
G2Protocol()
ReadNextChild()
ReadNextPacket()
ReadPacket()
ReadPayload()
ResetPacket()
WriteFinish()
WritePacket()
WriteToFile()
С помощью этого приложения можно получить рут-права практически на любых мобильных устройствах. Оно совместимо с самыми разными смартфонами и планшетами.

Per-VLAN Spanning Tree (PVST) — проприетарный протокол компании Cisco Systems, который для каждого VLAN строит отдельное дерево. Он предполагает использование ISL для создания транков (тегированных портов) и позволяет порту быть заблокированным для одних VLAN и разблокированным для других.
Вот мы и разобрали все типы файлов, которые встречаются в Linux:
- обычные файлы (—);
- каталоги (d);
- символьные устройства (c);
- блочные устройства (b);
- сокеты (s);
- символьные ссылки (l).

Типы файлов в Linux
При создании Linux, одной из основных мыслей было то, что «Всё есть файл». И это действительно так. Здесь вы узнаете про типы файлов в Linux
- Root
- Designated
- Alternate — альтернативный путь к корневому коммутатору. Путь отличается от того, который использует корневой порт.
- Backup — запасной путь в сегмент.
- Master — provides connectivity from the Region to a CIST Root that lies outside the Region. The Bridge Port that is the CIST Root Port for the CIST Regional Root is the Master Port for all MSTIs.
Каждая MSTI работает на всех интерфейсах в регионе, независимо от того разрешен ли соответствующий VLAN на интерфейсе.
Материал из Xgu.ru
STP (Spanning Tree Protocol) — сетевой протокол (или семейство сетевых протоколов) предназначенный для автоматического удаления циклов (петель коммутации) из топологии сети на канальном уровне в Ethernet-сетях.
Первоначальный протокол STP описан в стандарте 802.1D. Позже появилось несколько новых протоколов (RSTP, MSTP, PVST, PVST+), отличающихся
некоторыми особенностями в алгоритме работы, в скорости, в отношении к VLANам и ряде других вопросов, но в целом решающих ту же задачу похожими способами. Все их принято обобщённо называть STP-протоколами.
Протокол STP в своё время был разработан мамой Интернета Радией Перлман (Radia Perlman),
а позже, в начале 90х превратился в стандарт IEEE 802.1D.
В настоящее время протокол STP (или аналогичный) поддерживается почти всеми Ethernet-коммутаторами, как реальными, так и виртуальными, за исключением самых примитивных.
- Root
- Designated
- Alternate — альтернативный путь к корневому коммутатору. Путь отличается от того, который использует корневой порт.
- Backup — запасной путь в сегмент.
- Learning
- Forwarding
- Discarding
Отличия STP и RSTP
Соответствие между состояниями портов в STP и RSTP:
Флаги в BPDU
Коммутатор устанавливает флаг proposal в RSTP BPDU для того чтобы предложить себя на роль выделенного (designated) коммутатора в сегменте.
Роль порта в proposal-сообщении всегда установлена в designated.
Коммутатор устанавливает флаг agreement в RSTP BPDU для того чтобы принять предыдущее предложение.
Роль порта в agreement-сообщении всегда установлена в root.
В RSTP нет отдельного BPDU для анонсирования изменений в топологии (topology change notification (TCN)).
Протокол использует флаг topology change (TC) для того чтобы указать на изменения.
Однако, для совместимости с коммутаторами, которые используют 802.1D, коммутаторы использующие RSTP обрабатывают и генерируют TCN BPDU.
Для взаимодействия программ друг с другом часто используются сокеты. На сокеты в выводе ls -l указывает символ «s«.
Следующий пример будет работать в Ubuntu 22.04, но чтобы выполнить его на Debian 11 вначале нужно установить программу netcat таким образом:
alex@deb:~$ su - Пароль: root@deb:~# apt install netcat root@deb:~# exit выход alex@deb:~$
Дело в том, что в Debian 11 по умолчанию немного другая версия netcat и в ней нет опции -U.
Создать сокет можно с помощью команды nc -lU socket.sock:
alex@ubuntu:~$ nc -lU socket.sock
После выполнения этой команды вы подключитесь к сокету и сможете в него что-нибудь записывать, например:
alex@ubuntu:~$ nc -lU socket.sock 123 333 123 Aaa...
Теперь подключитесь к серверу с помощью другого ssh соединения. И из нового окна терминала подключитесь к этому-же сокету:
alex@ubuntu:~$ nc -U socket.sock 123 333 123 Aaa...
Вы увидите всё то, что вводили в первом терминале.
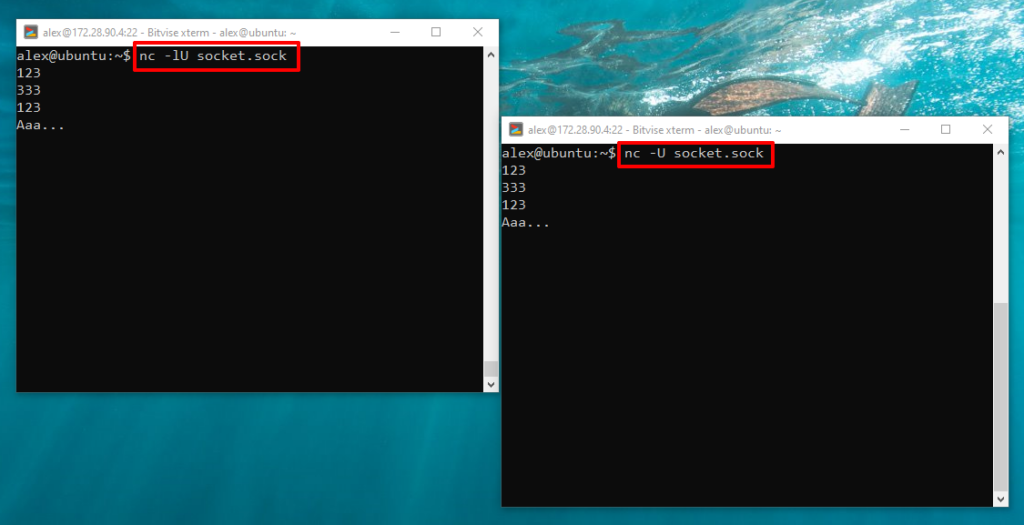
После этого на первом терминале нажмите комбинацию клавиш «Ctrl + c«, чтобы закрыть сокет. Пока не будем закрывать второй терминал, он нам ещё понадобится.
Посмотрим на файл сокета с помощью утилиты stat:
alex@ubu:~$ stat socket.sock File: socket.sock Size: 0 Blocks: 0 IO Block: 4096 socket Device: 802h/2050d Inode: 398517 Links: 1 Access: (0775/srwxrwxr-x) Uid: ( 1000/ alex) Gid: ( 1000/ alex) Access: 2022-05-16 08:50:00.897716333 +0000 Modify: 2022-05-16 08:49:21.881547299 +0000 Change: 2022-05-16 08:49:21.881547299 +0000 Birth: 2022-05-16 08:49:21.881547299 +0000
Тип файла — socket, и размер у него нулевой.
Про ссылки будет отдельная статья, но здесь разберём этот тип файлов тоже. Символьная ссылка это файл, который указывает на другой файл.
После эксперимента с сокетом, у нас в каталоге остался файл сокета. Давайте сделаем символьную ссылку на этот файл с помощью команды ln -s <путь к файлу> <имя ссылки>:
alex@ubu:~$ ln -s socket.sock ./socket.sock.link alex@ubu:~$ ls -l total 20 drwxrwxr-x 2 alex alex 20480 мая 16 08:44 dir1 srwxrwxr-x 1 alex alex 0 мая 16 08:49 socket.sock lrwxrwxrwx 1 alex alex 11 мая 16 08:51 socket.sock.link -> socket.sock
Как видите, на файл ссылки указывает символ «l«. Теперь можно ссылку использовать как файл, например можно подключиться к сокету используя ссылку. Вот для этого примера нам понадобится второе окно терминала, которое мы запускали раньше:
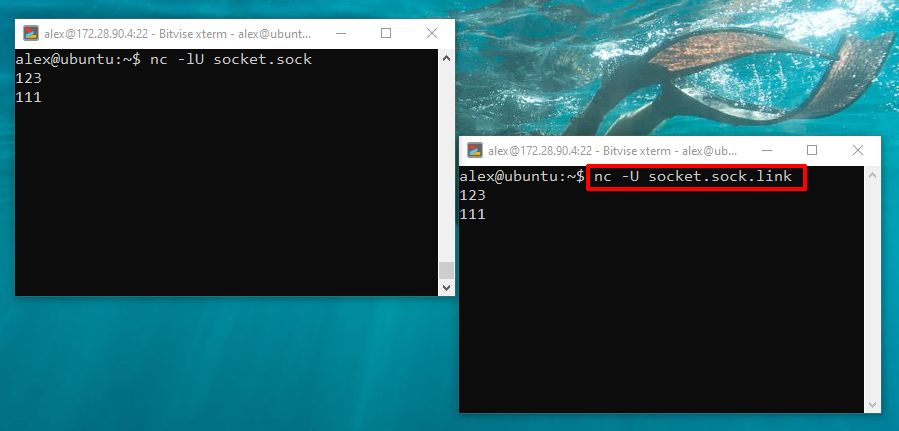
Посмотрим на символическую ссылку с помощью утилиты stat:
alex@ubu:~$ stat socket.sock.link File: socket.sock.link -> socket.sock Size: 11 Blocks: 0 IO Block: 4096 symbolic link Device: 802h/2050d Inode: 398518 Links: 1 Access: (0777/lrwxrwxrwx) Uid: ( 1000/ alex) Gid: ( 1000/ alex) Access: 2022-05-16 08:51:40.434119694 +0000 Modify: 2022-05-16 08:51:34.426096138 +0000 Change: 2022-05-16 08:51:34.426096138 +0000 Birth: 2022-05-16 08:51:34.426096138 +0000
Тип файла — symbolic link (символьная ссылка). Размер этой ссылки 11 байт. По сути, символьные ссылки это тоже самое что и ярлыки в Windows. Можно создать ссылку на любой файл или каталог.
Изменениями топологии считается изменения ролей DP и RP.
Коммутатор, который обнаружил изменения в топологии отправляет Topology Change Notification (TCN) BPDU корневому коммутатору:
- Коммутатор, на котором произошли изменения отправляет TCN BPDU через свой корневой порт. Отправка сообщения повторяется каждый hello interval (2 секунды) до тех пор пока получение сообщения не будет подтверждено.
- Следующий коммутатор, который получил TCN BPDU отправляет назад подтверждение. Подтверждение отправляется в следующем Hello BPDU, которое будет отправлять коммутатор, выставлением флага Topology Change Acknowledgement (TCA).
- Далее коммутаторы у которых порт работает в роли DP для сегмента, повторяют первые два шага и отправляют TCN через свой корневой порт и ждут подтверждения.
После того как корневой коммутатор получил TCN BPDU, он отправляет несколько следующих Hello с флагом TCA.
Эти сообщения получают все коммутаторы.
При получении сообщения hello с флагом TCA, коммутатор использует короткий таймер (Forward Delay time) для того чтобы обновить записи в таблице коммутации.
Обновления выполняется из-за того, что после изменений в топологии STP в таблице коммутации могут храниться неправильные записи.
Роли и состояния портов
- Root Port — корневой порт коммутатора
- Designated Port — назначенный порт сегмента
- Nondesignated Port — неназначенный порт сегмента
- Disabled Port — порт который находится в выключенном состоянии.
- Blocking — блокирование
- Listening — прослушивание
- Learning — обучение
- Forwarding — пересылка
Bridge Protocol Data Unit (BPDU) —
Per-VLAN Spanning Tree Plus (PVST+) — проприетарный протокол компании Cisco Systems, с функциональностью аналогичной PVST. Однако, вместо ISL он использует 802.1Q.
Различают два вида протокола PVST+:
- PVST+ — основан на протоколе STP, с некоторыми проприетарными усовершенствованиями Cisco,
- Rapid PVST+ — основан на протоколе RSTP.
Проприетарные усовершенствования Cisco:
- Backbone Fast Convergence — функция улучшает сходимость топологии spanning-tree из-за непрямых изменений топологии;
- Loop Guard — функция проверяет, что корневой порт или альтернативный корневой порт получает BPDU. Если порт не получает BPDU, то loop guard переводит порт в состояние inconsistent, изолируя таким образом проблему и позволяя топологии spanning-tree перейти в другое состояние, до тех пор пока порт не начнет опять получать BPDU;
- Portfast — функция позволяет порту пропустить состояния listening и learning и сразу же перейти в состояние forwarding. Настраивается на портах уровня доступа (там где подключены пользователи);
- Portfast BPDU Guard — функция позволяет выключать порт при получении BPDU;
- Root Guard — функция не позволяет порту стать корневым портом или заблокированным. Если порт получит BPDU от корневого коммутатора, то он перейдет в специальное заблокированное состояние, которое называется root-inconsistent;
- Uplink Fast Convergence — функция позволяет быстро переключаться на избыточный uplink, в случае, если корневой порт выключился или пересчитывается топология spanning-tree;
- Uplink Load Balancing — функция позволяет балансировать нагрузку между uplink-портами, непосредственно контролируя стоимость портов для VLAN на транковых (тегированых) портах.
Недавно я боролся с этим, приведенный ниже код — лучшее, что я мог придумать (на самом деле у меня больше ничего не получалось):
public class MultipartGenerator { //Let's assume the static members below //hold our message parts content //an the instances of arrays of byte private static final byte [] ROOT_BYTES = new byte[]{/* ... bytes ... */}; private static final byte [] ATTCH_1_BYTES = new byte[]{/* ... bytes ... */}; private static final byte [] ATTCH_2_BYTES = new byte[]{/* ... bytes ... */}; /** * Generate multipart with headers * * @return javax.mail.Multipart instance */ public static Multipart generateMultipart() { //This is our root MimeBodyPart, //content-id equals 'rootcid' //content-type equals 'roottype/rootsubtype' InternetHeaders ih0 = new InternetHeaders(); ih0.addHeader("Content-Type", "roottype/rootsubtype"); ih0.addHeader("Content-Transfer-Encoding", "binary"); ih0.addHeader("Content-ID", "rootcid"); MimeBodyPart rootBodyPart = new MimeBodyPart(ih0, ROOT_BYTES); //This is a body part wrapping first message attachment InternetHeaders ih1 = new InternetHeaders(); ih1.addHeader("Content-Type", "text/plain; name=attachment1.txt"); ih1.addHeader("Content-Transfer-Encoding", "binary"); ih1.addHeader("Content-Location", "attachment1.txt"); ih1.addHeader("Content-ID", "a00"); MimeBodyPart attch1BodyPart = new MimeBodyPart(ih1, ATTCH_1_BYTES); //This is a body part wrapping second message attachment InternetHeaders ih2 = new InternetHeaders(); ih2.addHeader("Content-Type", "text/plain; name=attachment2.txt"); ih2.addHeader("Content-Transfer-Encoding", "binary"); ih2.addHeader("Content-Location", "attachment2.txt"); ih2.addHeader("Content-ID", "a01"); MimeBodyPart attch2BodyPart = new MimeBodyPart(ih2, ATTCH_2_BYTES); //This is our desired multipart, this is where things turn a bit dirty //No success with setting the parameters in a different way Multipart multipart = new MimeMultipart("related;start=\"<rootcid>\";type=\"roottype/rootsubtype\""); multipart.addBodyPart(rootBodyPart,0); multipart.addBodyPart(attch1BodyPart); multipart.addBodyPart(attch2BodyPart); return multipart; } }Вероятно, есть лучший способ справиться с этой задачей, однако я не могу его найти.
Протокол работает на канальном уровне. STP позволяет делать топологию избыточной на физическом уровне, но при этом логически блокировать петли. Достигается это с помощью того, что STP отправляет сообщения BPDU и обнаруживает фактическую топологию сети. А затем, определяя роли коммутаторов и портов, часть портов блокирует так, чтобы в итоге получить топологию без петель.
Для того чтобы определить какие порты заблокировать, а какие будут передавать данные, STP выполняет следующее:
- Выбор корневого моста (Root Bridge)
- Определение корневых портов (Root Port)
- Определение выделенных портов (Designated Port)
Выбор корневого моста
Корневым становится коммутатор с наименьшим идентификатором моста (Bridge ID).
Только один коммутатор может быть корневым.
Для того чтобы выбрать корневой коммутатор, все коммутаторы отправляют сообщения BPDU, указывая себя в качестве корневого коммутатора.
Если коммутатор получает BPDU от коммутатора с меньшим Bridge ID, то он перестает анонсировать информацию о том, что он корневой и начинает передавать BPDU коммутатора с меньшим Bridge ID.
В итоге только один коммутатор останется корневым и будет передавать BPDU.
Изначально Bridge ID состоял из двух полей:
- Приоритет — поле, которое позволяет административно влиять на выборы корневого коммутатора. Размер — 2 байта,
- MAC-адрес — используется как уникальный идентификатор, который, в случае совпадения значений приоритетов, позволяет выбрать корневой коммутатор. Так как MAC-адреса уникальны, то и Bridge ID уникален, так что какой-то коммутатор обязательно станет корневым.
Определение корневых портов
Порт коммутатора, который имеет кратчайший путь к корневому коммутатору, называется корневым портом. У любого не корневого коммутатора может быть только один корневой порт.
Корневой порт выбирается на основе меньшего Root Path Cost — это общее значение стоимости всех линков до корневого коммутатора. Если стоимость линков до корневого коммутатора совпадает, то выбор корневого порта происходит на основе меньшего Bridge ID коммутатора. Если и Bridge ID коммутаторов до корневого коммутатора совпадает, то тогда корневой порт выбирается на основе Port ID.
Определение назначенных портов
Коммутатор в сегменте сети, имеющий наименьшее расстояние до корневого коммутатора, называется назначенным коммутатором (мостом). Порт этого коммутатора, который подключен к рассматриваемому сегменту сети называется назначенным портом.
Так же как и корневой порт выбирается на основе:
- Меньшего Root Path Cost.
- Меньшего Bridge ID.
- Меньшего Port ID.


Устройства в Linux тоже представлены файлами, для них даже выделен каталог /dev который хранит виртуальную файловую систему devfs. Эта файловая система хранит список всех устройств компьютера. Такие устройства разделяются на символьные и блочные.
Вот пример некоторых устройств.
Виртуальное устройство консоли к которой мы подключаемся /dev/tty:
alex@ubu:~$ ls -l -i /dev/tty 12 crw-rw-rw- 1 root tty 5, 0 мая 16 08:36 /dev/tty
USB устройство подключенное к USB шине:
alex@ubu:~$ ls -l -i /dev/bus/usb/001/001 144 crw-rw-r-- 1 root root 189, 0 мая 16 08:36 /dev/bus/usb/001/001
Диски и их разделы:
alex@ubu:~$ ls -l -i /dev/sd* 220 brw-rw---- 1 root disk 8, 0 мая 16 08:36 /dev/sda 268 brw-rw---- 1 root disk 8, 1 мая 16 08:36 /dev/sda1 269 brw-rw---- 1 root disk 8, 2 мая 16 08:36 /dev/sda2 270 brw-rw---- 1 root disk 8, 3 мая 16 08:36 /dev/sda3
Как видите, все эти устройства представлены файлами. На символьные устройства указывает символ «c«, а на блочные символ «b«.
Блочные устройства это диски и их разделы, raid-массивы, и тому подобное. Эти устройства могут хранить файловую систему и файлы на ней. Они умеют обрабатывать операции ввода-вывода, то-есть умеют записывать или считывать блоки данных. И обычно поддерживают произвольный доступ к данным.
Символьные устройства это COM-порты, LPT-порты, PS/2-мышки и клавиатуры, USB-мышки и клавиатуры. Такие устройства обычно поддерживают операции (read, write, open, close). И поддерживают посимвольный, то-есть последовательный доступ к данным.
Файлы устройств это не сами устройства, например файл диска будет иметь нулевой размер, хотя сам диск может хранить много данных. Файлы устройств — это интерфейсы, позволяющие системе и программам получить доступ к устройствам. Получается что файловая система devfs расположенная в каталоге /dev это как-бы API для доступа к оборудованию.
Давайте посмотрим на символьное устройство с помощью утилиты stat:
alex@ubu:~$ stat /dev/bus/usb/001/001 File: /dev/bus/usb/001/001 Size: 0 Blocks: 0 IO Block: 4096 character special file Device: 5h/5d Inode: 144 Links: 1 Device type: bd,0 Access: (0664/crw-rw-r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2022-05-16 08:36:04.872000000 +0000 Modify: 2022-05-16 08:36:04.872000000 +0000 Change: 2022-05-16 08:36:04.872000000 +0000 Birth: -
Тип этого файла character special file — символьный специальный файл.
И посмотрим на файл блочного устройства:
alex@ubu:~$ stat /dev/sda2 File: /dev/sda2 Size: 0 Blocks: 0 IO Block: 4096 block special file Device: 5h/5d Inode: 269 Links: 1 Device type: 8,2 Access: (0660/brw-rw----) Uid: ( 0/ root) Gid: ( 6/ disk) Access: 2022-05-16 08:36:10.956000000 +0000 Modify: 2022-05-16 08:36:05.296000000 +0000 Change: 2022-05-16 08:36:05.296000000 +0000 Birth: -
Кстати, команда ls -l выводит не размер файла устройства, так как размер таких файлов всегда нулевой, а мажорный и минорный номера:
alex@ubu:~$ ls -l /dev/sda2 brw-rw---- 1 root disk 8, 2 мая 16 08:36 /dev/sda2
В примере выше:
- мажорный номер — 8 — это номер драйвера, который обслуживает это устройство;
- минорный номер — 2 — это внутренний номер устройства в данной системе.
Последнее изменение файла: 2019.04.29
Скопировано с www.bog.pp.ru: 2023.07.05
Файловая система btrfs типа CoW (Copy on Write, новая версия данных записывается в свободное место)
была инициирована Oracle под GPL (после покупки Sun Microsystems у Oracle есть ZFS под CDDL).
Дано обещание не ломать (обеспечивать совместимость снизу вверх) формат хранения после ядра 2.6.31.
Основные цели — устойчивость к сбоям, выявление ошибок на диске и восстановление данных.
Максимальный размер файловой системы — 16 EiB, файла — 8 EiB (ограничивается ядром Linux), максимальное количество файлов — 2^64,
максимальная длина имени файла — 255 байт. Времена с точностью до наносекунды.
Расширенные атрибуты POSIX и ACL.
Основан на B-деревьях, адаптированных к CoW и снимкам,
которые используются для хранения объектов всех типов.
Идентификатор объекта — 64 бита, ключ — 136 бит (идентификатор, тип — 8 бит, дополнительные данные — 64 бита).
Корневое дерево (идентификатор 1) указывает на корни всех остальных деревьев (идентификаторы менее 256):
дерево файловой системы (идентификатор 5) указывает на каждый подтом (идентификаторы от 256),
дерево журналов (для ускорения fsync), дерево экстентов, дерево контрольных сумм,
дерево устройств (отображение физических адресов в логические), дерево кусков (chunk, отображение логических адресов в физические).
Для каждого файла (каталога) хранится inode (ACL и расширенные атрибуты хранятся отдельно).
Файловая система, устройства и куски имеют уникальные UUID.
Системные данные (корневое дерево, дерево устройств, дерево кусков, дерево экстентов) всегда дублируются.
Суперблок содержит физические адреса кусков, содержащих системные данные, хранятся
4 копии суперблока со смещениями 64KiB, 64MiB, 256GiB, 1PiB (при изменениях записывается номер поколения).
CoW — новые и изменённые данные записываются в свободное место, не затирая старых данных.
Каждые 30 секунд (commit) автоматически формируется новый корень файловой системы в качестве точки отката при сбоях или ошибках,
так что потеря данных не должна превышать 30 секунд (см. nobarrier ниже).
При этом текущий номер поколения (generation) увеличивается на 1.
CoW обеспечивает журналирование данных (а не только метаданных) без удвоения объёма записи
(точнее говоря атомарность транзакций по изменению данных).
Может быть отключено (рекомендуется для БД и образов виртуальных дисков — иначе они фрагментируются на миллионы кусочков)
при монтировании (nodatacow) или пофайлово («chattr +C имя-файла»).
Имеется утилита дефрагментирования в фоновом режиме (ядро 3.0).
Дефрагментирование файловой системы со снимками и reflink может умножить занятое место (до 3.9).
Нет подсчёта количества файлов (не работает «df -i») и резервирования места под inode.
Хранение данных экстентами (грануляция по умолчанию 4КиБ, максимальный размер — 128 КиБ).
Встроенная возможность делать снимки (слепки, snapshot),
в режиме только для чтения (используйте noatime!) и без ограничений
(альтернативная версия), до ? снимков. Режим может быть изменён «на ходу». Снимки не замедляют работу.
Также имеются подтома (поддеревья) с возможностью их отдельного монтирования.
Тома (снимки) образуют иерархию.
Подтом или снимок тома (или подтома) выглядит как обычный каталог в томе верхнего уровня (нельзя удалить пока не удалишь подтом или снимок).
Можно объявить корень подтома или снимка точкой монтирования по умолчанию.
При монтировании можно указать явно корень подтома или снимка корнем монтируемой файловой системы.
Перемещение с одного подтома на другой — это реальное перемещение с диска на диск, но пространство выделяется из общего пула (chunk).
Снимки разделяют используемое место для одинаковых файлов с исходным томом и другими его снимками.
Для свободной работы со снимками рекомендуется не иметь на верхнем уровне ничего, кроме каталогов подтомов и снимков,
и монтировать подтом, а не корень. Это позволит при необходимости смонтировать вместо подтома снимок, а том удалить.
Создание, хранение и проверка контрольных сумм для данных (отключаемо, для экстента и блока) и метаданных
(crc32c, зарезервировано 256 бит для метаданных и 4КиБ для данных). Правильное значение может браться из второй копии;
неправильное значение исправляется, начиная с версии ?, ранее можно было лишь скопировать и удалить файл.
Сжатие данных с помощью алгоритмов lzo и zlib (level 3), грануляция поэкстентная
(ключи монтирования или «chattr +c» перед записью), с учётом сжимаемости и без. Обещаны snappy и LZ4.
Отключается для прямого ввода/вывода (DirectIO, DIO) и NOCOW.
Сжатие производится не постранично(4 КиБ), целым экстентом (128 КиБ), чтобы прочитать байт необходимо декомпрессировать весь экстент,
а чтобы поменять байт в середине экстента, его надо переписать целиком. zlib в режиме потока с общим словарём на экстент,
lzo сжимает каждую страницу (?) отдельно.
Тестирование уровня сжатия на всём корпусе данных (16.2 TB):
- btrfs zlib-force — 2.69
- gzip -1 — 2.81
- gzip -9 — 2.92
- xz -1 — 3.35
- xz —lzma2=preset=9,dict=200MiB,nice=273 — 3.97
Фоновый процесс поблочного сканирования (только занятые блоки) и исправления ошибок (ядро 3.1).
Проверка структуры (fsck) пока в размонтированнолм состоянии (обещают в фоновом режиме).
Квотирование места, занимаемого подтомом (снимком) — не пользователем или группой пользователей. Иерархия квот.
Поддержка синхронизации с удалённым зеркалом (send, receive).
Обещана дедупликация во время записи, сейчас имеется дедупликация после записи
- duperemove: поэкстентно,
ядро 3.13 (btrfs-extent-same ioctl), попробовал в RHEL 7.0: не знаю экономится ли место,
но время модификации файлов покорёжено несмотря на режим «только чтение», как сочетать со снимками непонятно,
собрал немного статистики - bedup: пофайлово, ядро 3.3 или 3.6 для дедупликации между томами, python 2.7
и «ещё одна» система пакетирования — не стал пробовать
/sys/fs/btrfs (ядро 3.14).
Пользоваться с осторожностью — падает под большой нагрузкой (до RHEL 6.4 — совсем неживая), вывел из экспплуатации в 2015:
Ключи mkfs.btrfs (создаётся мгновенно, до RHEL 7 не проверяет, что место занято):
Опции монтирования (в качестве устройства указать одно из блочных устройств, парные опции с/без no- в ядре 3.14):
Не надо провоцировать запуск fsck в /etc/fstab, поставьте в конце строки «0 0».
Утилита btrfs позволяет манипулировать файловыми системами («btrfs help —full»)
Сборка и установка утилит btrfs 3.18.1 из исходных пакетов в CentOS 7.0:
- установить пакеты kernel-devel, libblkid-devel, libuuid-devel
- wget ftp://ftp.pbone.net/mirror/download.fedora.redhat.com/pub/fedora/linux/updates/20/SRPMS/btrfs-progs-3.18.1-1.fc20.src.rpm
- rpm -iv /tmp/btrfs-progs-3.18.1-1.fc20.src.rpm
- yum install asciidoc
- tar -xvf /root/rpmbuild/SOURCES/btrfs-progs-v3.18.1.tar.xz
- cd btrfs-progs-v3.18.1
- vim utils.c # /root/rpmbuild/SOURCES/btrfs-init-dev-list.patch
- make install
install -m755 -d /usr/local/bin install mkfs.btrfs btrfs-debug-tree btrfsck btrfs btrfs-map-logical btrfs-image btrfs-zero-log btrfs-convert btrfs-find-root btrfstune btrfs-show-super /usr/local/bin install fsck.btrfs /usr/local/bin # btrfsck is a link to btrfs in the src tree, make it so for installed file as well ln -f /usr/local/bin/btrfs /usr/local/bin/btrfsck install -m755 -d /usr/local/lib install libbtrfs.so.0.1 libbtrfs.a /usr/local/lib cp -a libbtrfs.so.0 libbtrfs.so /usr/local/lib install -m755 -d /usr/local/include/btrfs install -m644 send-stream.h send-utils.h send.h rbtree.h btrfs-list.h crc32c.h list.h kerncompat.h radix-tree.h extent-cache.h extent_io.h ioctl.h ctree.h btrfsck.h version.h /usr/local/include/btrfs
- /usr/local/bin/btrfs —version
Btrfs v3.18.1
Сборка утилит btrfs из git:
- установить пакеты kernel-devel, libblkid-devel, libuuid-devel
- git clone git://git.kernel.org/pub/scm/linux/kernel/git/mason/btrfs-progs.git
- cd btrfs-progs
- make
- make btrfs-select-super
- make btrfs-zero-log
btrfs-convert — преобразоватие файловой системы ext2/ext3/ext4 в btrfs на месте.
btrfs-debug-tree — вывод дерева метаданных на stdout («-r» выдаёт список подтомов, снимков и т.д.).
btrfs-find-root — поиск (медленно) и вывод корней деревьев (фильтр по уровню, поколению).
btrfs-image — сделать образ файловой системы с обнулёнными данными (сжать и отправить разработчикам для отладки).
btrfs-map-logical — физический адрес по логическому (для отладки).
btrfs-show-super — вывести информацию из суперблока (метка, поколение, корень, флаги, размеры блоков и т.д.).
btrfstune — поменять некоторые параметры файловой системы, опрометчиво заданные при создании.
btrfs-zero-log — очистить попорченное дерево журналов, если не получается смонтировать файловую систему (актуальность утеряна).
Тестирование btrfs с помощью bonnie++ (настольная машина, 2 диска ST1000528AS):
bonnie++ 1.03 Sequential Output Sequential Input Random -Per Chr- -Block- -Rewrite- -Per Chr- -Block- -Seeks- Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP 20000M 107510 7 52049 6 127602 10 410.9 1 ext4 над md RAID1 20000M 107218 6 51888 6 131864 11 403.7 1 ext4 над md RAID1 без битовой карты 20000M 120283 7 51758 8 125788 11 384.4 1 btrfs -d/m single над md RAID1 20000M 227244 13 83197 11 215481 12 383.0 1 btrfs -d/m raid0 над дисками 20000M 117174 7 46594 6 121916 7 374.8 1 btrfs -d/m raid1 над дисками 20000M 846256 78 222862 33 325088 19 539.8 3 btrfs -d/m raid1 над дисками, compress=lzo,space_cache
Тестирование на резервное копирование и восстановление
(на настольный комптьютер с 2 дисками ST1000528AS и сервер Intel SR2625URLX,
дисковая полка из 12 дисков ST31000340NS через FC 4Gb, большой корпус данных местного производства)
- сжатие lzo в 1.9 раза при скорости записи 227 MB/s на 2 диска ST1000528AS в raid0,
Intel Core i3 540 @ 3.07GHz, 3 потока - сжатие lzo (force) в 2.05 раза при скорости записи 219 MB/s на 2 диска ST1000528AS,
Intel Core i3 540 @ 3.07GHz, 3 потока, raid0 - сжатие zlib в 1.25 раза при скорости записи 135 MB/s на 2 диска ST1000528AS,
Intel Core i3 540 @ 3.07GHz, 3 потока, raid0,
слишком многие файлы считаются несжимаемыми - сжатие zlib (force) в 2.56 раза при скорости записи 87 MB/s на 2 диска ST1000528AS,
Intel Core i3 540 @ 3.07GHz, 3 потока, raid0,
процессор не справляется - сжатие lzo в 2.02 раза при скорости записи 354 MB/s на 12 дисков в raid0, Intel 2625UR, 3 потока,
не справляется FC - сжатие lzo в 2.04 раза при скорости записи 214 MB/s на 10 дисков в raid10, Intel 2625UR, 4 потока
- «tar -cf — .|dd of=/dev/null bs=1024k» чтение со скоростью 516 MB/s на 12 дисков в raid0, Intel 2625UR
- «tar -cf — .|dd of=/dev/null bs=1024k» чтение со скоростью 660 MB/s на 12 дисков в raid0, Intel 2625UR, 2 потока
- «tar -cf — .|dd of=/dev/null bs=1024k» чтение со скоростью 653 MB/s на 12 дисков в raid0, Intel 2625UR, 3 потока
- «tar -cf — .|dd of=/dev/null bs=1024k» чтение со скоростью 650 MB/s на 10 дисков в raid10, Intel 2625UR, 3 потока,
чтение идёт только с 5 дисков - чтение аккуратно уложенных (по очереди) 6 каталогов (по 220GB и 90 тысяч файлов) — 900 MB/s:
монтирование — «nodiratime,relatime,nobarrier,compress-force=zlib,notreelog,space_cache,thread_pool=8»;
используемое оборудование — двухсокетный сервер на Intel Xeon X5670 (загрузка CPU — 80%);
дисковая полка HP MSA 2000g2 (ограничение пропускной способности шины — 5 Gbps);
12 SATA дисков по 2 ТБ; инициализация массива в фоне
Чтение полной фаловой системы (noatime,nobarrier,compress-force=zlib,space_cache;
дисковая полка MSA 2000g2 с RAID6 из 12 дисков ST32000640NS через FC 4Gb; 16.3TB, 30 миллионов файлов):
- tar при неконтролируемом количестве потоков (при 25 потоках система захлёбывается) — 6 часов, 754 MB/s
- tar при 4 потоках (echo *|xargs —max-args=1 —max-procs=4 tardevnull.sh) — 6ч15м (727MB/s)
- tar при 6 потоках — 5ч35м (814MB/s)
- tar при 10 потоках — 5ч32м (821MB/s)
- tar при 12 потоках — 5ч58м (762MB/s)
- tracemini (подсчёт контрольных сумм md5 и сбор метаданных) при 12 потоках и буфере 1 МБ — 5ч37м (809MB/s)
- tracemini при 12 потоках и буфере 8 МБ — 5ч44м (792MB/s)
- перепроверка коллизий md5 (26% объёма) — 3ч50м
Сервер архива должен содержать данные разработчиков за значительный срок с возможностью самостоятельного извлечения
файлов по состоянию на произвольный день в прошлом. Данные разработчиков хранятся на файловых серверах
с доступом по NFS. Общий объём — 50 ТБ (более 100 миллионов файлов), ежедневные изменения — до 2ТБ.
- установка CentOS 7.1 (первая версия работает на CentOS 6.4 — при попытке перехода на CentOS 6.5 возникла проблема)
- сборка 2 массивов RAID6 по 18 дисков с помощью LSI Logic MegaRAID SAS 9266-8i с CacheVault
(контроллер не умеет делать массив из 36 дисков)# обновить прошивку контроллера и CV /opt/MegaRAID/storcli/storcli64 /c0 download file=/tmp/mr2208fw.rom /opt/MegaRAID/storcli/storcli64 /c0 download file=/tmp/TFM_70-25849-04.rom fwtype=2 # параметры контроллера /opt/MegaRAID/storcli/storcli64 /c0 set coercion=0 /opt/MegaRAID/storcli/storcli64 /c0 set patrolread=off /opt/MegaRAID/storcli/storcli64 /c0 set perfmode=1 # настройка smartd для извещения о проблемах с диском и zabbix о проблемах с массивами /opt/MegaRAID/storcli/storcli64 /c0 add vd type=raid6 size=all name=first drives=8:0-17 pdcache=off wb nora direct Strip=64 /opt/MegaRAID/storcli/storcli64 /c0 add vd type=raid6 size=all name=second drives=8:18-23,9:0-11 pdcache=off wb nora direct Strip=64
- сборка логического тома поверх 2 массивов
pvcreate /dev/sdc pvcreate /dev/sdd vgcreate x134all36 /dev/sdc /dev/sdd lvcreate --stripes 2 --stripesize 64K --name full --extents +100%FREE x134all36
- mkfs.btrfs —data single —metadata single —label time_machine —features ^extref,skinny-metadata /dev/mapper/x134all36-full
- mount -o noatime,nodiratime,compress-force=zlib,clear_cache,nospace_cache,enospc_debug /dev/mapper/x134all36-full /time_machine
- btrfs subvolume create /time_machine/current
- mkdir /time_machine/old
- /sbin/btrfs subvolume snapshot /time_machine/current /time_machine/old/`date +%Y%m%d` # по cron ежедневно в 23:59
- /time_machine/current обновляется ежедневно с помощью rsync или непрерывно
с помощью lsync
Параллельное копирование с зеркала по rsync (ssh), каждый каталог второго уровня — отдельный поток:
- обеспечение доступа ssh по ключу
mkdir .ssh chmod 700 .ssh vim .ssh/id_rsa # и сконфигурировать на той стороне /root/.ssh/id_rsa.pub chmod 600 .ssh/id_rsa
- настройка ssh-agent в .bash_profile
if [ -z "$SSH_CLIENT" -a -z "$SSH_AUTH_SOCK" ] then eval `ssh-agent` # ssh-add ~/.ssh/id_rsa # лучше добавлять вручную только тогда когда надо fi
- mkdir rsync # каталог для журналов
- bin/getdir_snapshot.sh # один каталог второго уровня
#!/bin/bash if [ -z "$1" ] then echo empty exit else DATE=`echo $1|awk -F/ '{print $1}'` DIR=`echo $1|awk -F/ '{print $2 "/" $3}'` rsync -e ssh -vas [--compress --compress-level=1] --whole-file --numeric-ids --ignore-errors --delete зеркало:/time_machine/old/$DATE/$DIR/ /time_machine/current/$DIR/ >> /root/rsync/rsync.$DATE.log 2>&1 fi - chmod u+x bin/getdir_snapshot.sh
- bin/getall_snapshot.sh # все каталоги за день
#!/bin/bash DATE=$1 ssh зеркало ls -d /time_machine/old/$DATE/*/*|awk -F/ '{print $4 "/" $5 "/" $6}' | xargs --verbose --max-args=1 --max-procs=40 getdir_snapshot.sh 2>&1 | tee -a /root/rsync/rsync.$DATE.log /sbin/btrfs subvolume snapshot /time_machine/current /time_machine/old/$DATE chmod go+rx /time_machine/old/$DATE - chmod u+x bin/getall_snapshot.sh
- создание каталогов первого уровня (отдельный каталог на каждый файловый сервер)
mkdir /time_machine/current/... ...
- запуск (под screen): getall_snapshot.sh первая-дата
- запуск в цикле копирования изменений
Копирование очередного дня с зеркала по send/receive (вдвое быстрее, данные пересылаются по сети несжатые):
btrfs property set /time_machine/old/20140801 ro true btrfs property set /time_machine/old/20140802 ro true btrfs send -v -p /time_machine/old/20140801 /time_machine/old/20140802|...
Итоги с 1 августа 2014 по 16 января 2017 + current (rsync в режиме —whole-file, иначе btrfs разваливается очень быстро):
- первый день — 11.5 TB
- всего — 104.4 TB
- в день — 103 ГБ
Тестирование чтения привычным tarnull_all_common.sh самого старого снимка (20150121) после 2.5 лет эксплуатации архива
(с диска читается до 450 МБ/сек, т.е. после декомпрессии ожидается более 1 ГБ/сек; манипуляции с настройкой контроллера и read_ahead_kb не помогают;
в начале всплеск в 1.3 GB/s; встроенный readahead насыщает систему хранения?):
- 1 поток — 23131760623616 bytes (23 TB) copied, 220811 s, 105 MB/s (screen завис)
- 6 потоков — 36682198941696 bytes (37 TB) copied, 269317 s, 136 MB/s
- 12 потоков — 36682198941696 bytes (37 TB) copied, 270545 s, 136 MB/s
- 16 потоков — 23711099912192 bytes (24 TB) copied, 164559 s, 144 MB/s
- 24 потока — 36682198941696 bytes (37 TB) copied, 269458 s, 136 MB/s
- 32 потока — 31144909209600 bytes (31 TB) copied, 220555 s, 141 MB/s
Тестирование чтения привычным tarnull_all_common.sh лизкого к текущему состоянию снимка (20170318)
после 2.5 лет эксплуатации архива (с диска читается 350 МБ/сек, т.е. после декомпрессии ожидается более 1 ГБ/сек;
манипуляции с настройкой контроллера и read_ahead_kb не помогают):
- 32 потока — 44740035739648 bytes (45 TB) copied, 360604 s, 124 MB/s (из 50ТБ)
Скачать приложение Baidu Root
- Требуется версия Android: от 2.2 до 4.4
- Возрастные ограничения: нет
- Русская локализация: частично
- Установка кэша: не требуется
Обычные файлы и каталоги
Мы уже рассматривали вывод команды ls -lh:
Тип файла | Права | | Кол-во ссылок | | | Владелец | | | | Группа | | | | | Размер | | | | | | Дата и время последнего доступа к файлу | | | | | | | Имя файла | | | | | | | | - rw-r--r-- 1 alex alex 0 ноя 26 16:17 file.txt
Если помните, первый символ указывает на тип файла. Пришло время узнать какие типы файлов бывают в Linux. А начнем мы с обычных файлов и каталогов.
На обычные файлы указывает символ тире «—«. Обычные файлы содержат какие-то данные. Это могут быть файлы изображений, сжатые файлы, текстовые файлы, файлы программ и другое.
Каталоги, это тоже файлы и на них указывает символ «d«. Они хранят некий список файлов, и это список состоит из строк, в которых записаны имена файлов и их индексные дескрипторы (inode).
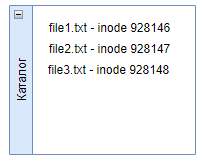
Когда мы выполняем команду ls, то мы просто читаем текущий каталог как файл и видим список файлов. Также мы можем команде ls указать конкретный каталог, который нужно прочитать. Получается что команда ls это как команда cat, но только для каталогов:
alex@ubu:~$ ls dir1 file1 alex@ubu:~$ ls /etc/ssh/ moduli sshd_config.d ssh_host_ecdsa_key.pub ssh_host_rsa_key.pub ssh_config ssh_host_dsa_key ssh_host_ed25519_key ssh_import_id ssh_config.d ssh_host_dsa_key.pub ssh_host_ed25519_key.pub sshd_config ssh_host_ecdsa_key ssh_host_rsa_key
А когда мы в каталоге создаём новый файл, то для него выделяется свободный inode, в каталоге записывается новая строчка с именем этого файла и его индексным дескриптором. Ну и конечно на диск записываются какие-то блоки данных, чтобы физически поместить файл на диск. И когда мы открываем файл, например чтобы его отредактировать, мы по inode находим где этот файл физически лежит на диске. Так каталоги помогают нам обращаться к файлам по их именам.
Раз каталог это тоже файл, то он тоже имеет свой индексный дескриптор. Вот пример просмотра каталога с помощью команды stat:
alex@ubu:~$ stat dir1 File: dir1 Size: 4096 Blocks: 8 IO Block: 4096 directory Device: 802h/2050d Inode: 398016 Links: 2 Access: (0775/drwxrwxr-x) Uid: ( 1000/ alex) Gid: ( 1000/ alex) Access: 2022-05-16 08:43:30.267484822 +0000 Modify: 2022-05-16 08:43:30.267484822 +0000 Change: 2022-05-16 08:43:30.267484822 +0000 Birth: 2022-05-16 08:43:30.267484822 +0000
Тип файла — directory (каталог). Пустой каталог сразу занимает 4096 байт. Но размер каталога не зависит от размера файлов в нем. Например, в каталоге будет 10 файлов по 1 GB, при этом размер каталога останется равным 4096 байт. Размер каталога зависит от количества файлов в нем, ведь каталог это файл содержащий список файлов и чем он больше, тем больше размер каталога.
Например, создадим в нашем каталоге 500 пустых файлов и посмотрим на сколько увеличился размер каталога:
alex@ubu:~$ touch dir1/file-{001..500}.txt
alex@ubu:~$ stat dir1/ File: dir1/ Size: 20480 Blocks: 40 IO Block: 4096 directory
Device: 802h/2050d Inode: 398016 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 1000/ alex) Gid: ( 1000/ alex)
Access: 2022-05-16 08:43:30.267484822 +0000
Modify: 2022-05-16 08:44:19.767639652 +0000
Change: 2022-05-16 08:44:19.767639652 +0000 Birth: 2022-05-16 08:43:30.267484822 +0000Как видите 500 файлов в каталоге увеличило его размер до 20480 байт.
Файлы и каталоги это самые понятные типы файлов в Linux, ниже рассмотрим более необычные типы.
Особенности
Baidu Root — это известное приложение от китайских разработчиков. Одним из главных его преимуществ является эффективное рутирование.
Практически все владельцы мобильных устройств, работающих на базе ОС Андроид, после его установки становятся суперпользователями.

Hawman код дерева
Начиная с корневой точкой Hawman дерева, выделить код «0» для левого поддерева, право ребенка дерево выделяет код «1», и достигает узел листьев, а затем достигают листы с дерева по дереву. Когда код устроен, я получаю Hawman код.
Например, строка EMCAD кодируется. Если уравнение кодируется, то:

EMCAD => 000001010011100 Итого 15 бит.

Кодирование всех букв Hufman код: emcad => 000001011011 Всего 12 цифр
STP в D-Link
create access_profile ethernet destination_mac FF-FF-FF-FF-FF-FF profile_id 4 config access_profile profile_id 4 add access_id 1 ethernet destination_mac 01-00-0C-CC-CC-CD port all deny enable cpu_interface_filtering create cpu access_profile profile_id 4 ethernet destination_mac FF-FF-FF-FF-FF-FF config cpu access_profile profile_id 4 add access_id 1 ethernet destination_mac 01-00-0C-CC-CC-CD port all deny
Текстура Hawman
Конструкция Hawman дерева выглядит следующим образом:
(2) Выбрать вес два корневых узлов , как с левым, правым к югу от дерева , чтобы построить новый bifurcous дерева, и вес корневых узлов нового bifurcus остался, справа от суммы весов корней дерева.
(3) Добавить новое бинарное дерево к F и удалять деревья, которые первоначально два веса корневого узла сведены к минимуму;
(4) Повторите (2) и (3), пока только одно дерево не входит, это дерево Hawman дерево.


STP в Allied Telesyn AT-8000
Конфигурация должна быть следующей:
—
configure mac access-list PVST deny any 01:00:0c:cc:cc:cd 00:00:00:00:00:00 permit any any exit interface range ethernet all service-acl input PVST exit exit
Rapid PVST+ (Cisco)
Rapid PVST+ в каждом VLAN строит дерево. В каждом VLAN работает RSTP.
1 Hawman
Hawman дерево также известно как лучший дерева (два-вилки), представляет собой дерево с кратчайшим путем. Алгоритм построения этого дерева был earliered Хаффманом 1952, который является полезным в поиске информации.
Длина пути между узлами: Количество ветвей между одного узла к другому узлу.
Длина пути дерева: Сумма длины пути от корня дерева к каждому узлу в дереве.

Неточечная длина ленты пути: Продукт длины пути и узел узла от этого узла к корню.
Дерево длина пути полосы: Сумма длины всех узлов листьев в дереве, помните:

WPL является наименее две вилки дерева, называется оптимальным двоичном или Hafman дерево.

Полностью бинарное дерево не обязательно оптимальное бинарное дерево.
Файлы и их индексные дескрипторы (inod)
Каждый файл содержит какие-то данные, но где храниться информация о самом файле? Такую информацию называют метаданными. Метаданные хранятся в файловых дескрипторах, которые называют inod. Разные типы файловых систем работают с метаданными по разному, например ext4 выделяет некоторое место в начале раздела для хранения индексных дескрипторов. У каждого индексного дескриптора есть свой уникальный номер.
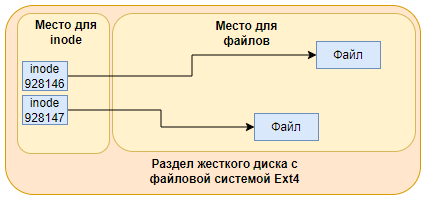
Индексный дескриптор хранит следующую информацию:
- свой номер;
- тип файла;
- владельца файла и права доступа к нему;
- время:
- создания файла (crtime);
- доступа к файлу, его ещё называют временем касания (atime);
- последнего изменения файла (mtime);
- последнего изменения метаданных файла (например изменили права доступа к файлу) (ctime:);
- физическое расположение блоков данных на диске.
Чтобы увидеть номера индексных дескрипторов к команде ls добавляют опцию -i:
alex@ubu:~$ ls -i /etc/ssh/ 928146 moduli 928421 ssh_host_dsa_key 933606 ssh_host_ed25519_key.pub 918838 ssh_config 928422 ssh_host_dsa_key.pub 918245 ssh_host_rsa_key 917921 ssh_config.d 928426 ssh_host_ecdsa_key 928420 ssh_host_rsa_key.pub 928412 sshd_config 928427 ssh_host_ecdsa_key.pub 928069 ssh_import_id 928147 sshd_config.d 928428 ssh_host_ed25519_key
В выводе возле каждого файла написан номер его индексного дескриптора.
Чтобы посмотреть некоторые метаданные файла, можете воспользоваться командой stat:
alex@ubu:~$ stat /etc/ssh/sshd_config File: /etc/ssh/sshd_config Size: 3281 Blocks: 8 IO Block: 4096 regular file Device: 802h/2050d Inode: 394570 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2022-05-16 08:36:10.592000000 +0000 Modify: 2022-05-13 13:15:09.108000000 +0000 Change: 2022-05-13 13:15:09.108000000 +0000 Birth: 2022-05-13 13:08:03.289339233 +0000
Чтобы стало понятнее я разберу некоторый вывод:
- File: /etc/ssh/ssh_config — путь к файлу и его имя;
- Size: 3281 — размер файла в байтах;
- regular file — тип файла (обычный файл);
- Inode: 394570 — номер индексного дескриптора;
- Links: 1 — количество жестких ссылок (про жёсткие и мягкие ссылки будет написана следующая статья);
- Access: (0644/-rw-r—r—) Uid: ( 0/ root) Gid: ( 0/ root) — владелец и права доступа (это тоже разберём в других статьях);
- Access: — время последнего доступа к файлу;
- Modify: — время последнего изменения файла;
- Change: — время последнего изменения метаданных файла;
- Birth: — время создания файла (Ubuntu 20.04 — не могла вывести это значение, а 22.04 уже может, как и Debian 11).
В итоге, вы должны запомнить что каждому файлу соответствует какой-то inode. Но чтобы было удобнее обращаться к файлам им ещё придумали имена. Имена файлов, кстати, не находятся в индексных дескрипторах, они находятся в каталогах. А каталоги это тоже файлы, но об этом ниже.
STP в OpenVswitch
Настроить br0 на участие в дереве 802.1D:
ovs−vsctl set Bridge br0 stp_enable=true
Установить приоритет моста равным 0x7800:
ovs−vsctl set Bridge br0 other_config:stp-priority=0x7800
Установить стоимость пути через eth0 равным 10:
ovs−vsctl set Port eth0 other_config:stp-path-cost=10
Очистить конфигурацию STP на мосту:
ovs−vsctl clear Bridge br0 stp_enable
STP в Linux
Виртуальный мост Linux (Linux Bridge) поддерживает STP.
STP в ProCurve
- Основная страница: STP в ProCurve
STP в Cisco
- Основная страница: STP в Cisco
PVST несовместим с MSTP и при одновременной работе устройств Cisco с этими протоколами вызывает проблемы в сети, в частности, отключение downlink’овского порта корневого MSTP.
Для блокировки PVST на большинстве сетевых устройств других производителей приходится создавать MAC фильтр, поскольку в их BPDU фильтрах пакеты PVST неизвестны и могут проходить через эти устройства даже при отключенных STP.
Установка и использование
В верхней части экрана гаджета будет располагаться крупная синяя кнопка. Необходимо нажать на нее и подождать в течение некоторого времени. Если вы увидите надпись, возвещающую о том, что рут получен, то, значит, все прошло успешно.

В процессе использования подобного программного обеспечения, помните о том, что оно рассчитано на взлом операционной системы устройства. Разработчики не несут никакой ответственности за последствия.
Принцип реализации сжатия Hafman
С появлением сетей и мультимедийных технологий, есть все больше и больше данных, которые требуют хранения и передачи, а объем данных увеличивается, а предыдущее ограниченная пропускная способность сети передачи данных и ограниченный носитель данных, трудно удовлетворить потребности пользователей. В частности, средства массовой информации, такие как звуки, изображения и видео все чаще подчеркивается в повседневной жизни и работы людей. Эта проблема является более серьезной и актуальной. Сегодня технология сжатия данных уже давно одним из ключевых технологий в мультимедийных областях.
4.1Что такое сжатие Habvman
Алгоритм Хаффмана поднят в начале 1950 — х годов. Это неразрушающий метод сжатия , который не теряет информационной энтропии в процессе сжатия, и алгоритм HUFFMAN может быть доказана оптимальным в алгоритмы сжатия без потерь.. Принцип Хаффман прост, это не трудно достичь, и в настоящее время программное обеспечение сжатия основной широко используется. Для приложений, важной информации и т.д., компрессия случай потери информации не допускается, а Хаффмана алгоритм очень хороший выбор.
4.2Harfman сжатияизвыполнить
Havman сжимается является алгоритм сжатия без потерь, как правило, используется для сжатия текстовых и программных файлов. Хаффман сжимаются относится к алгоритму длины кода переменной. Это означает, что отдельные символы (например, символы в текстовых файлах) заменить битовую последовательность определенной длины. Таким образом, в файле, частота высока, и используется короткая последовательность битов, а символы, которые редко появляются используются для более длинных последовательностей.
Когда мы сжимаемся, когда мы столкнулись с текстом Е, М, С, А, D и в предыдущем примере, мы не должны хранить оригинальное хранение, но конвертируются использовать свои 01 строки в ближайшее время уменьшить его. Является ли пространство занято? (Что 01 не более оригинальные персонажи? Как уменьшить его?) Каждый человек должен знать , что , когда мы храним один байтовые данные в компьютере, общей оккупации-01 бит, так как все данные на компьютере Это, наконец , преобразованное в двоичном положении. Так, думайте о нашем кодировании не только 0 и 1, так что мы можем непосредственно написать кодировку правил хранения бит компьютера и могут быть сжаты.
Давайте начнем разрабатывать собственное программное обеспечение сжатия.
Перед началом некоторых программ, вы должны принять свой собственный формат хранения файлов, а также то, что является правилом для хранения?
Ради легко, я настроил основную информацию о магазине, формат выглядит следующим образом:
1 Файл должен быть сжат один байт сканирования для сканирования файла для сжатия и вес каждого байта будет отображаться.
// Создание входного файла потока
java.io.FileInputStream fis =
// Читаем все файлы байт
2 Построить Hawman дерево:
Здесь мы используем приоритетные очереди, поскольку очереди приоритетов, скорее всего, построить конструкцию в Hafman, и форма тоже очень похожа.
* Построить Harfman дерева с использованием очереди приоритета
// очереди приоритета
PriorityQueue<hfmNode> nodeQueue =
// Добавить все узлы в очереди
// Добавить узел
// Построить дерево Harvostoman
hfmNode min1 = nodeQueue.poll();// Получить лидер команды
hfmNode min2 = nodeQueue.poll();
hfmNode result =
/ / Добавить узел слияния
// Получить корневой узел
3 Получите кодировки Hufman для каждого узла листьев:
* Получить узел листьев Habuman Code
Итак, наше дерево Hawman построен. Быть
Вот что вы можете писать непосредственно в файл в соответствии с форматом хранения файлов, который мы Prong.
4 Напишите длину каждого байта соответствующее кодирование:
/ / Записать каждую кодированную длину
Напишите кодировки, соответствующие каждому байту:
Этот шаг более сложный, потому что в Java нет бинарных данных, и мы должны преобразовать каждую 8 01 строку в байт, а затем записать байт. Однако проблема не все 01String — это целое число, кратненное 8, поэтому его необходимо пополнить после того, как строка не 8 интеграция.
// Написать строку кодировки, соответствующую каждому байту
// Записать количество символов в передаче
// Пункт I BYTES
String writes =
// передача строки
/ / Сохранить всю строку преобразованных строк
// Если ожидание официанта буфера больше 8
/ / Очистить код, который будет преобразован
// delete writes.
// Написать 8-битный байт
// получить строку для INT
// запись файла
// получить информацию кода I-байта, дождитесь написания
// Завершение строки всей интеграции целого числа 8 не хватает, чтобы дополнить целое число, множество 8, а затем записывать
/ / Очистить код, который будет преобразован
* Поверните восьмибитую строку в целое число
6 Переведите все байты в исходный файл на 01 CHAFMAN CODINGING, напишите на сжатые файлы
Этот шаг также более сложный. Принцип такой же на том же шаге. В Savecode вы найдете байт, код HAFMAN, соответствующий, недостаточно, и не достаточно, чтобы написать.
Стоит отметить, и, наконец, должен написать байт, указывающий, что сколько 0 легко удаляется при извлечении 0
// снова прочитайте информацию файла, напишите кодирование каждого байта
// Когда файл не закончен
// Если ожидание официанта буфера больше 8
/ / Очистить код, который будет преобразован
// delete writes.
// Написать 8-битный байт
// Написать в область файла
// прочитайте байт iData, напишите информацию, соответствующую кодированию
// удалить левый счет
/ / Очистить код, который будет преобразован
// Написать 0.
В результате весь процесс сжатия окончен. Быть
Если вы хотите знать, правильно ли сжатые данные, мы должны распаковать данные после сжатия, и если вы можете восстановить его, это правильно.
Unzip — это обратная работа сжатия, и я хочу реализовать сжатие, вы должны быть в состоянии добиться этого. Торопиться!
")




")