

with tags
r
stationarity
unit-root
cointegration
time-series
—
- Concepts
- Tests
- Correlogram
- Unit root tests
- Augmented Dickey-Fuller test
- KPSS
- Literature
- Introduction
- What Are Unit Roots?
- What is a Stationary Time Series?
- What is a Unit Root?
- Why is a Unit Root Process Nonstationary?
- Why Are Unit Roots Important in Time Series Modeling?
- Permanence of Shocks
- Spurious Regressions
- Invalid Inferences
- How to Prepare Data for Unit Root Testing
- Unit Root Testing Versus Stationarity Tests
- The Augmented Dickey-Fuller Test
- The Phillips-Perron Test
- The KPSS test
- Simulated Data
- The Augmented Dickey-Fuller Test
- The Phillips-Perron Test
- The KPSS Test
- Where to Find More Advanced Unit Root Tests
- Conclusion
- Introduction
- Testing for unit roots in panel data
- Why panel data
- Panel data unit root testing
- Setting up the test
- Running the test
- The results
- Conclusions
- References
- Introduction
- What is stationarity?
- Testing for unit roots with structural breaks
- Preparing for testing
- Running the tests
- Testing Results
- Conclusions
- References
- References
Concepts
Basically stationarity means that a time series has a constant mean and constant variance over time. Althouth not particularly imporant for the estimation of parameters of econometric models these features are essential for the calculation of reliable test statistics and, hence, can have a significant impact on model selection.
To illustrate this concept, let’s look at quarterly data on disposable income in billion DM from 1960 to 1982, which is data set E1 from Luetkepohl (2007).
# Load data
library(bvartools)
data("e1")
# Disposable income in levels
income <- e1[, "income"]
# Plot series
plot(income, main = "West Germain disposable income", ylab = "Billion DM")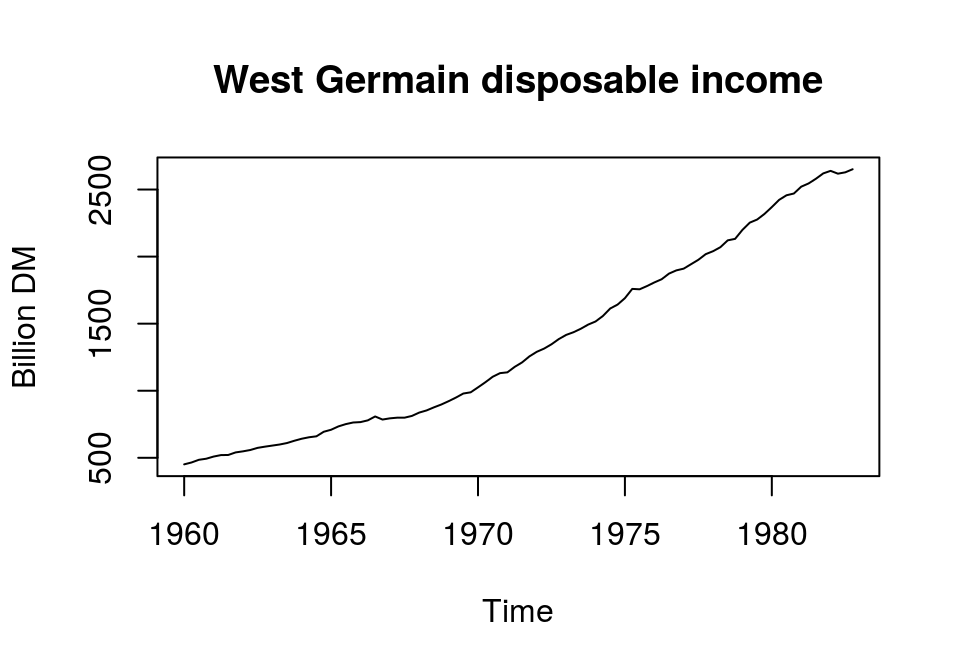
The series is continuously increasing and, thus, does not fluctuate around a constant mean. Furthermore, if we calculated the variances for an increasing window of periods from the beginning of the series to the end, we would see a constant increase in the estimated values. Therefore, disposable income in levels does not seem to be a stationary series. But how can we make this series stationary? For this it is useful to know that there are two popular models for nonstationary series, trend- and difference-stationary models.1
# Obtain ln of income
lincome <- log(income)
# Obtain detrended series
t_lincome <- (lincome - fitted(lm(lincome ~ I(1:length(lincome))))) * 100
# Plot and add horizontal line at 0
plot(t_lincome, main = "West German Disposable Income", ylab = "Deviation from linear trend"); abline(h = 0)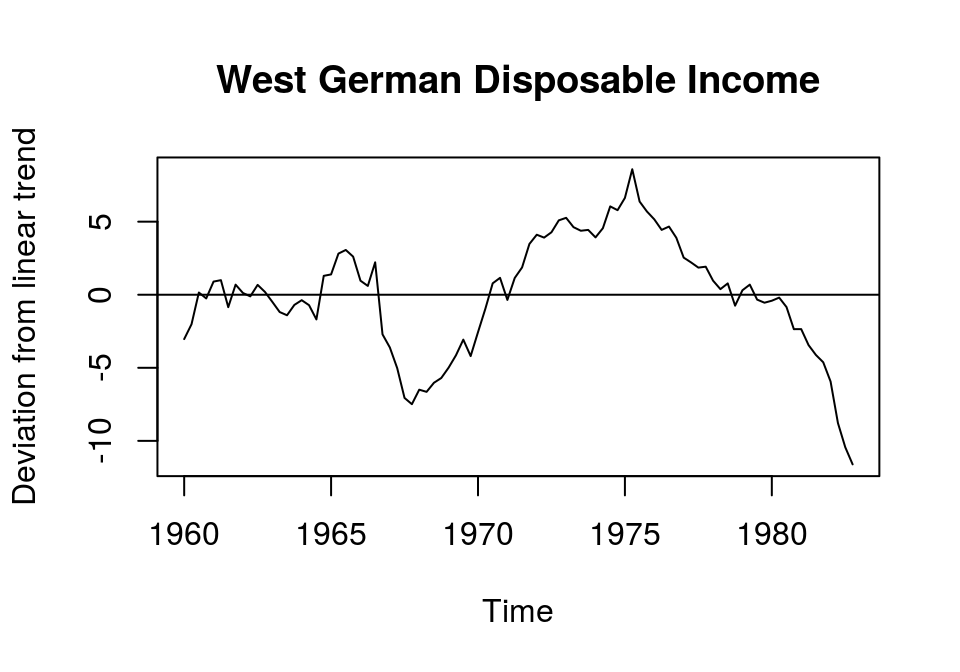
Although the mean of the resulting series is (practially) zero, its variance could be considered to increase over time. This might be due to the assumption of a simple linear trend. In this case we could search for better ways to extract the trend from this series, for example by adding a squared trend or by useing more sophisticated routines. However, note that the results of any time series analysis with trend stationary data might be sensitive to the method that was chosen to estimated the trend component of the series. It is very important to keep this in mind.
Apart from refining the method for estimating the deterministic trend of the series, the strong deviation of the actual values from the linear trend and its smoothness could also indicate a unit root, which would be associated with a difference stationary process.
Note that a time series can still contain a unit root, even when a deterministic trend was already removed. So, differencing the detrended series might still be necessary to render a series stationary.
In the case of the time series of disposable income it appears that the series is stationary after calculating the first differences of the natural logarithm. It flucuates around a relatively constant mean, exhibits a rather constant variance and is more erratic as the detrended series.2
# Obtain first log-differences of disposable income
d_lincome <- diff(log(e1[,"income"])) * 100
# # Plot and add horizontal line at 0
plot(d_lincome, main = "West German disposable income", ylab = "Log growth rate"); abline(h = 0)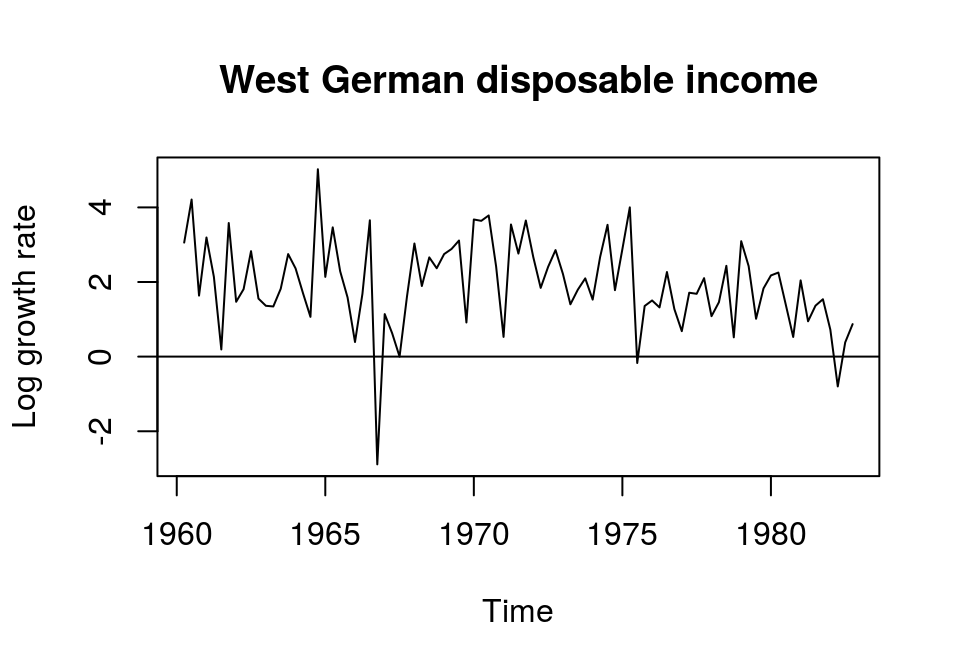
By looking at the results above, it seems that disposable income is difference-stationary with (1). But since these are rather subjective impressions, more formal tests should be applied to check this.
Tests
Correlogram
When working with the Box-Jenkins approach it is common to check the stationarity of a time series by visual inspection of the correlogram, i.e. a plot containing the th-order normalised autocorrelations. If the estimated autocorrelations die out rather quickly, the series is likely to be stationary.
lincome <- log(income)
plot(lincome, main = "Log income...", ylab = NA)
acf(lincome, main = "...and corresponding ACF", ylab = NA)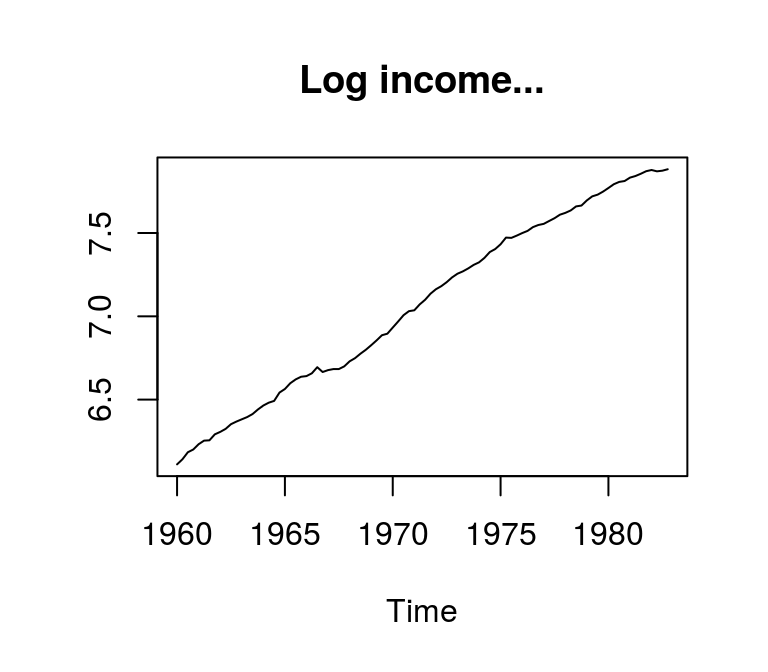
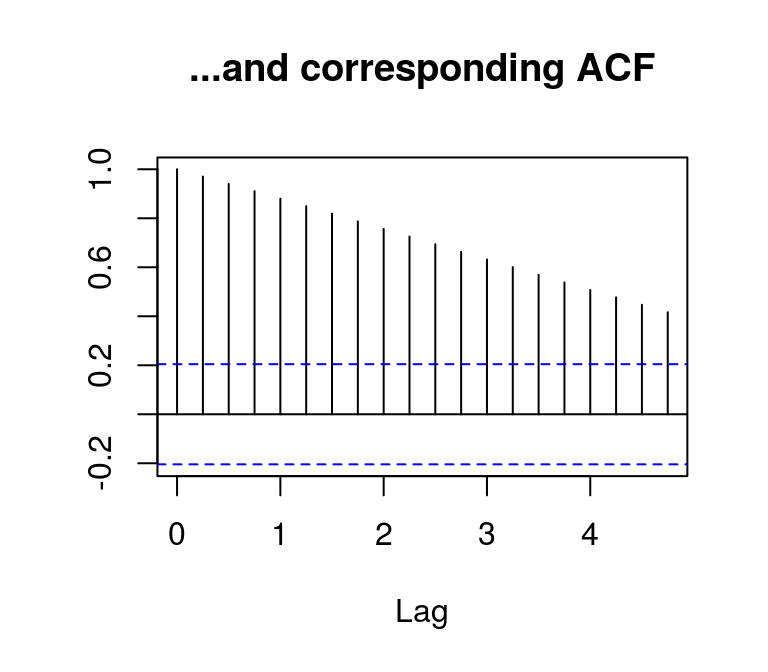
plot(t_lincome, main = "Deviation from linear trend...", ylab = NA)
acf(t_lincome, main = "...and corresponding ACF", ylab = NA)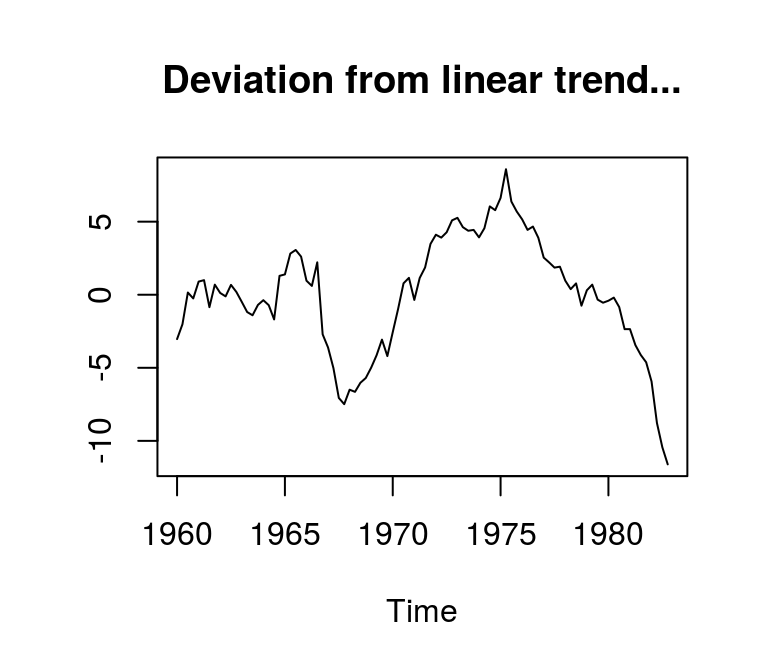
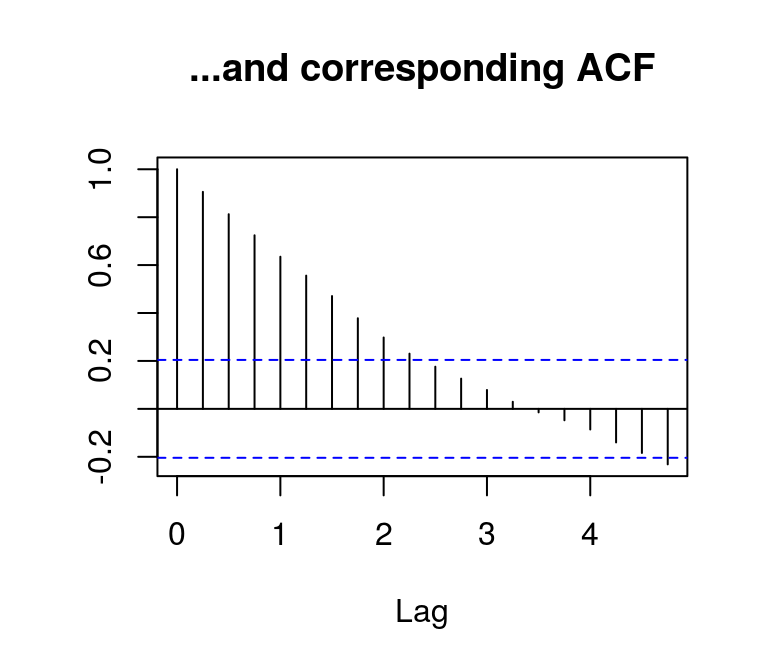
By contrast, the autocorrelations of the differenced log series die out rather quickly, which indicates stationarity.
plot(d_lincome, main = "First difference of log income...", ylab = NA)
acf(d_lincome, main = "...and corresponding ACF", ylab = NA)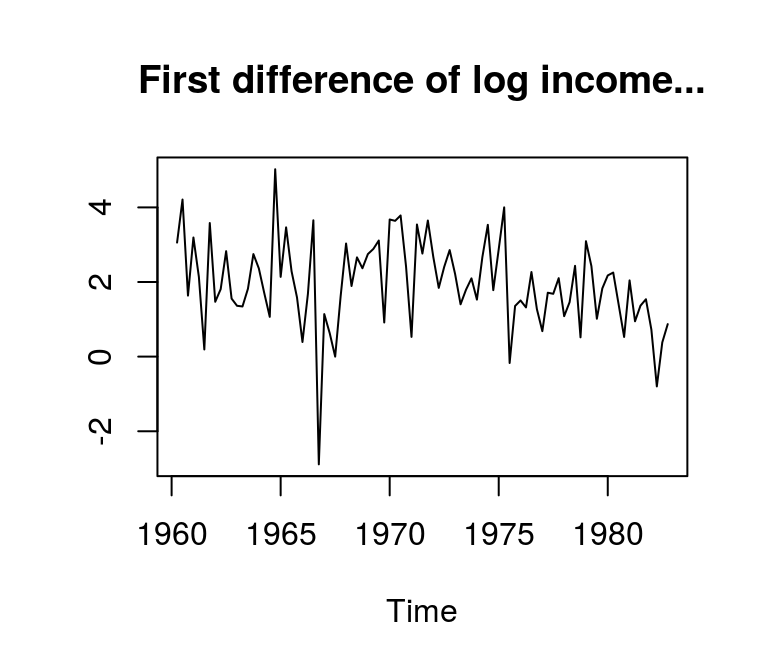
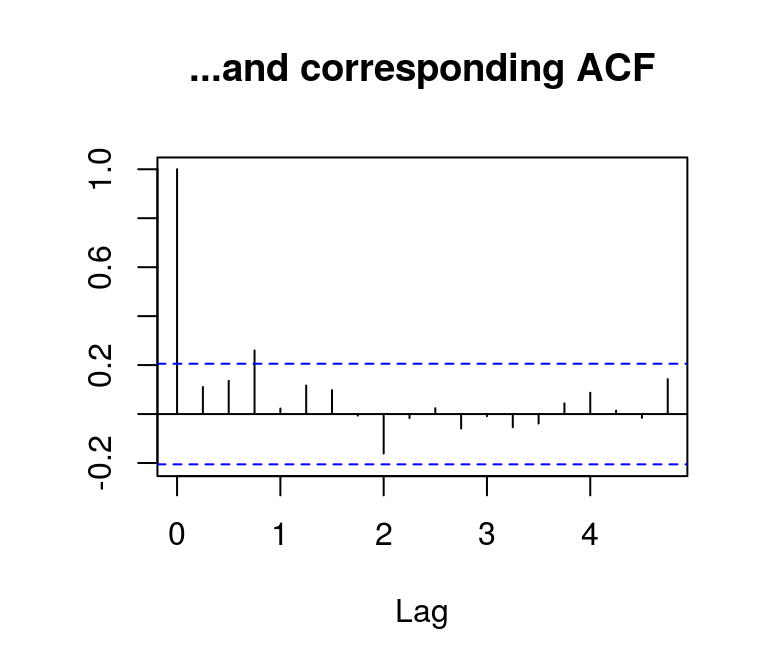
Unit root tests
For all tests the same data on log levels as well as first and second log differences are used. All series have the same length.
d1_lincome <- diff(lincome) # First difference
d2_lincome <- diff(d1_lincome) # Second difference
# Combine
data <- cbind(lincome, d1_lincome, d2_lincome)
# Get rid of NAs so that all have same length
data <- na.omit(data)
# Rename columsn
dimnames(data)[[2]] <- c("level", "diff_1", "diff_2")The tseries package contains the unit root tests that are used here.
library(tseries)Augmented Dickey-Fuller test
The augmented Dickey-Fuller (ADF) test (Said and Dickey, 1984) seems to be the most popular unit root test. It estimates the equation
adf <- data.frame(k = 0:9, level = NA, diff_1 = NA, diff_2 = NA)
# Run test for a series fo models
for (i in 1:nrow(adf)) { k <- adf$k[i] pos <- (9 - k + 1):nrow(data) # Position of used observations for (j in c("level", "diff_1", "diff_2")) { adf_test <- adf.test(data[pos, j], alternative = "stationary", k = k) adf[i, j] <- adf_test$p.value }
}
# Show results
adf## k level diff_1 diff_2
## 1 0 0.9900000 0.01000000 0.01000000
## 2 1 0.9900000 0.01000000 0.01000000
## 3 2 0.9900000 0.06318328 0.01000000
## 4 3 0.9659595 0.19862916 0.01000000
## 5 4 0.9570174 0.36135454 0.01000000
## 6 5 0.9390069 0.45127002 0.01000000
## 7 6 0.9249955 0.46563987 0.03763891
## 8 7 0.9334218 0.16353566 0.03603800
## 9 8 0.9888206 0.21500947 0.01178816
## 10 9 0.9900000 0.41652671 0.01000000The results show that the null of a unit root cannot be rejected for all lags of the series in levels. For the first differenced series the picture is mixed. For lower lag orders, the test rejects the null, but not for higher lags. For the series with data in second differences the results clearly suggest a unit root.
The original Dickey-Fuller (DF) test has proven to be not very useful in practise. Therefore, it is not covered here.
KPSS
In contrast to many other unit root tests the null hypothesis of the KPSS test (Kwiatkowski et al., 1992) is that an observable time series is (trend-)stationary. Function kpss.test allows to specify a null, where the series is level stationary or trend stationary. Since the log-series shows clear signs of a linear trend, argument null is set to "Trend" for the variable in levels. For the first and second differences the argument is set to "Level".
kpss <- data.frame(level = NA, diff_1 = NA, diff_2 = NA)
# Run test for level data
kpss[, "level"] <- kpss.test(data[pos, "level"], null = "Trend")$p.value
# Run test for first differences
kpss[, "diff_1"] <- kpss.test(data[pos, "diff_1"], null = "Level")$p.value
# Run test for second differences
kpss[, "diff_2"] <- kpss.test(data[pos, "diff_2"], null = "Level")$p.value
# Show results
kpss## level diff_1 diff_2
## 1 0.01 0.07781436 0.1The results show that for log disposable income in levels the null of stationarity is rejected at a very high confidence level. However, the test fails to reject the null of stationariy for differenced data at the 5 percent level. This is further indication that log disposable income is (1).
Literature
Hyndman, R., Athanasopoulos, G., Bergmeir, C., Caceres, G., Chhay, L., O’Hara-Wild, M., Petropoulos, F., Razbash, S., Wang, E., & Yasmeen, F. (2020). forecast: Forecasting functions for time series and linear models.
Kennedy, P. (2014). A guide to econometrics. Malden (Mass.): Blackwell Publishing 6th ed.
Kwiatkowski, D., Phillips, P. C. B., Schmidt, P., & Shin, Y. (1992): Testing the null hypothesis of stationarity against the alternative of a unit root. Journal of Econometrics 54, 159–178.
Luetkepohl, H. (2007). New introduction to multiple time series analyis. Berlin: Springer.
Said, S. E., & Dickey, D. A. (1984). Testing for unit roots in autoregressive-moving average models of unknown order. Biometrika 71(3), 599–607.
PP.test(MxAlberta_Female45,lshort=TRUE) Phillips-Perron Unit Root Test
data: MxAlberta_Female45
Dickey-Fuller = -7.5154, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxAlberta_Female45)) Phillips-Perron Unit Root Test
data: diff(MxAlberta_Female45)
Dickey-Fuller = -20.8186, Truncation lag parameter = 3, p-value = 0.01
> PP.test(MxBC_Female45) Phillips-Perron Unit Root Test
data: MxBC_Female45
Dickey-Fuller = -6.8781, Truncation lag parameter = 3, p-value = 0.01
> adf.test(diff(MxBC_Female45))
Error: could not find function "adf.test"
>
> PP.test(MxM_Female45) Phillips-Perron Unit Root Test
data: MxM_Female45
Dickey-Fuller = -6.2955, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxM_Female45)) Phillips-Perron Unit Root Test
data: diff(MxM_Female45)
Dickey-Fuller = -17.1554, Truncation lag parameter = 3, p-value = 0.01
>
> PP.test(MxNB_Female45) Phillips-Perron Unit Root Test
data: MxNB_Female45
Dickey-Fuller = -7.5638, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxNB_Female45)) Phillips-Perron Unit Root Test
data: diff(MxNB_Female45)
Dickey-Fuller = -20.2759, Truncation lag parameter = 3, p-value = 0.01
>
> MxNL_Female45a<-na.omit(MxNL_Female45)
> PP.test((MxNL_Female45a))
Error in embed(x, 2) : 'x' is not a vector or matrix
> PP.test(diff(MxNL_Female45a)) Phillips-Perron Unit Root Test
data: diff(MxNL_Female45a)
Dickey-Fuller = -15.269, Truncation lag parameter = 3, p-value = 0.01
>
> MxNTN_Female45a<-na.omit(MxNTN_Female45)
> PP.test(MxNTN_Female45a)
Error in embed(x, 2) : 'x' is not a vector or matrix
> PP.test(diff(MxNTN_Female45a)) Phillips-Perron Unit Root Test
data: diff(MxNTN_Female45a)
Dickey-Fuller = -26.5311, Truncation lag parameter = 3, p-value = 0.01
>
> PP.test(MxNS_Female45) Phillips-Perron Unit Root Test
data: MxNS_Female45
Dickey-Fuller = -6.6251, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxNS_Female45)) Phillips-Perron Unit Root Test
data: diff(MxNS_Female45)
Dickey-Fuller = -18.9064, Truncation lag parameter = 3, p-value = 0.01
>
> PP.test(MxO_Female45) Phillips-Perron Unit Root Test
data: MxO_Female45
Dickey-Fuller = -5.1652, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxO_Female45)) Phillips-Perron Unit Root Test
data: diff(MxO_Female45)
Dickey-Fuller = -23.8322, Truncation lag parameter = 3, p-value = 0.01
>
> PP.test(MxPEI_Female45) Phillips-Perron Unit Root Test
data: MxPEI_Female45
Dickey-Fuller = -8.3567, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxPEI_Female45)) Phillips-Perron Unit Root Test
data: diff(MxPEI_Female45)
Dickey-Fuller = -20.8593, Truncation lag parameter = 3, p-value = 0.01
>
> PP.test(MxQ_Female45) Phillips-Perron Unit Root Test
data: MxQ_Female45
Dickey-Fuller = -4.328, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxQ_Female45)) Phillips-Perron Unit Root Test
data: diff(MxQ_Female45)
Dickey-Fuller = -14.1897, Truncation lag parameter = 3, p-value = 0.01
>
> PP.test(MxS_Female45) Phillips-Perron Unit Root Test
data: MxS_Female45
Dickey-Fuller = -7.0793, Truncation lag parameter = 3, p-value = 0.01
> PP.test(diff(MxS_Female45)) Phillips-Perron Unit Root Test
data: diff(MxS_Female45)
Dickey-Fuller = -23.2774, Truncation lag parameter = 3, p-value = 0.01
>
> MxY_Female45a<-na.omit(MxY_Female45)
> PP.test(MxY_Female45a)
Error in embed(x, 2) : 'x' is not a vector or matrix
> PP.test(diff(MxY_Female45a)) Phillips-Perron Unit Root Test
data: diff(MxY_Female45a)
Dickey-Fuller = -17.6945, Truncation lag parameter = 3, p-value = 0.01I’m working out the Philips Perron test in R. Here you can see the results and I’m wondering on why pvalues come always 0,01 not only for the variable level but also at the differential level. Please some advices on what comes wrong in my codes.
Вообще-то, теоретически известно, что для моделей авторегрессии критерий AIC склонен к переоценке порядка модели, а BIC такого недостатка лишен. Но какой критерий выбрать — это решать вам, ибо формального ответа на этот вопрос нет.
Но сам вопрос мне не совсем понятен. ADF-test используется для ответа на вопрос, стационарен ли ряд. Если нет — берем разности, и повторяем процедуру. Таким образом определеяем уровень интегрируемости ряда.
Если нам надо строить модель — строим ее, даже если она не стационарна. Например ARIMA. В ней один параметр мы определили — I. Остальные надо как-то подобрать (например по анализу коррелограмм), но у нас все равно может оказаться несколько моделей. Строим их. А потом из них хотим выбрать лучшую. Используя для этого либо R-квадрат и его модификации, либо AIC, BIC, HQ, либо другие тесты.
Ну прекрасно. Каким боком результат ADF-test к интерпретации результата?
И что означает фраза «Если в дальнейшем используется VAR c лагом 3, то и ADF-test необходимо рассматривать с 3 лагами» если ADF-test используется ДО построения модели?
Но даже если вы вдруг ADF-test решили использовать для анализа остатков регрессионных моделей, то и тогда связь (логика) в вашем вопросе остается непонятной.
I’ve been quite confused by the various unit root testing strategies recommended in the literature, so I was hoping others may have some advice on the best way to proceed using ADF and KPSS tests.
1.1. Check tau3: $H_0: \pi = 0$ (t-test for presence of a unit root), reject if tau3 < critical value at 5pct and conclude there is no unit root, otherwise go to step 1.2.
2.1. Check tau2: $H_0: \pi = 0$ (t-test for presence of a unit root), reject if tau2 < critical value at 5pct level and conclude that there is no unit root, otherwise proceed to step 2.2.
3.1. Check tau1: $H_0: \pi = 0$ (t-test for presence of a unit root), reject $H_0$ if tau1 < critical value at 5pct level and conclude that there is no unit root, otherwise conclude that there is a unit root
If a unit root is found, take first differences and repeat procedure to find order of integration.
a. While I understand the outlined procedure, I am not quite certain how to relate the five different types of series (i)-(v) above to the test results. I guess failure to reject $H_0$ in step 3.1. is equivalent to (iv), whereas rejection of $H_0$ in step 2.2. would be (v), but what about others?
b. It is often recommended to test again whether $\pi = 0$ under a normal distribution if $H_0$ is rejected at steps 1.2. or 2.2. How is this done and why would this be necessary?
c. Could the KPSS test, which has an opposite $H_0$ (series is stationary), be used to distinguish between the five different types of series (i)-(v)? How should contradictions with the ADF be handled?
logprice_df <- ur.df(test3, lags = 1, type= 'trend')
summary(logprice_df)
###############################################
# Augmented Dickey-Fuller Test Unit Root Test #
###############################################
Test regression trend
Call:
lm(formula = z.diff ~ z.lag.1 + 1 + tt + z.diff.lag)
Residuals: Min 1Q Median 3Q Max
-0.50614 -0.04394 0.00134 0.03859 0.64408
Coefficients: Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.841e-02 8.268e-03 2.226 0.02626 *
z.lag.1 -1.573e-02 5.635e-03 -2.791 0.00537 **
tt 9.234e-06 1.080e-05 0.855 0.39272
z.diff.lag 1.411e-01 3.364e-02 4.195 3.01e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.07512 on 865 degrees of freedom
Multiple R-squared: 0.02651, Adjusted R-squared: 0.02314
F-statistic: 7.852 on 3 and 865 DF, p-value: 3.572e-05
Value of test-statistic is: -2.791 2.6012 3.8997
Critical values for test statistics: 1pct 5pct 10pct
tau3 -3.96 -3.41 -3.12
phi2 6.09 4.68 4.03
phi3 8.27 6.25 5.34I really appreciate any help.

10 gold badges85 silver badges139 bronze badges
asked Sep 23, 2013 at 9:59


answered Sep 25, 2013 at 10:59

1 gold badge1 silver badge6 bronze badges
for the unit root, compare your test statistic with the critical value (tau at 5pct). if your test stat < crit value, reject Ho ad conclude that the series is stationary.
NB: don’t look at the P values as they are asymptotic.
answered Nov 15, 2022 at 21:15

At the current moment (version 1.2-10, 2012-05-05) it seems that the unbalanced case is not supported. Edit: The issue of unbalanced panel data is solved in version 2.2-2 of plm on CRAN (2020-02-21).
Rest of the answer is assuming version 1.2-10:
object <- as.data.frame(split(object, id))If you pass unbalanced panel, this line will make it balanced by repeating the same values. If your unbalanced panel has time series with lengths which divide each other then even no error message is produced. Here is the example from purtest page:
> data(Grunfeld) > purtest(inv ~ 1, data = Grunfeld, index = "firm", pmax = 4, test = "madwu")
Maddala-Wu Unit-Root Test (ex. var. : Individual Intercepts ) data: inv ~ 1 chisq = 47.5818, df = 20, p-value = 0.0004868 alternative hypothesis: stationarity This panel is balanced:
> unique(table(Grunfeld$firm)) [1] 20 > gr <- subset(Grunfeld, !(firm %in% c(3,4,5) & year <1945))Two different time series length in the panel:
> unique(table(gr$firm)) [1] 20 10No error message:
> purtest(inv ~ 1, data = gr, index = "firm", pmax = 4, test = "madwu") Maddala-Wu Unit-Root Test (ex. var. : Individual Intercepts )
data: inv ~ 1
chisq = 86.2132, df = 20, p-value = 3.379e-10
alternative hypothesis: stationarity Another disbalanced panel:
> gr <- subset(Grunfeld, !(firm %in% c(3,4,5) & year <1940)) > unique(table(gr$firm)) [1] 20 15And the error message:
> purtest(inv ~ 1, data = gr, index = "firm", pmax = 4, test = "madwu") Erreur dans data.frame(`1` = c(317.6, 391.8, 410.6, 257.7, 330.8, 461.2, : arguments imply differing number of rows: 20, 15Introduction
In time series modeling we often encounter trending or nonstationary time series data. Understanding the characteristics of such data is crucial for developing proper time series models. For this reason, unit root testing is an essential step when dealing with time series data.
In this blog post, we cover everything you need to conduct time series data unit root tests using GAUSS. This includes:
- An introduction to the concept of unit roots.
- A discussion of why unit roots matter.
- How to prepare your time series data for unit root testing.
- How to run and interpret the fundamental tests in GAUSS including the Augmented Dickey-Fuller (ADF) and Phillips-Perron unit root tests and the KPSS stationarity test.
- Where to look for more advanced unit root testing procedures.
What Are Unit Roots?
Unit roots are often used interchangeably with the idea of nonstationarity. This isn’t completely off base, because the two are related. However, it is important to remember that while all unit root processes are nonstationary, not all nonstationary time series are unit root processes.
What is a Stationary Time Series?
A time series is stationary when all statistical characteristics of that series are unchanged by shifts in time. Time series models generally are valid only under the assumption of weak stationarity.
A weakly stationary time series has:
- The same finite unconditional mean and finite unconditional variance at all periods.
- An autocovariance that is independent of time.
Nonstationarity can be caused by many factors including structural breaks, time trends, or unit roots.
What is a Unit Root?
A unit root process:
- Contains a stochastic, or random walk, component;
- Is sometimes referred to as integrated of order one, I(1);
- Has a root of the characteristic equation which lies outside the unit circle. (The mathematics of this is beyond the scope of this blog).
There are some important implications of unit roots:
- Shocks to unit root processes have permanent effects.
- Detrending unit root time series does NOT lead to stationarity but first-differencing does.
Why is a Unit Root Process Nonstationary?
Let’s consider the simplest example, the AR(1) unit root process
Since the mean of the error term, $\epsilon_t$, is zero and the scalar value $\phi_0$ is added at each time period, the expected value of this process is
which changes with time. Additionally, the variance given by
is also dependent on time.
Why Are Unit Roots Important in Time Series Modeling?
Unit root processes have important implications for time series modeling including:
- Permanence of shocks;
- Spurious regressions;
- Invalid inferences.
Permanence of Shocks

If time series data contains a unit root, shocks will have a permanent impact on the path of the data.
The top panel in the above graph shows the impact of a random shock on an AR(1) process with a unit root. After the shock hits the process transitions to a new path and there is no mean-reversion.
Conversely, the bottom panel shows the impact of the same shock to a stationary AR(1) series. In this case, the impact of the shock is transitory and the series reverts to the original mean when the blue line of the shock path overlaps the orange line of the original series.
Spurious Regressions
Many time series models which estimate the relationship between two variables assume that both are stationary series. When neither series is stationary, regression models can find relationships between the two series that do not exist.
Let’s look at an example using GAUSS.
First, we simulate two unit root series:
// Number of observations
nobs = 150;
// Generate two vectors of random disturbances
e1 = rndn(nobs, 1);
e2 = rndn(nobs, 1);
// Find cumulative sum of disturbances
y1 = cumsumc(e1);
x1 = cumsumc(e2);Next, we use the ols procedure to regress y1 on x1:
call ols("", y1, x1);Valid cases: 150 Dependent variable: Y Missing cases: 0 Deletion method: None Total SS: 5161.244 Degrees of freedom: 148 R-squared: 0.450 Rbar-squared: 0.446 Residual SS: 2838.019 Std error of est: 4.379 F(1,148): 121.154 Probability of F: 0.000 Standard Prob Standardized Cor with Variable Estimate Error t-value >|t| Estimate Dep Var ------------------------------------------------------------------------------- CONSTANT -3.645808 0.419546 -8.689894 0.000 --- --- X1 0.615552 0.055924 11.006998 0.000 0.670916 0.670916
Despite the fact that these two series are unrelated, the model suggests a statistically significant relationship between y1 and x1. The estimated coefficient on x1 is 0.616 with a t-statistic of 11.00 and a p-value of 0.000.
A regression of one I(1) series on other I(1) series can:
- Lead to OLS coefficients that do not converge to the true value of zero and do not have the standard normal distribution.
- Cause OLS t-stats to diverge to infinity and falsely suggest statistically significant relationships.
- Results in a $R^2$ that converges to one, incorrectly suggesting strong model fit.
Invalid Inferences
Unit root time series have three characteristics that can impact inferences in standard time series models:
- The mean is not constant over time;
- The variance of the series is non-constant;
- The autocorrelation between adjacent observations decays very slowly.
Combined, these imply that the Law of Large Numbers does not hold for a nonstationary series. This, in turn, means that inferences based on standard test-statistics and distributions are no longer valid.
How to Prepare Data for Unit Root Testing

Before running any unit root tests, we must first determine if our data has any deterministic components such as a constant or time trend.
How do we determine if our data has a time trend or constant?
Time series plots are useful for identifying constants and time trends which is why the first step to any time series modeling should be data visualization.
The graph above plots three different AR(1) time series. The time series plot in the first panel has no constant and no trend with the data generating process
We can tell visually that the series has no constant or trend, because it fluctuates around the zero line.
The series has the same shape as the first series but is shifted upward and fluctuates around 1.5 instead of 0.
This series fluctuates around an increasing, time-dependent, line.
Unit Root Testing Versus Stationarity Tests
When testing for I(1) series, there are two broad categories of tests, those that test for unit roots and those that test for stationarity.
Unit root tests consider the null hypothesis that a series contains a unit root against the alternative that the series is trend stationary.
Time series stationarity tests consider the null hypothesis that a series is trend stationary against the alternative that it contains a unit root.
It is important to distinguish which test we are running to avoid making incorrect conclusions about our test results.
The Augmented Dickey-Fuller Test
The first unit root test we will consider is the Augmented Dickey-Fuller (ADF) test. The ADF test is based on the test regression
where $D_T$ is a vector of deterministic components which can include a constant and/or a trend.
The ADF test considers the null hypothesis that the series is I(1), or has a unit root, against the alternative hypothesis that the series is I(0).
The Phillips-Perron Test
The Phillips-Perron test also considers the null hypothesis that the series contains a unit root against the alternative that there is no unit root. However, it addresses the issues of serial correlation by adjusting the OLS estimate of the AR(1) coefficient.
Three specifications are considered, an AR(1) model without a drift, an AR(1) with a drift, and an AR(1) model with a drift and linear trend:
The KPSS test
Unlike the previous tests, the KPSS uses a Lagrange multiplier type test of the null hypothesis of stationarity against the alternative hypothesis that the data contains a unit root.
The residuals from the regression $y_t = \Delta D_t$ are used in combination with a heteroskedasticity and autocorrelation consistent estimate of the long-run variance, to construct the KPSS test statistic.
The Time Series MT Application includes tools for conducting standard unit root testing. Today we will consider the three fundamental unit root tests discussed above:
- Augmented Dickey-Fuller test;
- Phillips-Perron test;
- KPSS test.
Simulated Data
For this example, we will simulate data using the simarmamt procedure. The three time series we will simulate, encompass three different cases of deterministic components:
new;
cls;
library tsmt;
/*
** Step One: Generate Data
*/
// Coefficient on AR(1) term
phi = 0.80;
// AR order
p = 1;
// MA order
q = 0;
// Constant
const1 = 0;
const2 = 2.5;
const3 = 2.5;
// Trend
trend1 = 0;
trend2 = 0;
trend3 = 0.20;
// Number of obsevations
n = 150;
// Number of series
k = 1;
// Standard deviation
std = 1;
// Set seed for reproducing data
seed = 10191;
// Case One: No deterministic components
y1 = simarmamt(phi, p, q, const1, trend1, n, k, std, seed);
// Case Two: With Constant
y2 = simarmamt(phi, p, q, const2, trend2, n, k, std, seed);
// Case Three: With Constant and Trend
y3 = simarmamt(phi, p, q, const3, trend3, n, k, std, seed);The Augmented Dickey-Fuller Test
We can run the Augmented Dickey-Fuller test in GAUSS using the vmadfmt procedure included in the Time Series MT library.
The vmadfmt procedure requires three inputs:
- yt
- Vector, the time series data.
- p
- Scalar, the order of the deterministic component. Valid options include:
-1 = No deterministic component,
0 = Constant,
1 = Constant and trend. - l
- Scalar, the number of lagged dependent variables to include in the ADF regression.
In this case, we know that our data is AR(1), so we set l = 1. Also, we will call vmadfmt three times, once for each of our datasets:
/*
** ADF Testing
*/
/* Order of deterministic trend to include
** -1 No deterministic trends
** 0 Constant
** 1 Constant and Trend
*/
// No deterministic trends
{ rho1, tstat1, adf_t_crit1 } = vmadfmt(y1, -1, 1);
// Constant
{ rho2, tstat2, adf_t_crit2 } = vmadfmt(y2, 0, 1);
// Constant and trend
{ rho3, tstat3, adf_t_crit3 } = vmadfmt(y3, 1, 1);Interpreting the ADF Results
The vmadfmt procedure returns three values:
- rho
- The estimated autoregressive coefficient.
- tstat
- The t-statistic for the estimated autoregressive coefficient, rho.
- tcrit
- (6 x 1) vector of critical values for the ADF t-statistic: 1, 5, 10, 90, 95, 99%
We’ve summarized the tstat and tcrit results in the table below:
Augmented Dickey-Fuller Intepretation
There are several things to note about these results:
- The critical values are specific to the deterministic trends and follow a non-standard distribution known as the Dickey-Fuller distribution.
- As the t-stat (tstat1, tstat2, tstat3) decreases, the likelihood of rejecting the null hypothesis increases.
- For y1, y2 and y3 we can reject the null hypothesis of the unit root at the 1% level. This is because the t-stats of -3.690, -4.047, -4.490 are less than the 1% respective critical values of -2.602, -3.439, and -4.005.
These results should not be surprising to us since we used simulated data with an autoregressive coefficient whose absolute value was less than one. It should be noted that we also knew the correct lag specification and deterministic trends to use with our test because we knew the true data generating process.
In reality, the data generating processes will be unknown and you may need to conduct additional testing to confirm the proper lags and deterministic trends.
The Phillips-Perron Test
We can run the Phillip-Perron test in GAUSS using the vmppmt procedure included in the Time Series MT library.
The vmppmt procedure requires three inputs:
- yt
- Vector, the time series data.
- p
- Scalar, the order of the deterministic component. Valid options include:
-1 = No deterministic component,
0 = Constant,
1 = Constant and trend. - nwtrunc
- Scalar, the number of autocorrelations to use in calculating the Newey-West correction. GAUSS will compute the data-driven, optimal truncation length when this is set to 0.
For the Phillips-Perron case, we will let GAUSS pick the optimal Newey-West truncation length by setting nwtrunc = 0. Again, we will call vmppmt three times, once for each of our datasets:
/*
** Phillips-Perron
*/
/* The second input reflects the deterministic
** components to include
** -1 No deterministic trends
** 0 Constant
** 1 Constant and Trend
*/
// No deterministic components
{ ppb1, ppt1, pptcrit1 } = vmppmt(y1, -1, 0);
// Constant
{ ppb2, ppt2, pptcrit2 } = vmppmt(y2, 0, 0);
// Constant and trend
{ ppb3, ppt3, pptcrit3 } = vmppmt(y3, 1, 0);Interpretting the Phillip-Perron Results
The vmppmt procedure returns three values:
- ppb
- The estimated autoregressive coefficient.
- ppt
- The t-statistic for the estimated autoregressive coefficient, ppb.
- pptcrit
- (6 x 1) vector of critical values for the pp t-statistic: 1, 5, 10, 90, 95, 99%
Again, we summarize the two most relevant outputs, ppt and pptcrit:
Like our ADF results, there are several notable points to draw from these results:
- The critical values are specific to the deterministic trends and follow the same Dickey-Fuller distribution as the ADF test.
- More observations are used for running the Phillips-Perron test regression than in the ADF case. The ADF case loses observations due to lagging. As a result, the critical values for the Phillips-Perron test differ from those for the ADF test of the same data.
- As the t-stat (ppt1, ppt2, ppt3) decreases, the likelihood of rejecting the null hypothesis increases.
- For y1, y2 and y3 we can reject the null hypothesis of the unit root at the 1% level. This is because the t-stats of -3.733, -4.137, -4.591 are less than the 1% respective critical values of -2.586, -3.464, and -4.001.
The KPSS Test
The final test we will run is Kwiatkowski–Phillips–Schmidt–Shin (KPSS) tests. The KPSS test can be conducted in GAUSS using the kpss procedure included in the Time Series MT library.
The kpss procedure has one required input and five optional inputs:
- yt
- Vector, the time series data.
- max_lags
- Optional input, scalar, the maximum lags included in the KPSS test. Providing a non-negative, non-zero integer for max_lags directly specifies the maximum lag autocovariance used. If the max_lags input is zero, the maximum number of lags is determined using the Schwert criterion. Default = 0.
- trend
- Optional input, scalar, 0 if no trend is present, 1 if a trend is present. Default = 0.
- qsk
- Optional input, scalar, if nonzero, the quadratic spectral kernel is used. Default = 0.
- auto
- Optional input, scalar, if nonzero, automatic max_lags computed. Default = 1.
- print_out
- Optional input, scalar, if nonzero, intermediate quantities will be printed to the screen. Default = 1.
Today we will use only the first two optional inputs and will use the default values for the rest. Again, we call KPSS three times, once for each of our datasets:
/*
** KPSS
*/
/*
** Note that we use the default maxlags
** and trend settings for the two cases without a trend.
*/
// No deterministic trends
{ lm1, crit1 } = kpss(y1);
// Constant and no trend
{ lm2, crit2 } = kpss(y2);
// Constant and trend
{ lm3, crit3 } = kpss(y3, 0, 1);Interpretting the KPSS Results
The kpss procedure returns two values:
- kpss_lm
- (maxlags x 1) vector of KPSS Lagrange multiplier statistics for stationarity.
- crit
- (4 x 1) vector of critical values for the KPSS statistic: 1, 2.5, 5, 10%
This test yields some interesting results worth noting:
- The test statistic is computed for each of the lags up to the maximum lags. The Schwert criterion selected 4 lags as the optimal number of lags for all cases (which is highlighted in the table).
- The presence of a non-zero constant does not affect the test statistic or the critical values. However, the presence of a trend affects both.
- Because this is a one-sided LM test of stationarity, we reject the null hypothesis of stationarity at a specific p-level if the test statistic exceeds the critical value.
- Note that the KPSS test for y1 and y2 suggest that we should reject the null hypothesis of stationarity at least at the 5% level for all lags.
- The KPSS test for trend stationarity of y3 shows similar results, though they are more sensitive to lag selection.
These results highlight one of the known issues with the KPSS test. We know our data is stationary because we know the true data generating process. However, the KPSS test concludes that we should reject the null hypothesis of stationarity.
The KPSS test is known for incorrectly rejecting the null hypothesis of stationarity more frequently than other tests. This is known as having a high rate of Type 1 Errors.
Where to Find More Advanced Unit Root Tests
- Unit root testing on panel data requires a separate set of tools. The GAUSS TSMT library provides the following panel data unit root tests:
- Im, Pesaran, and Shin;
- Levin-Lin-Chu;
- Breitung and Das.
- Data with structural breaks requires specialized unit root tests which accommodate nonlinearities. A full suite of these tests, for both time series and panel data, are provided in the free and open-source GAUSS tspdlib library.
Conclusion
This week we covered everything you need to know to be able to test your data for unit roots using GAUSS. This includes:
- An introduction to the concept of unit roots.
- A discussion of why unit roots matter.
- How to prepare your time series data for unit root testing.
- How to run and interpret the fundamental tests in GAUSS including the Augmented Dickey-Fuller (ADF) and Phillips-Perron unit root tests and the KPSS stationarity test.
- Where to look for more advanced unit root testing procedures.
After this week you should have a better understanding of how to determine if a time series is stationary using GAUSS.

Director of Applications and Training at Aptech Systems, Inc.
Eric has been working to build, distribute, and strengthen the GAUSS universe since 2012. He is an economist skilled in data analysis and software development. He has earned a B.A. and MSc in economics and engineering and has over 18 years of combined industry and academic experience in data analysis and research.

Introduction
In this blog, we extend last week’s analysis of unit root testing with structural breaks to panel data.
We will again use the quarterly current account to GDP ratio but focus on a panel of data from five countries: United States, United Kingdom, Australia, South Africa, and India.
Using panel data unit roots tests found in the GAUSS tspdlib library we consider if the panel collectively shows unit root behavior.
Testing for unit roots in panel data
Why panel data
There are a number of reasons we utilize panel data in econometrics (Baltagi, 2008). Panel data:
- Capture the idiosyncratic behaviors of individual groups with models like the fixed effects or random effects models.
- Contain more information, more variability, and more efficiency.
- Can detect and measure statistical effects that pure time-series or cross-section data can’t.
- Provide longer time-series for unit-root testing, which in turn leads to standard asymptotic behavior.
Panel data unit root testing
Today we will test for unit roots using the panel Lagrangian Multiplier (LM) unit-root test with structural breaks in the mean (Im, K., Lee, J., Tieslau, M., 2005):
- The panel LM test statistic averages the individual LM test statistics which are computed using the pooled likelihood function.
- The asymptotic distribution of the test is robust to structural breaks.
- The test considers the null unit root hypothesis against the alternative that at least one time series in the panel is stationary.
Setting up the test
The panel LM test can be run using the GAUSS PDLMlevel procedure found in the GAUSS tspdlib library. The procedure requires six inputs:
- y_test
- T x N matrix, the panel data to be tested.
- model
- Scalar, indicates the type of model to be tested.
1 = break in level.
2 = break in level and trend. - pmax
- Scalar, Maximum number of lags for Dy. 0 = no lags.
- ic
- Scalar, the information criterion used to select lags.
1 = Akaike.
2 = Schwarz.
3 = t-stat significance. - trimm
- Scalar, data trimming rate.
- nbreak
- Scalar, the number of breaks to allow.
1 = one break.
2 = two breaks.
The PDLMlevel procedure has five returns:
- Nlm
- Vector, the minimum test statistic for each cross-section.
- Ntb
- Vector, location of break(s) for each cross-section.
- Np
- Scalar, number of lags selected by chosen information criterion for each cross-section.
- PDlm
- Scalar, p-value of PDlm.
Running the test
The test is easy to set up and run in GAUSS. We first load the GAUSS tspdlib library and set our model parameters. For our data we:
- Trim the top and bottom 10% of the data from potential breaks.
- Use a maximum of 12 lags for the dy.
- Determine lags using the t-statistic significance.
library tspdlib;
// Load data
ca_panel = loadd("panel_ca.dat");
y_test = ca_panel[.,2:cols(ca_panel)];
// Maximum number of lags for Dy
pmax = 12;
// Information Criterion: T-stat significance
ic = 3;
// Trimming rate
trimm = 0.10; After setting parameters we call the PDLMlevel procedure separately for the one break and two break models:
// Run first with one break
nbreak = 1;
// Call PD LM with level break
{ Nlm, Ntb, Np, PDlm, pval } = PDLMlevel(y_test, 1, pmax, ic, trimm, nbreak);
// Run first with two breaks
nbreak = 2;
// Call PD LM with level break
{ Nlm, Ntb, Np, PDlm, pval } = PDLMlevel(y_test, 1, pmax, ic, trimm, nbreak);The results
Research on the presence of unit roots in current account balances has had mixed results. These results bring to the forefront the question of current account balance sustainability (Clower & Ito, 2012).
Our panel tests with structural breaks unanimously reject the null hypothesis of unit roots for all cross-sections, as well as the combined panel. This adds support, at least for our small sample, to the idea that current account balances are sustainable and mean-reverting.
Conclusions
Today we’ve learned about conducting panel data unit root testing in the presence of structural breaks using the LM test from (Im, K., Lee, J., Tieslau, M., 2005). After today you should have a better understanding of:
- Some of the advantages of using panel-data.
- How to test for unit roots in panel data using the LM test with structural breaks.
- How to use the GAUSS tspdlib library to test for unit roots with structural breaks.
Code and data from this blog can be found here.
References
Baltagi, B. (2008). Econometric analysis of panel data. John Wiley & Sons.
Clower, E., & Ito, H. (2012). The persistence of current account balances and its determinants: the implications for global rebalancing.
Im, K., Lee, J., Tieslau, M. (2005). Panel LM Unit-root Tests with Level Shifts. Oxford Bulletin of Economics and Statistics 67, 393–419.

Introduction
In this blog, we examine the issue of identifying unit roots in the presence of structural breaks.
We will use the quarterly US current account to GDP ratio to compare results from a number of unit root test found in the GAUSS tspdlib library including the:
- Zivot-Andrews (1992) unit root test with a single structural break.
- Narayan and Popp (2010) unit root test with two structural breaks
- Lee and Strazicich (2013, 2003) LM tests with one and two structural breaks
- Enders and Lee Fourier (2012) ADF and LM tests
What is stationarity?
Stationary series have a mean and covariance that do not change over time. This implies that a series is mean-reverting and any shock to the series will have a temporary effect.

In the graph above we compare a stationary, non-stationary, and trend stationary AR(1) series. Looking at the blue stationary series we can see that despite the random shocks, the series fluctuates around its zero mean.
The green line is the same series as the stationary series with an added constant time trend. Though this time-series grows over time, it fluctuates around its constant time trend.
Finally, the orange line is a non-stationary series and has a unit root. It does not revert to a mean or trend line and its stochastic shocks have permanent impacts on the series.

The graph above helps demonstrate the impact of structural breaks on stationarity. The series plotted above shows a structural break in the level and clearly does not revert around the same mean across all time.
Though the series is stationary within each section, most standard unit roots will bias towards non-rejection of the unit root for this series.
This is problematic because different modeling techniques should be used for the unit-root series than the series with a structural break.
Testing for unit roots with structural breaks
A number of different unit root tests have emerged from the research surrounding structural breaks and unit roots. These tests vary depending on the number of breaks in the data, whether a trend is present or not, and the null hypothesis that is being tested.
Today we will compare the results from six different tests, all of which can be found in the GAUSS TSPDLIB library.
Preparing for testing
Before running the tests in the GAUSS TSPDLIB library, we must set-up a number of input parameters. All of the tests, with the exception of the Fourier expansion test, require the same inputs:
- y_test
- Vector, the time-series to tested.
- model
- Scalar, indicates the type of model to be tested.
1 = break in level.
2 = break in level and mean. - pmax
- Scalar, Maximum number of lags for Dy. 0 = no lags.
- ic
- Scalar, the information criterion used to select lags.
1 = Akaike.
2 = Schwarz.
3 = t-stat significance. - trimm
- Scalar, data trimming rate. Not required for the Fourier expansion tests.
- fmax
- Scalar, maximum number of single Fourier frequency. Required only for the Fourier expansion tests.
/*
** Specify input parameters for unit root testing models
*/
// Model A: break in level
model = 1;
// Maximum number of lags for Dy
pmax = 12;
// Maximum number of Fourier
fmax = 4;
// Information Criterion: T-stat significance
ic = 3;
// Trimming rate
trimm = 0.10; Running the tests
The six tests can be called directly from the GAUSS TSPDLIB library:
// One break ADF test (Zivot & Andrews, 1992)
{ ADF_min, tb1, p, cv } = ADF_1break(y_test, model, pmax, ic, trimm);
// Two breaks ADF test (Narayan & Popp, 2010)
{ ADF_min, tb1, tb2, p, cv } = ADF_2breaks(y_test, model, pmax, ic, trimm);
// Fourier ADF test (Enders & Lee, 2012)
{ ADFstat, f, p, cv } = Fourier_ADF(y_test, model, pmax, fmax, ic);
// One break LM test (Lee & Strazicich, 2013)
{ LM_min, tb1, p, lambda, cv } = LM_1break(y_test, model, pmax, ic, trimm);
// Two breaks LM test (Lee & Strazicich, 2003)
{ LM_min, tb1, tb2, p, cv } = LM_2breaks(y_test, model, pmax, ic, trimm);
// Fourier LM test (Enders & Lee, 2012)";
{ LMstat, f, p, cv } = Fourier_LM(y_test, pmax, fmax, ic); Testing Results
Though not unanimous, our testing results suggest that even with the inclusion of structural breaks, we may not be able to reject the null hypothesis of a unit root for our US current account to GDP ratio data.
Conclusions
Today we’ve about conducting unit root testing in the presence of structural breaks. After today you should have a better understanding of:
- What it means for data to be stationary.
- How structural breaks can impact unit root testing.
- How to use theGAUSS TSPDLIB library to test for unit roots with structural breaks.
Code and data from this blog can be found here.
References
Enders, W., and Lee, J. (2012). A Unit Root Test Using a Fourier Series to Approximate Smooth Breaks. Oxford Bulletin of Economics and Statistics, 74(4), 574-599.
Lee, J. & Strazicich, M.C. (2003). Minimum Lagrange Multiplier unit toot test with two structural breaks. Review of Economics and Statistics, 85(4), 1082-1089.
Lee, J. & Strazicich, Mark C. (2013). Minimum LM unit root test with one structural break. Economics Bulletin, 33(4), 2483-2492.
Narayan, P.K. & Popp, S. (2010). A new unit root test with two structural breaks in level and slope at unknown time. Journal of Applied Statistics, 37(9), 1425-1438.
Zivot, E. & Andrews, W.K. (1992). Further evidence on the great crash, the oil-price shock, and the unit root hypothesis. Journal of Business and Economic Statistics, 10(3), 251-270.
In most observed series, however, the presence of a trend component results in the series being nonstationary. Furthermore, the trend can be either deterministic or stochastic, depending on which appropriate transformations must be applied to obtain a stationary series. For example, a stochastic trend, or commonly known as a unit root, is eliminated by differencing the series. However, differencing a series that in fact contains a deterministic trend results in a unit root in the moving-average process. Similarly, subtracting a deterministic trend from a series that in fact contains a stochastic trend does not render a stationary series. Hence, it is important to identify whether nonstationarity is due to a deterministic or a stochastic trend before applying the proper transformations.
In this post, I illustrate three commands that implement tests for the presence of a unit root using simulated data.
A simple example of a process with stochastic trend is a random walk.
Random walk with drift
Plots of nonstationary processes
First, I generate simulated data from a random walk model and a random walk with a drift term of 0.1 and plot the graph below. The code for generating the data and plots are provided in the Appendix section.
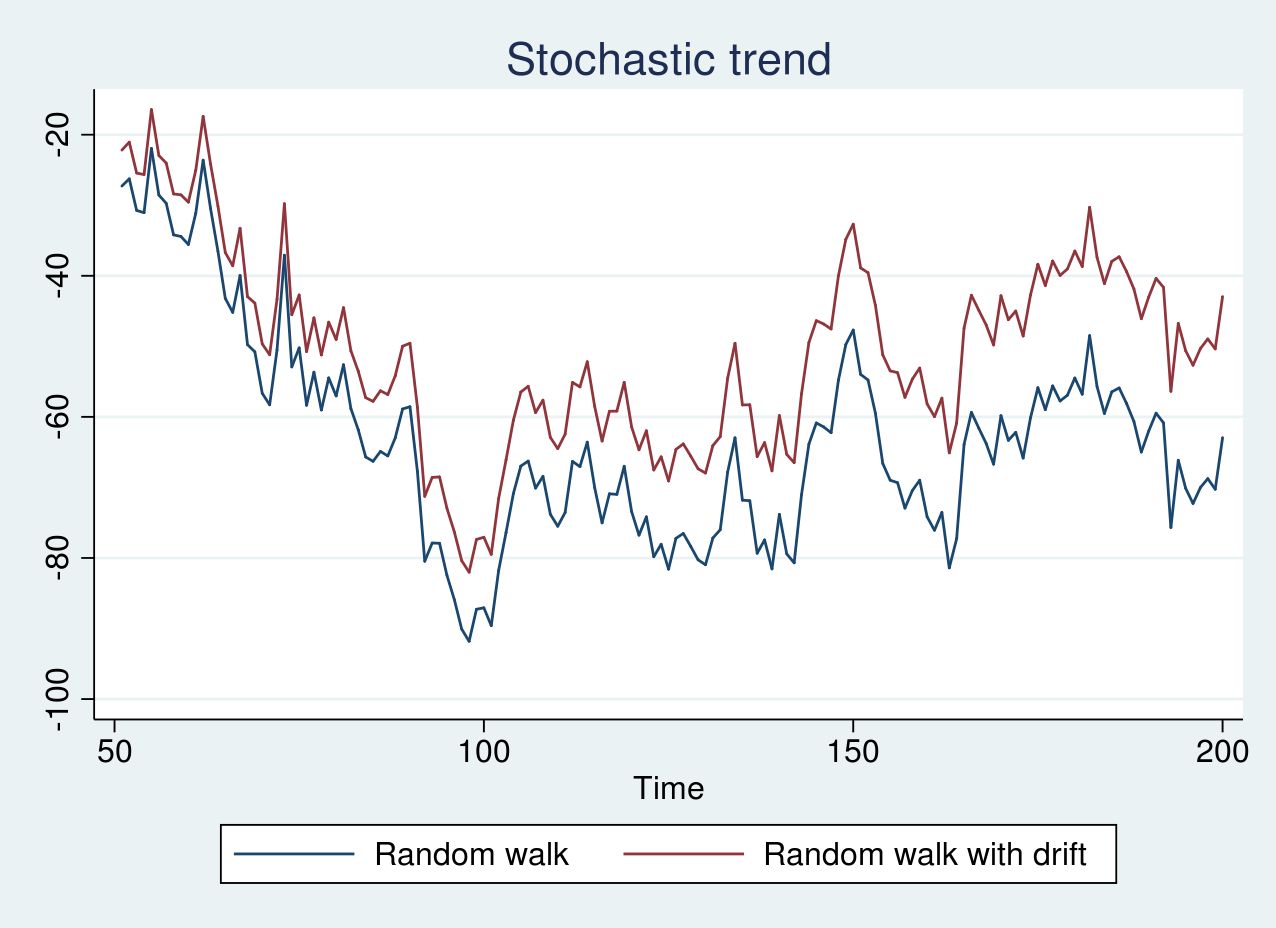
As seen in the graph above, there is no clear trend, and the red line appears to be shifted by a positive constant term from the blue line. If the series are graphed individually, it is impossible to distinguish whether the series are generated from a random walk or a random walk with drift. However, because both the series contain a stochastic trend, we can still apply differencing to achieve a stationary series.
Similarly, I generate simulated data from a random walk with a drift term of 1 and a deterministic time trend model and plot the graph below.
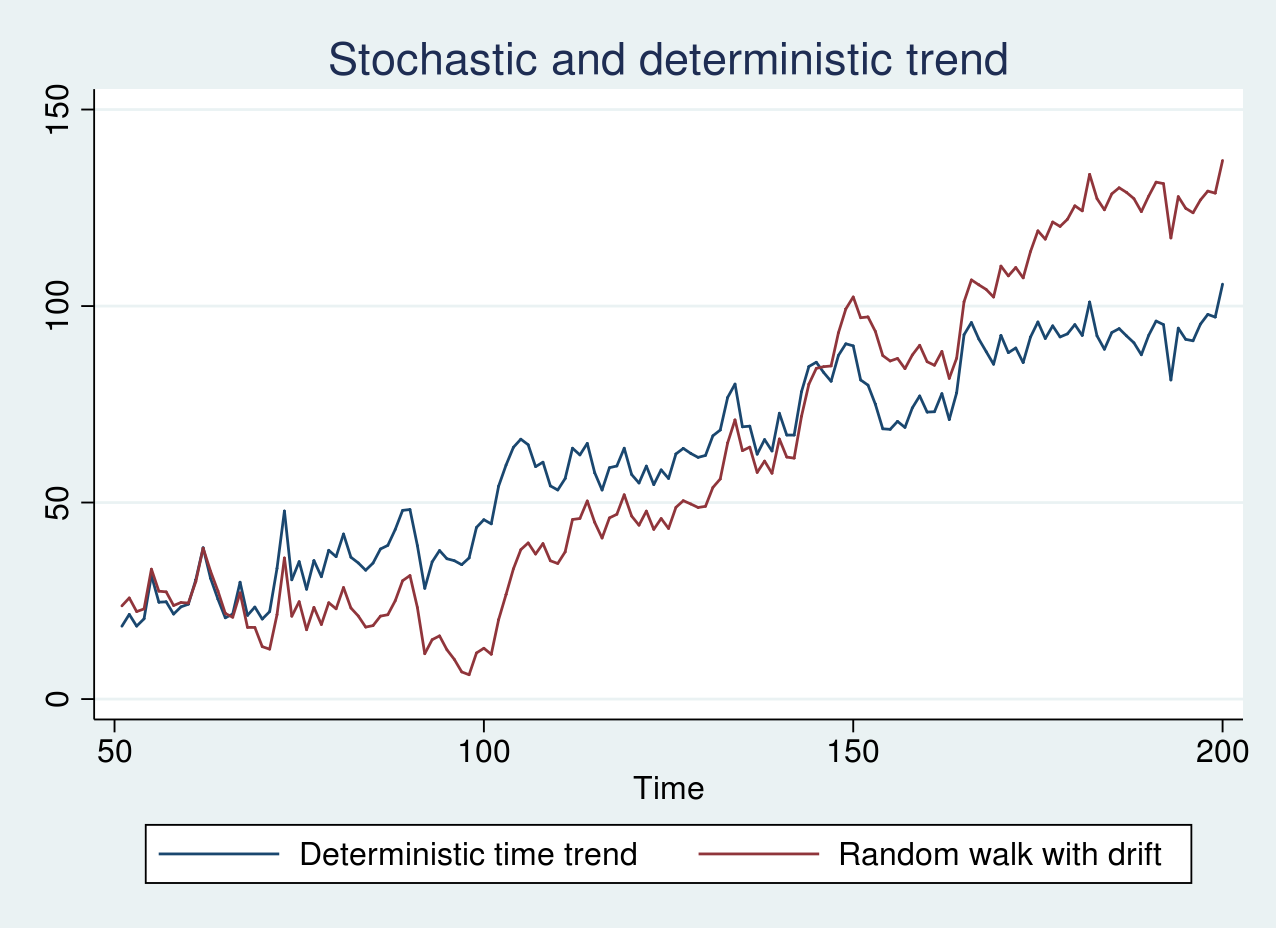
As seen in the graph above, the two series look remarkably similar. The blue line displays an erratic pattern around a constantly increasing trend line. The stochastic trend in the red line, however, increases slowly in the beginning of the sample and rapidly toward the end of the sample. In this case, it is crucial to apply the correct transformation as mentioned earlier.
Furthermore, depending on whether deterministic terms such as constants and time trends are included in the regression leads to different asymptotic distributions for the test statistic. This underscores the importance of clearly specifying the null as well as the alternative hypotheses while performing these tests.
Augmented Dickey–Fuller test
I begin by testing for a unit root in the series yrwd2 and yt, which correspond to data from a random walk with a drift term of 1 and a linear deterministic time trend model, respectively. I use dfuller to perform an ADF test. The null hypothesis I am interested in is that yrwd2 is a random walk process with a possible drift, while the alternative hypothesis posits that yrwd2 is stationary around a linear time trend. Hence, I use the option trend to control for a linear time trend in (4).
. dfuller yrwd2, trend Dickey-Fuller test for unit root Number of obs = 149 ---------- Interpolated Dickey-Fuller --------- Test 1% Critical 5% Critical 10% Critical Statistic Value Value Value ---------------------------------------------------------------------------- Z(t) -2.664 -4.024 -3.443 -3.143 ---------------------------------------------------------------------------- MacKinnon approximate p-value for Z(t) = 0.2511
As expected, we fail to reject the null hypothesis of a random walk with a possible drift in yrwd2. Similarly, I test the presence of a unit root in the yt series.
. dfuller yt, trend Dickey-Fuller test for unit root Number of obs = 149 ---------- Interpolated Dickey-Fuller --------- Test 1% Critical 5% Critical 10% Critical Statistic Value Value Value ---------------------------------------------------------------------------- Z(t) -5.328 -4.024 -3.443 -3.143 ---------------------------------------------------------------------------- MacKinnon approximate p-value for Z(t) = 0.0000
In this case, we reject the null hypothesis of a random walk with drift.
The tests developed in Phillips (1987) and Phillips and Perron (1988) modify the test statistics to account for the potential serial correlation and heteroskedasticity in the residuals. As in the Dickey–Fuller test, a regression model as in (3) is fit with OLS. The asymptotic distribution of the test statistics and critical values is the same as in the ADF test.
pperron performs a PP test in Stata and has a similar syntax as dfuller. Using pperron to test for a unit root in yrwd2 and yt yields a similar conclusion as the ADF test (output not shown here).
GLS detrended augmented Dickey–Fuller test
The GLS–ADF test proposed by Elliott et al. (1996) is similar to the ADF test. However, prior to fitting the model in (4), one first transforms the actual series via a generalized least-squares (GLS) regression. Elliott et al. (1996) show that this test has better power than the ADF test.
The null hypothesis is a random walk with a possible drift with two specific alternative hypotheses: the series is stationary around a linear time trend, or the series is stationary around a possible nonzero mean with no time trend.
To test whether the yrwd2 series is a random walk with drift, I use dfgls with a maximum of 4 lags for the regression specification in (4).
. dfgls yrwd2, maxlag(4) DF-GLS for yrwd2 Number of obs = 145 DF-GLS tau 1% Critical 5% Critical 10% Critical [lags] Test Statistic Value Value Value --------------------------------------------------------------------------- 4 -1.404 -3.520 -2.930 -2.643 3 -1.420 -3.520 -2.942 -2.654 2 -1.638 -3.520 -2.953 -2.664 1 -1.644 -3.520 -2.963 -2.673 Opt Lag (Ng-Perron seq t) = 0 [use maxlag(0)] Min SC = 3.31175 at lag 1 with RMSE 5.060941 Min MAIC = 3.295598 at lag 1 with RMSE 5.060941
Note that dfgls controls for a linear time trend by default unlike the dfuller or pperron command. We fail to reject the null hypothesis of a random walk with drift in the yrwd2 series.
Finally, I test the null hypothesis that yt is a random walk with drift using dfgls with a maximum of 4 lags.
. dfgls yt, maxlag(4) DF-GLS for yt Number of obs = 145 DF-GLS tau 1% Critical 5% Critical 10% Critical [lags] Test Statistic Value Value Value --------------------------------------------------------------------------- 4 -4.013 -3.520 -2.930 -2.643 3 -4.154 -3.520 -2.942 -2.654 2 -4.848 -3.520 -2.953 -2.664 1 -4.844 -3.520 -2.963 -2.673 Opt Lag (Ng-Perron seq t) = 0 [use maxlag(0)] Min SC = 3.302146 at lag 1 with RMSE 5.036697 Min MAIC = 3.638026 at lag 1 with RMSE 5.036697
As expected, we reject the null hypothesis of a random walk with drift in the yt series.
In this post, I discussed nonstationary processes arising because of a stochastic trend, a deterministic time trend, or a combination of both. I illustrated the dfuller, pperron, and dfgls commands for testing the presence of a unit root using simulated data.
The code for generating data from a random walk, random walk with drift, and linear deterministic trend models is provided below.
clear all
set seed 2016
local T = 200
set obs `T'
gen time = _n
label var time "Time"
tsset time
gen eps = rnormal(0,5)
/*Random walk*/
gen yrw = eps in 1
replace yrw = l.yrw + eps in 2/l
/*Random walk with drift*/
gen yrwd1 = 0.1 + eps in 1
replace yrwd1 = 0.1 + l.yrwd1 + eps in 2/l
/*Random walk with drift*/
gen yrwd2 = 1 + eps in 1
replace yrwd2 = 1 + l.yrwd2 + eps in 2/l
/*Stationary around a time trend model*/
gen yt = 0.5 + 0.1*time + eps in 1
replace yt = 0.5 + 0.1*time +0.8*l.yt+ eps in 2/l
drop in 1/50
tsline yrw yrwd1, title("Stochastic trend") /// legend(label(1 "Random walk") /// label(2 "Random walk with drift"))
tsline yt yrwd2, /// legend(label(1 "Deterministic time trend") /// label(2 "Random walk with drift")) /// title("Stochastic and deterministic trend")Lines 1–4 clear the current Stata session, set the seed for the random number generator, define a local macro T as the number of observations, and set it to 200. Lines 5–7 generate the time variable and declare it as a time series. Line 8 generates a zero mean random normal error with standard deviation 5. Lines 10–12 generate data from a random walk model and store them in the variable yrw. Lines 14–16 generate data from a random walk with a drift of 0.1 and store them in the variable yrwd1. Lines 18–20 generate data from a random walk with a drift of 1 and store in the variable yrwd2. Lines 22–24 generate data from a deterministic time trend model and store them in the variable yt. Line 25 drops the first 50 observations as burn-in. Lines 27–33 plot the time series.
Elliott, G. R., T. J. Rothenberg, and J. H. Stock. 1996. Efficient tests for an autoregressive unit root. Econometrica 64: 813–836.
Hamilton, J. D. 1994. Time Series Analysis. Princeton: Princeton University Press.
Phillips, P. C. B. 1987. Time series regression with a unit root. Econometrica 55: 277–301.
Phillips, P. C. B., and P. Perron. 1988. Testing for a unit root in time series regression. Biometrika 75: 335–346.
Stata implements a variety of tests for unit roots or stationarity in panel
datasets with xtunitroot. The Levin–Lin–Chu (2002),
Harris–Tzavalis (1999), Breitung (2000; Breitung and Das 2005),
Im–Pesaran–Shin (2003), and Fisher-type (Choi 2001) tests have as the
null hypothesis that all the panels contain a unit root. The Hadri (2000)
Lagrange multiplier (LM) test has as the null hypothesis that all the panels
are (trend) stationary. Options allow you to include fixed effects and time
trends in the model of the data-generating process.
The assorted tests make different asymptotic assumptions regarding the
number of panels in your dataset and the number of time periods in each
panel. xtunitroot has all your bases covered, including tests
appropriate for datasets with a large number of panels and few time periods,
datasets with few panels but many time periods, and datasets with many
panels and many time periods. The majority of the tests assume that you
have a balanced panel dataset, but the Im–Pesaran–Shin and
Fisher-type tests allow for unbalanced panels.
We have data on the log of real exchange rates for a large panel of
countries for 34 years. Here we apply the Levin–Lin–Chu test to
a subset of data for the G7 countries to examine whether the series
lnrxrate contains a unit root. Because we use the United States as
the numeraire when computing the lnrxrate series, this subset of data
contains six panels.
. webuse pennxrate. xtunitroot llc lnrxrate if g7, lags(aic 10)H0: Panels contain unit roots Number of panels = 6 Ha: Panels are stationary Number of periods = 34 AR parameter: Common Asymptotics: N/T -> 0 Panel means: Included Time trend: Not included ADF regressions: 1.00 lags average (chosen by AIC) LR variance: Bartlett kernel, 10.00 lags average (chosen by LLC)
The header of the output summarizes the test. The null hypothesis is that
the series contains a unit root, and the alternative is that the series is
stationary. As the output indicates, the Levin–Lin–Chu test
assumes a common autoregressive parameter for all panels, so this test does
not allow for the possibility that some countries’ real exchange rates
contain unit roots while other countries’ real exchange rates do not.
Each test performed by xtunitroot also makes explicit the assumed
behavior of the number of panels and time periods. The
Levin–Lin–Chu test with panel-specific means but no time trend
requires that the number of time periods grow more quickly than the number
of panels, so the ratio of panels to time periods tends to zero. The
test involves fitting an augmented Dickey–Fuller regression for each
panel; we requested that the number of lags to include be selected based on
the AIC with at most 10 lags. To estimate the long-run variance of the
series, xtunitroot by default uses the Bartlett kernel using 10 lags
as selected by the method proposed by Levin, Lin, and Chu.
The Levin–Lin–Chu bias-adjusted t statistic is −4.0277,
which is significant at all the usual testing levels. Therefore, we reject
the null hypothesis and conclude that the series is stationary. When we use the
demean option to xtunitroot to remove cross-sectional means from
the series to mitigate the effects of cross-sectional correlation, we obtain
a test statistic that is significant at the 5% level but not at the 1% level.
Because the Levin–Lin–Chu test requires that the ratio of the
number of panels to time periods tend to zero asymptotically, it is not well
suited to datasets with a large number of panels and relatively few time
periods. Here we use the Harris–Tzavalis test, which assumes that the
number of panels tends to infinity while the number of time periods is
fixed, to test whether lnrxrate in our entire dataset of 151
countries contains a unit root:
. xtunitroot ht lnrxrateH0: Panels contain unit roots Number of panels = 151 Ha: Panels are stationary Number of periods = 34 AR parameter: Common Asymptotics: N -> Infinity Panel means: Included T Fixed Time trend: Not included
Here we find overwhelming evidence against the null hypothesis of a unit
root and therefore conclude that lnrxrate is stationary.
References
- Breitung, J. 2000.
- The local power of some unit root tests for panel
data. Advances in Econometrics, Volume 15: Nonstationary
Panels, Panel Cointegration, and Dynamic Panels, ed.
B. H. Baltagi, 161–178. Amsterdam: JAY Press.
- Breitung, J., and S. Das. 2005.
- Panel unit root tests under
cross-sectional dependence. Statistica Neerlandica 59:
414–433.
- Choi, I. 2001.
- Unit root tests for panel data. Journal of International
Money and Finance 20: 249–272.
- Hadri, K. 2000.
- Testing for stationarity in heterogeneous panel data.
Econometrics Journal 3: 148–161.
- Harris, R. D. F., and E. Tzavalis. 1999.
- Inference for unit roots in
dynamic panels where the time dimension is fixed.
Journal of Econometrics 91: 201–226.
- Im, K. S., M. H. Pesaran, and Y. Shin. 2003.
- Testing for unit roots in
heterogeneous panels. Journal of Econometrics 115: 53–74.
- Levin, A., C.-F. Lin, and C.-S. J. Chu. 2002.
- Unit root tests in panel
data: Asymptotic and finite-sample properties. Journal of
Econometrics 108: 1–24.
")




")