
A root is the lexical nucleus of a word bearing the major individual meaning common to a set of semantically related words, constituting one word-family, e.g. learn – learner – learned – learnable; heart, hearten, dishearten, heart-broken, hearty, kind-hearted etc. with which no grammatical properties of the word are connected. The peculiarity of English as a unique language is explained by its analytical language structure – morphemes are often homonymous with independent units (words). A morpheme that is homonymous with a word is called a root morpheme. A root is the ultimate constituent which remains after the removal of all functional and derivational affixes and does not admit any further analysis.
A stem is that part of the word that remains unchanged throughout its paradigm (formal aspect):
heart – hearts – to one’s heart’s content vs. hearty – heartier – the heartiest
It is the basic unit at the derivational level, taking the inflections that shape the word grammatically as a part of speech.
There are three types of stems: simple, derived and compound.
Simple stems are semantically non motivated and do not constitute a pattern on analogy with which new stems may be modeled: e.g. pocket, motion, receive. Simple stems are generally monomorphic and phonetically identical with the root morphemes (sell, grow, kink, etc.).
Derived stems are built on stems of various structures, they are motivated, i.e. derived stems are understood on the basis of the derivative relations between their immediate constituents and the correlated stems. Derived stems are mostly polymorphic (e.g. governments, unbelievable, etc.).
Compound stems are made up of two immediate constituents, both of which are themselves stems, e.g. match-box, pen-holder, ex-film-star, etc. It is built by joining two stems, one of which is simple, the other is derived.
The derivational types of words are classified according to the structure of their stems into simple, derived and compound words. Derived words are those composed of one root-morpheme and one or more derivational morphemes. Compound words have at least two root-morphemes, the number of derivational morphemes being insignificant.
The smallest meaningful unit in a language. A morpheme cannot be divided without altering or destroying its meaning. For example, the English word kind is a morpheme. If the d is removed, it changes to kin, which has a different meaning. Some words consist of one morpheme, e.g. kind, others of more than one. For example, the English word unkindness consists of three morphemes: the STEM1 kind, the negative prefix un-, and the noun-forming suffix -ness. Morphemes can have grammatical functions. For example, in English the –s in she talks is a grammatical morpheme which shows that the verb is the third-person singular present-tense form.
any of the different forms of a MORPHEME. For example, in English the plural morpheme is often shown in writing by adding -s to the end of a word, e.g. cat /kæt/ – cats /kæts/. Sometimes this plural morpheme is pronounced /z/, e.g. dog /díg/ – dogs /dígz/, and sometimes it is pronounced /Iz/, e.g. class /klæs/ – classes /`klæsız/. /s/, /z/, and /Iz/ all have the same grammatical function in these examples, they all show plural; they are all allomorphs of the plural morpheme.
also base form
D. base form
another term for ROOT OR STEM1.
For example, the English word helpful has the base form help.
also base form
that part of a word to which an inflectional AFFIX is or can be added. For example, in English the inflectional affix -s can be added to the stem work to form the plural works in the works of Shakespeare. The stem of a word may be:
a simple stem consisting of only one morpheme (ROOT), e.g. work
a root plus a derivational affix, e.g. work _ -er _ worker
c. two or more roots, e.g. work _ shop _ workshop.
Thus we can have work _ -s _ works, (work _ -er) _ workers, or
_ shop) _ -s _ workshops.
F. Stem versus roots
STEM and ROOT are used to refer to the ‘base’ of a word. The part to which affixes attach. The distinction between them is based on the distinction between inflectional and derivational.
Consider a word like ‘kickers’, it contains two suffixes, one derivational (-er), the other inflectional (-s). strip both affixes off and you are left with kick, which we call a ROOT. Add back on the derivational suffix –er and you get kicker, we call the STEM.

More generally, a root is any single morpheme which is not an affix. Normally, you can find a root by removing all the affixes (both derivational and inflectional) from a word. The stem of a word, on other hand, is found by removing all the inflectional affixes, but leaving any derivational affixes in place.
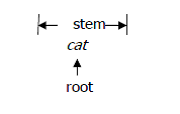
A root is always a single morpheme. A stem on the other hand, may consists of more than one morpheme. Many stems, like cat consists of only a single root. The stem and the root are identical.
other stems consists of two or more roots, as in view-point. Neither view nor point is an affix and both are single morphemes. So they are both considered to be roots.

a stem containing more than one root is called a COMPOUND STEM or simply a COMPOUND; the process of forming such stems is called COMPOUNDING.

and stem may contain more than one derivational affix, as in interlinearizer (a type of computer program that is used by linguists for inserting interlinear word-by-word or morpheme-by-morpheme glosses in a text)

thus, a stem consist of one or more roots, plus zero or more derivational affixes. A root, in contrast, is always a single morpheme.
All stems serve as the base to which inflectional affixes attach. So, for example, all the nouns mentioned above have plural forms.

virtually all roots are also stems and the simplest stems (those consisting of only one morpheme) are also roots.
Glossary of Grammatical and Rhetorical Terms
Hope is a root word.
Malte Mueller / Getty Images
In English grammar and morphology, a root is a word or word element (in other words, a morpheme) from which other words grow, usually through the addition of prefixes and suffixes. Also called a root word.
In Greek and Latin Roots (2008), T. Rasinski et al. define root as «a semantic unit. This simply means that a root is a word part that means something. It is a group of letters with meaning.»
From the Old English, «root»
Examples and Observations
- «Latin is the most common source of English root words; Greek and Old English are the two other major sources.
«Some root words are whole words and others are word parts. Some root words have become free morphemes and can be used as separate words, but others cannot. For instance, cent comes from the Latin root word centum, meaning hundred. English treats the word as a root word that can be used independently and in combination with affixes, as in century, bicentennial and centipede. The words cosmopolitan, cosmic and microcosm come from the Greek root word kosmos, meaning universe; cosmos is also an independent root word in English.» (Gail Tompkins, Rod Campbell, David Green, and Carol Smith, Literacy for the 21st Century: A Balanced Approach. Pearson Australia, 2015)
Free Morphs and Bound Morphs
- «Because a root tells us more about the meaning of a word than anything else, the first thing we ask about a complex word is often: What is its root? Often a complex word has more than one root, as in blackbird. . . .
«In our native and nativized vocabulary, roots can usually appear as independent words, for which reason they are called free morphs. This makes it particularly easy to find the roots of words like black-bird, re-fresh, and book-ish-ness. In Latin and Greek, roots most often do not occur as separate words: they are bound morphs, meaning they can only appear when tied to other components. For example, the root of concurrent is curr ‘run.’ which is not an independent word in English or even in Latin.»
(Keith Denning, Brett Kessler, and William R. Leben. English Vocabulary Elements, 2nd ed. Oxford University Press, 2007)
Roots and Lexical Categories
- «Complex words typically consist of a root morpheme and one or more affixes. The root constitutes the core of the word and carries the major component of its meaning. Roots typically belong to a lexical category, such as noun, verb, adjective, or preposition. . . . Unlike roots, affixes do not belong to a lexical category and are always bound morphemes. For example, the affix -er is a bound morpheme that combines with a verb such as teach, giving a noun with the meaning ‘one who teaches.'»
(William O’Grady, et al., Contemporary Linguistics: An Introduction, 4th ed. Bedford/St. Martin’s, 2001)
Simple and Complex Words
- «[M]orphologically simple words, which contain only a single root morpheme, may be compared to morphologically complex words which contain at least one free morpheme and any number of bound morphemes. Thus, a word like ‘desire’ may be defined as a root morpheme constituting a single word. ‘Desirable,’ by contrast, is complex, combining a root morpheme with the bound morpheme ‘-able.’ More complex again is ‘undesirability’ which comprises one root and three bound morphemes: un+desire+able+ity. Notice also how, in complex words of this sort, the spelling of the root may be altered to conform to the bound morphemes around it. Thus, ‘desire’ becomes ‘desir-‘ while ‘beauty’ will be transformed into ‘beauti-‘ in the formation of ‘beautiful’ and of the increasingly complex ‘beautician.'» (Paul Simpson, Language Through Literature: An Introduction. Routledge, 1997)
Also Known As:
Главная | Случайная страница | О проекте
Morphological structure of a word. Word-formation in Modern English
Morphological structure of a word in Modern English
The word and the morpheme
Types of morphemes
Structural types of words
Affixation as a productive way of word-formation. General characteristics of suffixes and prefixes
Productive ways of word-formation
Conversion, its definition.
Word-composition. Classification of compound words
Shortening. Types of clipping: apocope, aphaeresis, syncope. Acronyms.
Non-productive ways of word-formation.
Morphological structure of a word in Modern English
The word and the morpheme
The word is the fundamental unit of language. It is a dialectical unity of form and content. Its content or meaning is not identical to notion, but it may reflect human notions, and in this sense may be considered as the form of their existence. Concepts fixed in the meaning of words are formed as generalised and approximately correct reflections of reality, therefore in signifying them words reflect reality in their content.
The term ‘word’ denotes the basic unit of a language resulting from the association of a particular meaning with a particular group of sounds capable of a particular grammatical employment. The word is a structural and semantic entity within the language system. The term ‘vocabulary’ is used to denote the system formed by the total sum of all the words that the language possesses.
· it is easily distinguished by native speakers
· it is autonomous
· it has grammatical forms and a certain function in the sentence
· it could form a sentence
· it could be broken down into smaller parts
The term morpheme is derived from Gr morphe ‘form’ + -eme. The Greek suffix -eme has been adopted by linguists to denote the smallest significant or distinctive unit. (Cf. phoneme, sememe.) The morpheme is the smallest meaningful part of a word. A form in these cases is a recurring discrete unit of speech.
· it is not autonomous
· it can function only as a part of word
· it doesn’t posses grammatical categories or any function in the sentence
· it can’t be broken down into meaningful parts. In can be broken down only into phonemes.
Allomorphs (morphemic variants) are different phonemic shapes of the morpheme
Types of morphemes
Morphemes may be classified:
a) from the semantic point of view,
b) from the structural point of view.
a) Semantically morphemes fall into two classes: root-morphemes and non-root or affixational morphemes. Roots and affixes make two distinct classes of morphemes due to the different roles they play in word-structure.
Roots and affixational morphemes are generally easily distinguished and the difference between them is clearly felt as, e.g., in the words helpless, handy, blackness, Londoner, refill, etc.: the root-morphemes help-, hand-, black-, London-, -fill are understood as the lexical centres of the words, as the basic constituent part of a word without which the word is inconceivable.
b) Structurally morphemes fall into three types: free morphemes, bound morphemes, semi-free (semi- bound) morphemes.
A free morpheme is defined as one that coincides with the stem 2 or a word-form. A great many root-morphemes are free morphemes, for example, the root-morpheme friend — of the noun friendship is naturally qualified as a free morpheme because it coincides with one of the forms of the noun friend.
A bound morpheme occurs only as a constituent part of a word. Affixes are, naturally, bound morphemes, for they always make part of a word, e.g. the suffixes -ness, -ship, -ise (-ize), etc., the prefixes un-, dis-, de-, etc. (e.g. readiness, comradeship, to activise; unnatural, to displease, to decipher).
Many root-morphemes also belong to the class of bound morphemes which always occur in morphemic sequences, i.e. in combinations with ‘ roots or affixes. All unique roots and pseudo-roots are-bound morphemes. Such are the root-morphemes theor- in theory, theoretical, etc., barbar-in barbarism, barbarian, etc., -ceive in conceive, perceive, etc.
Semi-bound (semi-free) morphemes1 are morphemes that can function in a morphemic sequence both as an affix and as a free morpheme. For example, the morpheme well and half on the one hand occur as free morphemes that coincide with the stem and the word-form in utterances like sleep well, half an hour,” on the other hand they occur as bound morphemes in words like well-known, half-eaten, half-done.

Поиск по сайту:
MORPHOLOGICAL STRUCTURE OF ENGLISH WORDS
Words are made up of morphemes. A morpheme is the smallest meaningful unit of a word. We distinguish root morphemes and affixational morphemes. The very term “morpheme” is of the Greek origin (morphe – form). Can morphemes occur in speech as separate independent units? They can, if a word consists of a single morpheme: he can, pen, walk. But upon the whole morphemes are not autonomous. They occur in speech as consistent parts of words. Word is the basic unit of a given language. The approach to the study of the vocabulary in this country is lexicocentrical. Any word is a semantic, grammatical and phonological unit and is fully autonomous. Words are minimal free forms.
Different morphemes play different roles in constructing words. Root morphemes carry the lexical meaning of the word making it the semantic centre. Affixational morphemes fall into functional morphemes (inflexions, grammatical formants) and derivational morphemes.
Functional morphemes are dealt with in grammar and they are few in Modern English: Ns (es), Ns, Ns’, -er, -est, Vs, Ves, -ing, -ed, -t, -n (en).
Lexicology deals with derivational affixes. They may be treated from the point of view of word -building (in what way they derive new words) and from the point of view of word-structure (what role they play in the structure of the word, as a structural unit).
As far as the morphemic composition of words is concerned we distinguish monomorphemic and polymorphemic words. I, bad, tree, go – are monomorphemic words representing the root morpheme only.
Teacher, loveableness, irreproachful, bookshop – are polymorphemic words consisting of root morphemes and affix, morphemes or two root morphemes.
Structurally we distinguish free morphemes and bound morphemes. Bound morphemes function only as parts of words: — ness, -ate, -hood, de -. Bound morphemes among roots are presented by –ceive (conceive, deceive), theor- (theory, theoretical).
Infixes (n in stand) are not productive in English.
When we remove from a word all functional affixes (inflexions) we receive a stem (основа слова). The stem expresses both lexical and part-of-speech meaning. It is the part of a word which remains unchanged through its paradigm. A paradigm is a system of grammatical forms of the word.
Stems may be simple (root stems), derived (beautiful) and compound (handbag).
A stem containing one and more affixes is called a derived stem.
When we remove derivational affixes from the stem we receive the root of the word – the common element of words within a word family: hand, handy, handiwork, handicraft, handful, free-handed, red-handed, handbag, handcuffs.
The morphlogical structure of the English language is such that the majority of words are root ones. It is the influence of the analytical structure of the language.
For that reason it is difficult to say to what part of speech words belong. Word meaning can be modified by affixes (ad+fixus-L.). Affixes express lexico-grammatical meanings and serve to build new words. Prefixes modify the meaning of words while by the addition of the suffix not only the meaning is modified but the word itself is transferred to another part of speech.
cf.: honest-dishonest, carry-miscarry, archaic-pseudoarchaic, VS clever-cleverness, present-presentation, work-worker, achieve-achievable.
From the point of view of the morphological structure of English words we distinguish:
1) Simple words (root-words) where the root coincides with the stem in form;
2) Derived words (derivatives) where the meaning of the root, the lexical nucleus is modified by the potential meaning of suffixes;
3) Compound words where two or more stems are fused into semantic and structural whole.
4) Compound derivatives or derivational compounds constituted by two or more stem-morphemes (roots) modified by an affix.
Simple or root words predominate in speech communication, as we see from average talk and reading. Root words are the most frequent lexical units in English. Without special frequency counts the high frequency value of the so-called “functional words” (prepositions, articles, conjunctions, pronouns) is evident. As to the notional words 60 % of the total number of nouns and 68,7 % of the total number of adjectives used in Modern English are root words. In dictionaries, however we find 18 % of nouns and 12,4 % of adjectives.
Derived words (38 % of nouns and 12,4 % of adjectives) are, above all structural types. In dictionaries derived nouns constitute 67 % of all the nouns, 86,3 % of adjectives are derived words.
Compound words do not possess a high frequency value – 2 % of nouns and 0,21 % of adjectives. The number of compound words is steadily growing in the language. Thus, prof. Mühler states that in 1943 there were 48 compound words with “fire”, in 1960 – 61.
As all the words of the English language are divisible it is possible to carry out 3 levels of analysis of word structure.
I. Morphemic analysis states the number of morphemes in a word and their types.
Thus un-believe-bal-ness consists of 4 morphemes: one root morpheme and 3 affix morphemes.

 II. Derivational or structural word-formation analysis shows the structural correlation of the word with other words, the structural patterns or rules on which we build words. We present structurally correlative words in a set of binary oppositions. Each second element of these oppositions may be derived from the corresponding first elements; white = yellow = red
II. Derivational or structural word-formation analysis shows the structural correlation of the word with other words, the structural patterns or rules on which we build words. We present structurally correlative words in a set of binary oppositions. Each second element of these oppositions may be derived from the corresponding first elements; white = yellow = red
whitish = yellowish = reddish
We may observe from proportional oppositions that ish is their distinctive feature. Any other word built according to this pattern contains this component common to the whole group.
III. Analysis into Immediate Constituents.
Immediate Constituents are any of the two meaningful parts forming a larger linguistic unity. Any word (not a simple one) is characterized by morphological divisibility. The analysis into IC reveals the history of the word and its motivation (we play back the process of its construction). Let’s take, for example, remacadamized (road). The analysis is binary and at each stage we may split the word into 2 constituent parts only:
I. remacadamize + ed II. re + macadamize
or re+macadamized macadamize + ed
macadam + ize
Breaking the word into ICs we observe in each cut the structural order of its constituents.
Finally the Ultimate Constituents will look this way:
re + macadam + ize + ed.
If the analysis is carried out correctly its results will coincide with the result of morphemic analysis.
Root morphemes carry the lexical meaning of the word. Affixational morphemes fall into derivational morphemes, which carry the lexico-grammatical meaning and serve to form new words, and functional morphemes having grammatical meaning (inflexions). Lexicology deals only with roots and derivational affixes, while inflexions are studied by grammar. Root and derivational morphemes constitute the stem of the word.
Roots are usually free morphemes: they often coincide with independently functioning words: pen, walk, good. Some roots may be bound as well: they may not coincide with separate word-forms as in poss ible, for ty. All affixes are bound morphem-es. There are also semi-affixes which stand between roots and derivational morphemes: fire proof, water proof, kiss proof, lady like, business like, star like, etc.; -worthy, -man, -ful, etc.).
As far as the morphemic composition of words is concerned, words are classified into monomorphic and polymorphic. Monomorphic words consist of one morpheme – the root morpheme only. These words are called simple: dog, cat, boy, girl, etc. Polymorphic words consist of a root and one or several affixes or of two or several root morphemes. Accordingly, polymorphic words fall into three subgroups:
1) derived words, which contain a root and one or several affixes: hardship, unbelievable.
2) compound words, which consist of at least two root morphemes: handbag, merry-go-round.
3) compound derivatives, or derivational compounds, which are constituted by two or more roots modified by an affix: old-maidish, long-nosed.
Simple words are the most frequent lexical units in English. The most widely used words, such as pronouns, prepositions, conjunctions, articles, are simple words. The least frequent in usage are compound words, though their number is steadily growing.
Some words that were compound in Old English are known as simple words in Modern English: woman – OE wif+man, window – OE wind+eage, etc. This process is named the simplification of the stem (опрощение морфологической структуры слова).
There are three levels of analysis of the morphological structure of the word.
1. Morphemic analysis, which states the number of morphemes in a word and their types. At this level, the word friendliness, for instance, is characterized as a word containing three morphemes: one root morpheme (friend) and two derivational morphemes (ly, ness).
2. Derivational analysis, which reveals the pattern according to which the word is built. Thus, the word friendliness is built by adding to the stem friendly the suffix ness (not friend + liness as there is no suffix liness in English). Derivational analysis shows the structural correlation of the word with other words: friendly vs friendliness = happy vs happiness = easy vs easiness, etc.
3. Analysis into Immediate Constituents (непосредственные составляющие), which reveals the history of the word, the stages of the process of its formation. The analysis is binary: at each stage we split the word into two constituents. Thus, the word friendliness is first divided into friendly and ness, then the part friendly is further subdivided into friend and ly. So, the Ultimate Constituents (конечные составляющие) look this way: friend+ly+ness. The results of the analysis coincide with the result of the morphemic analysis of the same word.
The most productive ways of word-building in Modern English are:
The types of word-building that are less productive are sound imitation and reduplication.
The ways of word-formation that are non-productive are sound and stress interchange.
Affixation is building new words by adding affixes to the stem of the word. The two main types of affixation are prefixation and suffixation.
Affixes can be classified according to different principles.
According to the part of speech formed affixes (suffixes, to be exact) are divided into noun-forming (-er, -ness, -ship, -hood, -ance, -ist, etc.), adjective-forming (-ful, -less, -ic, — al, -able, -ate, -ish, -ous, etc.), verb-forming (-en, -ate, -fy, — ize, etc.), adverb-forming (-ly, -wide, etc.).
According to their origin affixes are classified into native and borrowed. The native suffixes are -er, -ed, -dom, -en, -ful, -less, -hood, -let, -ly, -ness, -ship, -some, -teen, -th, -y, ward, -wise, -lock. Prefixes: un-, mis-, up-, under-, over-, out-.
Borrowed affixes are by their origin Latin (-or, -ant, -able), French (-ard, -ance, -ate), or Greek (-ist, -ism, -oid). There exist numerous prefixes of Latin and Greek origin used to form new words in English: anti-, contra-, sub-, super-, post-, vice-, etc.
According to their productivity (the ability to form new words) affixes may be divided into productive (- er, -ish, -less, etc.) and non-productive (- ard, -ive, -th, -ous, fore-, etc.). Productive affixes are always frequent, but not every frequent affix is productive (- ous, for example, is a very frequent affix as it is found in many words, but it is not productive).
According to their connotational characteristics affixes may be emotionally coloured (stink ard, drunk ard, gang ster, young ster, etc. – derogatory emotional charge) and neutral (-er, able, -ing); stylistically marked (ultra-, -oid, -eme, -tron, etc. – bookish) and neutral (-er, able, -ing).
The semantic relations between the members of converted pairs are various.
Composition consists in making new words by combining two or more stems which occur in the language as free forms. It is most characteristic of adjectives and nouns. Compound words may be divided into several groups.
According to the type of composition compounds are divided into those formed by juxtaposition without linking elements (skyblue), into compounds with a linking vowel or consonant (Anglo-saxon, saleswoman) and compounds with a linking element represented by a preposition or conjunction (up-to-date, bread-and-butter). Compounds may also be formed by lexicalized phrases: forget-me-not, stick-in-the-mud (отсталый, безынициативный). Such words are called syntactic compounds. There also exist derivational compounds (compound derivatives) which represent the structural integrity of two free stems with a suffix referring to the combination as a whole: honey-mooner, teen-ager, kind-hearted.
According to the structure of their ICs compounds are classified into those containing:
1) two simple stems: pen-knife, bookcase;
2) one derived stem: chainsmoker, cinema-going;
3) one clipped stem: B-girl, H-bomb;
4) one compound stem: wastepaper-basket.
There is a problem of differentiation of compounds and homonymous word combinations. There are five criteria which help to solve this problem:
1) graphical criterion: the majority of English words are spelled either solidly or are hyphenated;
2) phonological criterion: compounds usually have a heavy stress on the first syllable (cf.: ` blackbird vs ` black ` bird);
3) semantic criterion: the meaning of a compound word is not a total sum of the meanings of its components but something different. There are compound words the semantic motivation of which is quite clear (table-cloth, shipwreck, etc.), but many compounds are idiomatic (non-motivated): butterfinger (a person who can’t do things well), blue-stocking (a pedantic woman);
4) morphological criterion (criterion of formal integrity (A. I. Smirnitsky)): a compound word has a paradigm of its own: inflexions are added not to each component but to the whole compound (handbags, handbag’s)
5) syntactic criterion: the whole compound but not its components fulfils a certain syntactic function. Nothing can be inserted between the components of a compound word.
It should be noted that a single criterion is not sufficient to state whether we deal with a compound word or a combination of words.
More than ⅓ of neologisms in English are compound words, so it’s a highly productive way of word-building.
Shortening (Clipping or Curtailment) is building new words by subtraction (отнятие, удаление) of a part of the original word. Shortenings are produced in two main ways: a) by clipping some part of the word; b) by making a new word from the initial letters of a word group.
According to the position of the omitted part, shortenings are classified into those formed by:
According to their reading, initial shortenings, or abbreviations are classified into:
1) abbreviations which are pronounced as a series of letters: FBI, CIA, NBA (National Basketball Association), etc.
2) abbreviations which are read as ordinary English words (acronyms): UNO, NATO, radar (radio detection and ranging), etc.
A special group is represented by graphical abbreviations used in written speech: N.Y., X-mas, PhD, etc. A number of Latin abbreviations are used in writing: e.g., p.m., i.e., P.S., etc.
The minor ways of word-building are blending, sound imitation, reduplication and ellipsis.
Blending is a way bulding words by merging parts of words (not morphemes) into one new word. Thus, the noun smog is composed of the parts of the nouns smoke and fog, the noun brunch – of breakfast and lunch, motel – of motor and hotel. Such words are called blends (сращения), fusions, telescope words.
Reduplication (Repetition) consists in a complete or partial repetition of the stem or of the whole word (bye-bye), often with a variation of the root vowel or consonant (ping-pong
These words are always colloqual or slang, among them there many nursery words. There exist three types of such words: 1) the words in which the same stem is repeated without any changes (pretty-pretty, goody-goody, never-never (утопия); 2) words with a vowel variation (chit-chat (сплетни), ping-pong, tip-top); 3) words with pseudomorphemes (rhyme combinations) (lovey-dovey, walkie-talkie, willy-nilly); the parts of such words don’t exist as separate words.
Non-productive ways of word-building are sound interchange and distinctive stress which are regarded as a means of word-building only diachronically because in Mod. English not a single word is formed by changing the root sound or by shifting the place of stress.
Distinctive stress is found in groups like `present – pres`ent, `conduct – con`duct, `abstract – abstr’act, etc. These words were French borrowings with the original stress on the last syllable. Verbs retained it, while in nouns and adjectives it was shifted. The place of stress helps to distinguish verbs and nouns or pronouns in speech
The morphological structure of the word. Morphemes and allomorphs. The morphological meaning of the word.
Word is the principal and basic unit of the language system, the largest on the morphologic and the smallest on the syntactic plane of linguistic analysis.
The term morpheme is derived from Greek morphe “form ”+ -eme. The Greek suffix –eme has been adopted by linguistic to denote the smallest unit or the minimum distinctive feature.
The morpheme is the smallest meaningful unit; it cannot be divided into smaller meaningful units. A form in these cases a recurring discrete unit of speech. Morphemes occur in speech only as constituent parts of words, not independently, although a word may consist of single morpheme.
Allomorphes are the phonemic variants of the given morpheme. The meaning remains the same, the sound can vary. e.g. il-, im-, ir-, are the allomorphes of the prefix in- (illiterate, important, irregular, inconstant).
According to the number of morphemes words are classified into:
1. monomorphic (root-words) consist of only one root-morpheme
e.g. small, dog, make
2. polymorphic are classified according to the number of root-morphemes into:
a. monoradical (one-root words):
1) radical –suffixal(корень-суффикс) (consist of one root-morpheme and one or more suffixal morphemes)
e.g. acceptable, acceptability, blackish, etc.
2) radical-prefixal (consist of one root-morpheme and a prefixal morpheme)
e.g. outdo, rearrange, unbutton, etc.
3) prefixo-radical-suffixal (consist of one root, a prefixal and suffixal morphemes)
e.g. disagreeable, misinterpretation, etc.
Derived words are composed of one root-morpheme and one or more derivational morphemes.
b. Polyradical (words which consist of two or more roots):
1) polyradical words which consist of two or more roots with no affixational morphemes
e.g. book-stand, eye-ball, lamp-shade, etc.
2) words which contain at least two roots and one or more affixational morphemes
e.g. safety-pin, wedding-pie, class-consciousness
Compound words are those which contain at least two root-morphemes, the number of derivational morphemes being insignificant.
There can be both root- and derivational morphemes in compounds as in pen-holder, light-mindedness, or only root-morphemes as in lamp-shade, eye-ball, etc.
Types of morphological mgs:
1. lexical – it’s defined in the dictionary
2. p-of-sp – typical affixes, not roots. – er shoulder-surfer – подглядывающий номер телефона.
3. differential – to distinguish one word from another: re-do, over-do
4. distributional – shows the arrangement of morphemes in a word: skylight – light sky.
3. The main principles of morphemic analysis.Classification of morphemes.
The morphemic analysis may be carried out on the basis of two principles:
1. the root principle -the segmentation of the word into its constituent morphemes is based on the identificatio n of a root- morpheme within a set of words
e.g. the identification of the root-morpheme agree in the words agreeable, agreement, disagree makes it possible to split these words into the root agree and the affixational morphemes -able, -ment, dis-.
2. the affix principle — the segmentation of the word into its constituent morphemes is based on the identification of an affixational morpheme within a set of words.
e.g. the identification of the suffixational morpheme -less leads to the segmentation of words like useless, hopeless, merciless, etc., into the suffixational morpheme -less and the root-morphemes within a word-cluster.
As a rule, the application of one of these principles is sufficient for the morphemic segmentation of words.
Classification of morphemes.
I. Morphemes may be classified:
a) from the semantic point of view
b) from the structural point of view
Semantically morphemes fall into two classes:
2. non-root or affixational morphemes.
Roots and affixes make two distinct classes of morphemes due to the different roles they play in word-structure.
1. inflectional morphemes or inflections
— carry only grammatical meaning
— relevant only for the formation of word-forms
2. affixational morphemes or affixes
— relevant for building various types of stems (the part of a word that remains unchanged throughout its paradigm)
Lexicology is concerned only with affixational morphemes.
1. prefixes (precedes the root-morpheme)
Structurally morphemes fall into:
1. free morphemes (coincide with the stem or a word-form)
e.g. friend coincides with one of the forms of the noun friend
2. bound morphemes (occur only as a constituent part of a word)
e.g. affixes, prefixes, cranberry morphemes, the morphemes tele-, graph-, scope-, micro-, phone- (of Latin or Greek origin)
3. semi-free (semi -bound) morphemes (can function both as an affix and as a free morpheme).
e.g. well and half occur as free morphemes (sleep well, half an hour) and as bound morphemes (well-known, half-eaten), the morpheme -man as the last component may be qualified as semi-free (postman, gentleman)
II. On the level of morphemic analysis linguists operate with two types of morphemes:
2. pseudo (quasi-)/ cranberry morphemes:
A cranberry morpheme cannot be assigned a meaning nor a grammatical function, but nonetheless serves to distinguish one word from the other.
· mit in permit, commit, and submit
· ceive in receive, perceive, and conceive
· twi in twilight
· spick and span in spick-and-span
· fro in to and fro
· Inflectional morphemes modify a word’s tense, number, aspect, and so on (-s, -ed, -ing).
· Derivational morphemes can be added to a word to create (derive) another word.
4. Procedure of morphemic analysis. Morphemic types of words.
All English words fall into 2 large classes:
1. segmentable, those allowing of segmentation into morphemes
The aim of the morph analysis is to state the number & type of morphemes that make up a w.
The morphemic analysis deals with segmentable words. It aims at splitting a segemetable word into its constituent morphemes and at determining their number and types. The method of Immediate and Ultimate Constituents — the procedure employed for the purposes of segmenting words into the constituent morphemes.
This method is based on a binary principle, i.e. each stage of the procedure involves two components the word immediately breaks into. At each stage these two components are referred to as the Immediate Constituents (ICs). Each IC at the next stage of analysis is in turn broken into two smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes. In terms of the method employed these are referred to as the Ultimate Constituents (UCs). For example the noun friendliness is first segmented into the IC friendly recurring in the adjectives friendly-looking and friendly and the -ness found in a countless number of nouns, such as happiness, darkness, unselfishness, etc. The IC -ness is at the same time a UC of the noun, as it cannot be broken into any smaller elements possessing both sound-form and meaning. The IC friendly is next broken into the ICs friend- and -ly recurring in friendship, unfriendly, etc. on the one hand, and wifely, brotherly, etc., on the other. Needless to say that the ICs friend- and -ly are both UCs of the word under analysis.
The procedure of segmenting a word into its Ultimate Constituent morphemes, may be conveniently presented with the help of a box-like diagram
In the diagram showing the segmentation of the noun friendliness the lower layer contains the ICs resulting from the first cut, the upper one those from the second, the shaded boxes representing the ICs which are at the same time the UCs of the noun.
The morphemic analysis according to the IC and UC may be carried out on the basis of two principles: the so-called root principle and the affix principle. According to the affix principle the segmentation of the word into its constituent morphemes is based on the identification of an affixational morpheme within a set of words; for example, the identification of the suffixational morpheme -less leads to the segmentation of words like useless, hopeless, merciless, etc., into the suffixational morpheme -less and the root-morphemes within a word-cluster; the identification of the root-morpheme agree- in the words agreeable, agreement, disagree makes it possible to split these words into the root -agree- and the affixational morphemes -able, -ment, dis-. As a rule, the application of one of these principles is sufficient for the morphemic segmentation of words.
According to the number of morphemes words are classified into monomorphic and polymorphic.
Monomorphiс or root-words consist of only one root-morpheme, e.g. small, dog, make, give, etc. All pоlуmоrphiс words according to the number of root-morphemes are classified into two subgroups: monoradical (or one-root words) and polyradical words, i.e. words which consist of two or more roots. Monoradical words fall into two subtypes: 1) radical-suffixal words, i.e. words that consist of one root-morpheme and one or more suffixal morphemes, e.g. acceptable, acceptability, blackish, etc.; 2)radical-prefixal words, i.e. words that consist of one root-morpheme and a prefixal morpheme, e.g. outdo, rearrange, unbutton, etc. and 3) prefixo-radical-suffixal, i.e. words which consist of one root, a prefixal and suffixal morphemes, e.g. disagreeable, misinterpretation, etc.
Polyradical words fall into two types: 1) polyradical words which consist of two or more roots with no affixational morphemes, e.g. book-stand, eye-ball, lamp-shade, etc. and 2) words which contain at least two roots and one or more affixational morphemes, e.g. safety-pin, wedding-pie, class-consciousness, light-mindedness, pen-holder, etc.
5. The main aim,principles and methods of derivational analysis.
Derivational level of analysis aims at finding out the derivative types of ws, the interrels ↔ them & at finding out how dif types of derivatives are constructed. Der analysis enables one to understand how new ws appear in the lang.
The derivational level of analysis study the derivative & the derivative rels.
Using der analysis we can determine the degree of derivation. The degree shows us the number of der steps. Unthinkable = ⌐ + Ba II step
Bv + ^ I step
Der Mng-mng which establishes semantic correlation between a simple wr and a derived one. (suff; conversion) (eatable)
The analysis of the morphemic composition of words defines the ultimate meaningful constituents (UCs), their typical sequence and arrangement, but it does not reveal the hierarchy of morphemes making up the word, neither does it reveal the way a word is constructed, nor how a new word of similar structure should be understood. The morphemic analysis does not aim at finding out the nature and arrangement of ICs which underlie the structural and the semantic type of the word, e.g. words unmanly and discouragement morphemically are referred to the same type as both are segmented into three UCs representing one root, one prefixational and one suffixational morpheme. However the arrangement and the nature of ICs and hence the relationship of morphemes in these words is different — in unmanly the prefixational morpheme makes one of the ICs, the other IC is represented by a sequence of the root and the suffixational morpheme and thus the meaning of the word is derived from the relations between the ICs un- and manly- (‘not manly’), whereas discouragement rests on the relations of the IC discourage- made up by the combination of the. prefixational and the root-morphemes and the suffixational morpheme -ment for its second IC (’smth that discourages’). Hence we may infer that these three-morpheme words should be referred to different derivational types: unmanly to a prefixational and discouragement to a suffixational derivative.
The nature, type and arrangement of the ICs of the word is known as its derivative structure. Though the derivative structure of the word is closely connected with its morphemic or morphological structure and often coincides with it, it differs from it in principle.
 According to the derivative structure all words fall into two big classes: simplexes or simple, non-derived words and complexes or derivatives. Simplexes are words which derivationally cannot’ be segmented into ICs. The morphological stem of simple words, i.e. the part of the word which takes on the system of grammatical inflections is semantically non-motivated l and independent of other words, e.g. hand, come, blue, etc. Morphemically it may be monomorphic in which case its stem coincides with the free root-morpheme as in, e.g., hand, come, blue, etc. or polymorphic in which case it is a sequence of bound morphemes as in, e.g., anxious, theory, public, etc.
According to the derivative structure all words fall into two big classes: simplexes or simple, non-derived words and complexes or derivatives. Simplexes are words which derivationally cannot’ be segmented into ICs. The morphological stem of simple words, i.e. the part of the word which takes on the system of grammatical inflections is semantically non-motivated l and independent of other words, e.g. hand, come, blue, etc. Morphemically it may be monomorphic in which case its stem coincides with the free root-morpheme as in, e.g., hand, come, blue, etc. or polymorphic in which case it is a sequence of bound morphemes as in, e.g., anxious, theory, public, etc.
The basic elementary units of the derivative structure of words are: derivational bases, derivational affixes and derivational patterns which differ from the units of the morphemic structure of words (different types of morphemes). The relations between words with a common root but of different derivative structure are known as derivative relations. The derivative and derivative relations make the subject of study at the derivational level of analysis; it aims at establishing correlations between different types of words, the structural and semantic patterns
words are built on, the study also enables one to understand how new words appear in the language.
The main units of derivational analysis. Derivational patterns
The derivational level of analysis aims at establishing correlations between different types of words, the structural and semantic patterns words are built on, the study also enables one to understand how new words appear in the language.
The nature, type and arrangement of the ICs of the word are known as its derivative structure.
Though the derivative structure of the word is closely connected with its morphemic or morphological structure and often coincides with it, it differs from it in principle.
The basic units of the derivational analysis are:
A derivational base — the constituent to which a rule of word-formation is applied. It is the part of the word which establishes connection with the lexical unit that motivates its individual lexical meaning describing the difference between words in one and the same derivative set.
Structurally derivational bases fall into 3 classes:
1) bases that coincide with morphological stems of different degrees of complexity (ex-filmstar);
2) bases that coincide with word-forms (unsmiling, unknown). This base is usually ‘constituted by verbal forms
3) bases that coincide with word-groups of different degrees of stability (blue-eyed, good-for-nothing).
1. Bases of the first class are functionally and semantically distinct from all kinds of stems.
The morphological stem:
— Functionally: the part of the word which is the starting point for its forms
— Semantically: represents all the lexical meanings of a word.
A derivational base
— Functionally: the starting-point for different words
— Semantically: represents only 1 meaning of the source word or its stem.
e.g. The derivatives glassful and glassy are built on different derivational bases.
Glassful is motivated by the derivational base meaning ‘a container used for drinking’ and glassy by the derivational base meaning ‘a transparent solid substance’, though both represent the same morphological stem of the word glass.
2) The second class of DB is made up of word-forms. This class of bases is confined to verbal word-forms – the present and the past participles – which regularly function as ICs of non-simple adjectives, adverbs and nouns
e.g. unknown, dancing-girl
3) The third class of DB is made up of word groups. Free word-groups make up the greater part of this class of bases. Bases of this class allow of a rather limited range of collocability, they are most active with derivational affixes in the class of adjectives and nouns (long-fingered, blue-eyed).
2. functional (serve to convey grammatical meaning)
Lexicology is primarily concerned with DAs.
DA – an IC that is added to a DB and that has lexical and part-of-speech meanings.
FAs can be appended, with a few exceptions, to any element belonging to the part of speech they serve.
With DAs is much more intricate. DAs don’t combine so freely and regularly. DAs are attached to DB in a haphazard and unpredictable way.
e.g. lioness, tigress, but she-wolf, she-elephant, she-bear
e.g. Muscovite, Londoner, Viennese, Athenian
A derivational pattern is a regular meaningful arrangement, a structure that imposes rigid rules on the order and the nature of the derivational bases and affixes that may be brought together to make up a word. A DP is a generalization, a sсheme according to which the type of ICs, their order and arrangement are chosen.
There are two types of DBs:
1. Structural (specify base classes and individual affixes)
2. Structural-semantic (specify semantic peculiarities of bases and the individual mg of the affix).
e.g. gentlemanly vs monthly
A derivational pattern is a regular meaningful arrangement, a structure that imposes rigid rules on the order and the nature of the derivational bases and affixes that may be brought together to make up a word. A DP is a generalization, a sheme according to which the type of ICs, their order and arrangement are chosen.
There are two types of DPs:
1. Structural (specify base classes and individual affixes)
2. Structural-semantic (specify semantic peculiarities of bases and the individual mg of the affix).
e.g. gentlemanly vs monthly
2 of 2 quotes
‘Root’, ‘stem’ and ‘base’ are all terms used in the literature to designate that part of a word that remains when all affixes have been removed.
A root is a form which is not further analysable, either in terms of derivational or inflectional morphology. It is that part of word-form that remains when all inflectional and derivational affixes have been removed. A root is the basic part always present in a lexeme. In the form ‘untouchables’ the root is ‘touch’, to which first the suffix ‘-able’, then the prefix ‘un-‘ and finally the suffix ‘-s’ have been added. In a compound word like ‘wheelchair’ there are two roots, ‘wheel’ and ‘chair’.
A stem is of concern only when dealing with inflectional morphology.
In the form ‘untouchables’ the stem is ‘untouchable’, although in the form ‘touched’ the stem is ‘touch’; in the form ‘wheelchairs’ the stem is ‘wheelchair’, even though the stem contains two roots.
A base is any form to which affixes of any kind can be added. This means that any root or any stem can be termed a base, but the set of bases is not exhausted by the union of the set of roots and the set of stems: a derivationally analysable form to which derivational affixes are added can only be referred to as a base. That is, ‘touchable’ can act as a base for prefixation to give ‘untouchable’, but in this process ‘touchable’ could not be referred to as a root because it is analysable in terms of derivational morphology, nor as a stem since it is not the adding of inflectional affixes which is in question.
1 of 2 quotes
Bases, stems, and roots are the main components of words, just like cells, atoms, and protons are the main components of matter.
In linguistics, the words «roots» is the core of the word. It is the morpheme that comprises the most important part of the word. It is also the primary unit of the family of the same word. Keep in mind that the root is mono-morphemic, or made of just one «chunk», or morpheme. Without the root, the word would not have any meaning. If you take the root away, all that you have left is affixes either before or after it. Such affixes do not have a lexical meaning on their own.
An example of a root is the word «act».
Now let’s look at what is a stem and a base and apply them to the root «act» so that you can see how they differ and interconnect to transform a lexical word altogether.
The stem occurs after affixes have been added to the root, for example:
Re-act ↝ Re-act-ion
Hence a stem is a form to which affixes (prefixes or suffixes) have been added. It is important to differentiate it from a root, because the root alone cannot be applied in discourse, whereas the stem exists precisely to be applied to discourse.
A base is the same as a root except that the root has no lexical meaning while the base does: «to act» is the infinitive of «act» and is structured with the base «act». In many words in our language, a word can be all three: a root, base, and stem (eg: «deer»). They differ in how they are applied during discourse (stem, base) and whether, on their own, they have any lexical meaning (stem, base) or no lexical meaning whatsoever (root).
An example of root, base and stem joined together is the word «refrigerator»:
The Latin root is frīg, which has no meaning in English on its own, and which requires a change in spelling for suffixes.
⟹ refrigerāre = Latin prefix + root + suffix, with no meaning in English of its own yet.
⟹ re- + friger + -ate + -tor = prefix + root + 2 suffixes.
The 2 suffices now produce lexical meaning = stem; spelling changes are required for suffixes.
")




")