
- Start in Qemu
- Start in KVM
- Cleaning up Boot partition on Ubuntu 16
- The command line way to clean up /boot partition
- Check the partition sizes with lsblk
- Compiling
- What Causes This?
- Even Better — How to recover your instance.
- IMPORTANT: ensure not to select the option to delete the boot disk. Otherwise, the disk will get removed permanently!!
- Kernel panic not syncing
- Synopsis
- Analysis
- Resolution
- How to salvage your current situation?
- Выводы
- Помогла статья? Подписывайся на telegram канал автора
Start in Qemu
sudo qemu-system-x86_64 -m 1024M -hda /var/lib/libvirt/images/DEbian.img -enable-kvm -initrd /home/username/compiled_kernel/initrd.img-3.2.46 -kernel /home/username/compiled_kernel/bzImage -append "root=/dev/sda1 console=ttyS0" -nographic -redir tcp:2222::22 -cpu host -smp cores=20
1
при запуске выдаёт:
Please append a correct «root=» boot option; here are available partitions:
SATA и поддержка ext4 включены в ядро, если прописать root=0803, то, кажется, он пишет unknown-block(8,3).
Из просмотренных в гугле решений особо ничто не помогло. Задавал подобный вопрос в другой теме, но так и не нашёл решения. Если нужны ещё данные, скажите какие.
Подскажите пожалуйста, что может быть не так.
0
1
Сама ошибка:
VFS: Cannot open root device "sda1" or unkown-block(0,0)
Please append a correct "root=" boot option
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)grub.cfg:
menuentry "Gentoo Base System release 2.0.3 (on /dev/sda1)" --class gnu-linux --class gnu --cla$ insmod part_msdos insmod ext2 set root='(/dev/sda,msdos1)' search --no-floppy --fs-uuid --set=root 36ac94fc-b2d6-433b-95ef-05874c15eac0 linux /boot/kernel-x86-3.0.4-gentoo-r1 root=/dev/sda1
}fstab:
/dev/sda1 / ext4 noatime 0 1
/dev/sda7 none swap sw 0 0
/dev/cdrom /mnt/cdrom auto noauto,ro 0 0Ядро kernel-x86-3.0.4-gentoo-r1, поддержка ext4 включена
grub убунтовский.
Где я ошибся?
0
1
Приветсвую Вас уважаемые!!!!То что Вы сейчас прочитаете, многие сочтут за маразм и скажут на х..р это нужно вообще было делать, ставить столько ОС. Но факт остается фактом.Столько ОС нужно для работы и разных целей!! В общем на ноуте стоит 4 пингвина. А именно:
1.OpenSuse 15
2.Manjaro 17.1
3.Ubuntu 18.04
4.Kali 18.2
Основной загрузчик стоит от OpenSuse
По началу все нормально работало, но скорее всего после update Manajro. При выборе в загрузчике Manjaro получаю:
kernel panic — not syncing: VFS: unable to mount root fs on unknown — block(0,0)
Все остальные ОС загружаются нормально.
При выборе F12 другого загрузчика например от Ubuntu, то Manjaro загружается без каких либо проблем.
Как исправить эту досаду!!!
Искал в просторах инета как это исправить , но толком ни чего ни накопал!!!
Помогите пожалуйста!!!Единственная просьба не надо советовать переустановить ОС!!!
Надеюсь на Ваше понимание!!! Благодарю!!!!
0
0
В последней убунте зачем-то перешли на grub2, хотя разница в скорости загрузки не ощущается. Как править конфигурационные файлы для генератора grub-mkconfig, пока не разобрался, поэтому в конец просто приписал по образцу предыдущих записей:
menuentry "Gentoo (on /dev/sda5)" { insmod ext2 set root=(hd0,2) search --no-floppy --fs-uuid --set a1390839-b48d-4116-a166-4683c905d6c9 linux /kernel-2.6.32-gentoo-r1 root=/dev/sda5 ro quiet video=uvesafb:1024x768-32,mtrr:3,ywrap
}/boot находится на /dev/sda2, / — sda5.
С ядром без -r1 все работало, правда, текущее собирал с нуля, но уже несколько раз перепроверил — вроде все опции совпадают.
Если в параметрах ставить root=/dev/sda5, то пишет:
kernel panic - not syncing : VFS: unable to mount root FS on unknown-block(0,0), а если тот же диск передавать в качестве real_root, то почему-то:
kernel panic - not syncing : VFS: unable to mount root FS on unknown-block(8,5)Непонятно, что-то не так с ядром, переданным параметром или загрузчиком?
You are missing the initramfs for that kernel. Choose another kernel from the grub menu, or run update-initramfs -u -k version to generate the initrd for version then update-grub.
Boot to a LiveCD, select Try Ubuntu and then open a a terminal. Run the following:
sudo fdisk -lThis will show us what partitions are available. You need to look for your main Ubuntu partition. On most fresh-installed systems this will be sda1 but it really could be anything. Substitude sda1 in the following with whatever you decide is right in the fdisk output.
sudo mount /dev/sda1 /mnt
sudo mount --bind /dev /mnt/dev
sudo mount --bind /proc /mnt/proc
sudo mount --bind /sys /mnt/sys
sudo mount --bind /run /mnt/run
sudo chroot /mnt And now you can run update-initramfs and update-grub with out errors and that should fix everything. Reboot without the CD in and you should land on your Ubuntu desktop.
Additionally, after the chroot:
cp -r /usr/lib/i386-linux-gnu/pango /usr/lib/
update-initramfs -u -k 2.6.38-8-generic #(or your version)
update-grub2(You can find a list if installed kernels using: dpkg --list | grep linux-image)
And reboot your system
Today one of the guys on my development team ran into an old problem on Linux, the good and old Kernel panic … This time it was after updating Ubuntu 16.04 internals.
After doing the reboot, there it was, the old good linux scaring n00bies away:

This is an old problem and usually, depending on the tooling you have around it, it can be quite time-consuming to figure a way out if you are not experienced on Linux.
The problem originated because he installed updates on Ubuntu, one after another during many months of usage, until a day … nothing special, he updated once again and boom!!! The updates caused the /boot partition to be left with no space, and this caused the grub to be blocked when trying to mount the root fs. The solution is simple: just to remove the old kernel images and run a quick cleanup.
I believe if a piece of software or program is not clear enough for an average person to understand and solve, than its broken and it should be properly fixed or at least documented until it can be fixed permanently.
Start your Ubuntu with shift pressed until you see the recover screen, choose recovery mode:

I’m trying to run orange-pi emulation with self-build linux kernel by this commands:
ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- make mrproper
ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- make sunxi_defconfig
ARCH=arm CROSS_COMPILE=arm-linux-gnueabi- makeand system generated with buildroot using default orangepi_zero_defconfig.
Trying to run emulation by this command:
qemu-system-arm -M orangepi-pc -nic user -nographic \
-kernel linux/arch/arm/boot/zImage \
-append 'root=/dev/mmcblk0 panic=1 rootfstype=ext4 rw' \
-dtb linux/arch/arm/boot/dts/sun8i-h3-orangepi-pc.dtb \
-drive file=sdcard.img,format=raw,if=sd \
-no-rebootIn boot logs i see this:
[ 5.337453] List of all partitions:
[ 5.338217] b300 2097152 mmcblk0
[ 5.347713] driver: mmcblk
[ 5.347884] b301 61440 mmcblk0p1 4d1f495b-d662-4b1d-818a-591ebed99bac
[ 5.348161]
[ 5.348330] No filesystem could mount root, tried:
[ 5.349117] ext4
[ 5.349219]
[ 5.349738] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(179,0) Full log on Google Drive.
zImage
dtb file
Emulation stops with reboot message.
I recently bought a new computer and I am experiencing problems while trying to install Linux.
Things I have tried:
A variety of distributions:
- Ubuntu;
- Elementary OS;
- Crunchbang++;
- Manjaro; and
- Antergos
Every time I try to boot the system either locks and nothing happens or it returns me the same error:
I have also tried both booting using an USB flash drive and using CD/DVD. And I have tried booting using Legacy and UEFI.
In the last days I have been to a variety of websites and articles, mainly:
- http://itslaves.com/web/guest/forum/message_boards/message/66813
- https://askubuntu.com/questions/41930/kernel-panic-not-syncing-vfs-unable-to-mount-root-fs-on-unknown-block0-0
I have also searched the StackExchange network but with no success.
The problem with the purposed solutions is:
a) They are for people who already have Linux in their machines and have corrupted their file-systems;
b) For one to execute the presented solutions a Live CD is needed and I can’t even boot Linux so this becomes impossible for me.
My motherboard is Gigabyte B85M-D3PH and my processor is an i5-4460, in case this information helps in any way.
Posting here is my last resort.
I try to get this running and don’t know what I’m doing wrong. I have created an Debian.img (disk in raw format with virtual device manager — gui to libvirt I guess) and installed debian with no troubles. Now I want to get this running with a self compiled kernel. I copied the .config-file from my working (virtual) debian and made no more changes at all. This is what I do:
qemu-system-x86_64 -m 1024M -kernel /path/to/bzImage -hda /var/lib/libvirt/images/Debian.img -append "root=/dev/sda1 console=ttyS0" -enable-kvm -nographicBut during boot I always get this error message.
[ 0.195285] Initializing network drop monitor service [ 0.196177] List of all partitions: [ 0.196641] No filesystem could mount root, tried: [ 0.197292] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 0.198355] Pid: 1, comm: swapper/0 Not tainted 3.2.46 #7 [ 0.199055] Call Trace: [ 0.199386] [<ffffffff81318c30>] ? panic+0x95/0x19e [ 0.200049] [<ffffffff81680f7d>] ? mount_block_root+0x245/0x271 [ 0.200834] [<ffffffff8168112f>] ? prepare_namespace+0x133/0x169 [ 0.201590] [<ffffffff81680c94>] ? kernel_init+0x14c/0x151 [ 0.202273] [<ffffffff81325a34>] ? kernel_thread_helper+0x4/0x10 [ 0.203022] [<ffffffff81680b48>] ? start_kernel+0x3c1/0x3c1 [ 0.203716] [<ffffffff81325a30>] ? gs_change+0x13/0x13What I’m doing wrong? Please someone help. Do I need to pass the -initrd option? I tried this already but had no luck yet.
asked Jun 21, 2013 at 18:53

1
I figured it out by myself. Some time has passed, but as I recall the solution was to provide an initial ramdisk. This is how I got it working with hardware acceleration.
This is generally what happens when a Linux kernel fails to find a root filesystem. The message «Unable to mount root fs on unknown-block(0,0)» means essentially «I don’t even know what kind of disk the root filesystem is supposed to be on.» If the end of message said something other than unknown-block(0,0), then it would mean «I found the device that is supposed to contain the root filesystem, but I do not understand the contents, maybe there’s something wrong with it?»
The kernel version 3.13.0-32-generic indicates this virtual appliance is based on a rather old version of Ubuntu: according to this answer on AskUbuntu.SE, this kernel version belonged to Ubuntu 14.04.
Typically, such virtual appliances come with recommended settings for the virtualization software. If you just added the virtual disk image into a VirtualBox VM configured for a modern version of Ubuntu, no wonder it did not work!
The virtual hard disk controller the VirtualBox provides to the VM is probably currently of a type that is too new, so the virtual Ubuntu 14.04 won’t recognize it. You might have to switch to a different virtual hard disk controller type in VirtualBox settings for this VM.
There are several virtual hard disk controller options in VirtualBox. You might have to think about which of those controller types existed back in year 2014 when that version of Ubuntu was released: trying NVMe or modern VirtIO options with such an old virtual appliance is probably going to be futile. Try the SAS or SATA options first, then SCSI, and finally IDE if nothing else works.
So I’ve been at this for a while and have been poking around for an answer for a few days, and figure it’s about time to ask for help. I am running Ubuntu 10.10 in VMWare Fusion, and have downloaded a copy of the 3.2 kernel and built it with all default settings. When I try to boot into the new kernel after a call to make install, I get the following message:
[ 1.581916] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
[ 1.582260] Pid: 1, comm: swapper/0 Not tainted 3.2.4 #1
[ 1.582444] Call Trace:
[ 1.582552] [<ffffffff815e7447>] panic+0x91/0x1a7
[ 1.582666] [<ffffffff815e75c5>] ? printk+0x68/0x6b
[ 1.582799] [<ffffffff81ad2152>] mount_block_root+0x1ea/0x29e
[ 1.582929] [<ffffffff81ad225c>] mount_root+0x56/0x5a
[ 1.583047] [<ffffffff81ad23d0>] prepare_namespace+0x170/0x1a9
[ 1.583178] [<ffffffff81ad16f7>] kernel_init+0x144/0x153
[ 1.583304] [<ffffffff815f45f4>] kernel_thread_helper+0x4/0x10
[ 1.583436] [<ffffffff81ad15b3>] ? parse_early_options+0x20/0x20
[ 1.583570] [<ffffffff815f45f0>] ? gs_change+0x13/0x13Which used to appear on every reboot. I found that if I changed the VM’s harddrive type, I could get GRUB to boot at least, but the message above comes up if I try to load the newly compiled kernel. The old kernel works as before. I have checked and I have compiled in support for ext4, which is the fs my root is running. I have also tried generating an initrd file with a call to «sudo update-initramfs -c -k 3.2.4», but to no avail.
The compilation, I think, was pretty standard:
make menuconfig
make
make modules_install
make install
update-grub
rebootWere the general steps. In terms of options, I basically took the default on everything. In case it’s pertinent, my fstab looks like this:
proc /proc proc nodev,noexec,nosuid 0 0
#UUID=c75eddd9-f4fa-49be-927b-8c2da7074135 / ext4 errors=remount-ro 0 1
/dev/sda1 / ext4 defaults 0 1
#UUID=5bc6915e-fdfa-479a-885f-ea03cb14f9cd none swap sw 0 0
/dev/sda5 none swap sw 0 0
/dev/fd0 /media/floppy0 auto rw,user,noauto,exec,utf8 0 0Where I’ve tried it with both UUID’s and /dev/sd* notation. Any help or advice would be much appreciated, as it’s gotten quite frustrating.
Thank you.
I faced this problem, as linux headers were getting updated, and electricity was gone.
I recovered as below,
Go to grub menu and select
advanced options > select a previous kernel and boot,
Once you get terminal, run below command,
sudo dpkg --configure -ahere from man page of dpkg,
--configure package...|-a|--pending Configure a package which has been unpacked but not yet configured. If -a or --pending is given instead of package, all unpacked but unconfigured packages are configured. To reconfigure a package which has already been configured, try the dpkg-reconfigure(8) command instead. Configuring consists of the following steps: 1. Unpack the conffiles, and at the same time back up the old conffiles, so that they can be restored if something goes wrong. 2. Run postinst script, if provided by the package.logs as below,
Setting up linux-image-4.15.0-76-generic (4.15.0-76.86) ...
Processing triggers for initramfs-tools (0.130ubuntu3.9) ...
update-initramfs: Generating /boot/initrd.img-4.15.0-74-generic
Processing triggers for linux-image-4.15.0-76-generic (4.15.0-76.86) ...
/etc/kernel/postinst.d/dkms: * dkms: running auto installation service for kernel 4.15.0-76-generic ...done.
/etc/kernel/postinst.d/initramfs-tools:
update-initramfs: Generating /boot/initrd.img-4.15.0-76-generic
/etc/kernel/postinst.d/zz-update-grub:
Sourcing file `/etc/default/grub'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.15.0-76-generic
Found initrd image: /boot/initrd.img-4.15.0-76-generic
Found linux image: /boot/vmlinuz-4.15.0-74-generic
Found initrd image: /boot/initrd.img-4.15.0-74-generic
Found linux image: /boot/vmlinuz-4.15.0-72-generic
Found initrd image: /boot/initrd.img-4.15.0-72-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
Found Windows 7 on /dev/sda1
doneand voila, newer package that was downloaded but not configured is working.
I want to install ubuntu 14.04. When i press «setup ubuntu» the error
«end kernel panic — not syncing: vfs: unable to mount root fs on unknown block(2,0)» is appears
Even if do not do anything this error appears after some seconds.
I have 3 DISKs. Two of them is NTFS, 3th one is FAT32 (another HDD). Fat32 is for Ubuntu OS.
Searched for the solutions. However answers was about typing some codes (promts) on ubuntu. Recently in my computer windows 7 is installed.
asked Mar 3, 2015 at 13:07

isifzadeisifzade
4531 gold badge5 silver badges14 bronze badges
3
I solved this problem by changing the ubuntu setup containing usb’s format from NTFS to FAT32
On Windows, go to My Computer, right click on the USB disk on which you want to add the Ubuntu set-up, then select format and a new window will open. Change file type from NTFS to FAT32 and click start.
After this process, you can continue your Ubuntu Installation with USB

Fabby
33.8k38 gold badges93 silver badges191 bronze badges
answered Mar 3, 2015 at 16:13
isifzadeisifzade
4531 gold badge5 silver badges14 bronze badges
5
This apparently can also happen after a bad install. The simplest thing to do is to remove your usb from the target system, format it again (via a source system) to FAT32, recreate your Live USB and then rerun install. This fixed the issue for me and installed successfully for Ubuntu 15.04
answered Jun 5, 2015 at 13:19

jerodjerod
612 silver badges1 bronze badge
1
Regarding the previous answer, I would like to share my recent experience with this same condition/error message.
I passed through it while trying to install the Ubuntu 14.04.2 LTS for Desktop from a USB media. In my case the previous message did not make any sense because my USB media was formatted with FAT32.
After a short research, reading of this version requirements I perceived that my computer did not fit the minimal amount of memory required (3 — 4 GB). As my desktop just have 2 GB of RAM, I downloaded to 32-bits version and the installation was an accomplished without further problems.
Best regards.
Murilo pugliese.
answered May 5, 2015 at 12:55

2
Я столкнулся с этой проблемой, так как заголовки linux обновлялись, и электричество пропало. Я восстановился, как показано ниже,
Перейдите в меню grub и выберите дополнительные параметры> выберите предыдущее ядро и загрузитесь,
Как только вы получите терминал, запустите команду ниже,
sudo dpkg --configure -aздесь со страницы руководства dpkg,
--configure package...|-a|--pending Configure a package which has been unpacked but not yet configured. If -a or --pending is given instead of package, all unpacked but unconfigured packages are configured. To reconfigure a package which has already been configured, try the dpkg-reconfigure(8) command instead. Configuring consists of the following steps: 1. Unpack the conffiles, and at the same time back up the old conffiles, so that they can be restored if something goes wrong. 2. Run postinst script, if provided by the package.журналы, как показано ниже,
Setting up linux-image-4.15.0-76-generic (4.15.0-76.86) ...
Processing triggers for initramfs-tools (0.130ubuntu3.9) ...
update-initramfs: Generating /boot/initrd.img-4.15.0-74-generic
Processing triggers for linux-image-4.15.0-76-generic (4.15.0-76.86) ...
/etc/kernel/postinst.d/dkms: * dkms: running auto installation service for kernel 4.15.0-76-generic ...done.
/etc/kernel/postinst.d/initramfs-tools:
update-initramfs: Generating /boot/initrd.img-4.15.0-76-generic
/etc/kernel/postinst.d/zz-update-grub:
Sourcing file `/etc/default/grub'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.15.0-76-generic
Found initrd image: /boot/initrd.img-4.15.0-76-generic
Found linux image: /boot/vmlinuz-4.15.0-74-generic
Found initrd image: /boot/initrd.img-4.15.0-74-generic
Found linux image: /boot/vmlinuz-4.15.0-72-generic
Found initrd image: /boot/initrd.img-4.15.0-72-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
Found Windows 7 on /dev/sda1
doneи вуаля, новый пакет, который был загружен, но не настроен, работает.
Словил сегодня неприятную ошибку на web сервере под CentOS 7. Уже начал потихоньку кирпичи откладывать, но в итоге отделался легким испугом. Поделюсь с вами решением этой неприятной ошибки, когда система просто не загружается.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужно пройти вступительный тест.
Утро сисадмина не всегда начинается с кофе. Сегодня утром мне пишет один заказчик, а я как раз кофе наливал, что у него какие-то проблемы с web сервером — не загружаются картинки через админку. Захожу, проверяю, в самом деле. Движок пишет, что не может найти tmp папку. Ладно, думаю, ерунда какая-то, сейчас разберемся.
Захожу на сервер, смотрю логи сайта — ошибок нет. Смотрю системные логи за последнее время, тоже ничего особенного. Проверяю аптайм виртуалки — 370 дней. Думаю, пришло время для ребута. На виртуалке сайты не очень критичные, можно перезагрузить сервак. Думаю, что совмещу приятное с полезным — установлю последние обновления (ставятся регулярно, но без ребута) и перезагружусь.
Обновления не установились. Не запомнил, какая конкретно ошибка, но yum поругался на нехватку памяти. К слову, виртуалка была сильно зажата по памяти, потому что сайты там не сильно критичные жили, им приоритет низкий. Пошел на всякий случай на гипервизор и посмотрел консоль виртуальной машины. Там куча ошибок на нехватку памяти. Приходил OOM Killer и выключал Mysql. Удивился, что не было оповещений от мониторинга о нехватки памяти. Зашел в Zabbix, он показывает, что 200-300 мб памяти всегда были доступны. Надо будет отдельно разбираться, почему OOM Killer так рано прибивал Mysql сервер.
В общем, картинка вроде как в голове сложилась. Серверу не хватало памяти, он из-за этого начал глючить. Надо его перезагрузить и поднастроить, либо памяти добавить. Перезагружаю сервер. Жду… Не поднимается. Смотрю в консоль и начинаю немного мандражировать. Виртуалка не загружается, там ошибка:
Hi i recently installed ubuntu 8.04 on my desktop and in the upgrades menu i gave upgrade to ubuntu 10.04.3 LTS but after installing it started giving me this error
[ 0.694063] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)Please help as i am new to ubuntu and also get back to me for additional info if required.
asked Mar 5, 2013 at 1:51

I was getting this when attempting to install 13.10 and it turned out to be incorrect usb formatting in my case. my usb stick was formatted to NTFS and I would get this error every time I tried to boot from it. Once I formatted the usb stick to fat32 the installation worked like a charm.
Hope it helps!
answered Mar 31, 2014 at 21:35

I will give you one option I know would work, but it involves booting from a full install CD / ISO and using rescue mode to gain access to your boot volume and Grub. Here is what you would do to start.
- Boot from a full install CD and choose the menu option for rescue mode.
- go to your boot volume where Grub is located, usually in rescue mode your old file system is on /mnt/sysimage
- Find and edit /mnt/sysimage/boot/grub.conf to increase the timeout and unhide the menu using the following commands within grub.conf.
Grub.conf
timeout=20 #hiddenmenuReboot from the hdd this time and when grub shows up choose the previous working kernel and that should boot. You will be back on a previous kernel and possibly release, but you will have a system to at least back up and retry the upgrade.
answered Mar 5, 2013 at 14:57

apesaapesa
11.8k6 gold badges37 silver badges42 bronze badges
5
The same problem happened to me and here is the easiest way to solve this problem so as to get a bootable system. The first thing you need to do is, try to boot in a recovery mode as explained here. Once you get the root prompt, execute the following commands.
$ sudo update-initramfs -u
$ sudo update-grub2
$ sudo reboot Hope this helps.

answered Mar 16, 2017 at 22:57

Very old question, but I’m going to leave my answer here as it showed up the highest in Google when searching for solution.
While upgrading from 19.04 to 19.10, the screen blacked out and the system went to full halt. Afterwards the booting failed for each available Kernel version I had.
In my case, the solution was to let Ubuntu download missing files due to failed upgrade. To do so, try to boot in recovery mode and select Repair broken packages option if available. This might take a while, but afterwards all started working.
answered Oct 28, 2019 at 20:45

DanDan
4533 silver badges12 bronze badges
Start in KVM
Kernal path: /home/username/compiled_kernel/bzImage
Initrd path: /home/username/compiled_kernel/initrd.img-3.2.46
Kernel arguments: root=/dev/sda1
Hope this helps if someone has the same issues.
answered Nov 12, 2014 at 15:05
KonstantinKonstantin
3311 gold badge3 silver badges8 bronze badges
This is for AArch64 (arm64) on QEMU case.
I was following this good tutorial: https://ibug.io/blog/2019/04/os-lab-1/
In my case I was met with this error message:
---[ end Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(1,0) ]---I did mknod dev/ram b 1 0 in the initrd.
Later I noticed there was an error message above that line implying the kernel didn’t support the ram disk. So I edited .config and set these items:
CONFIG_BLK_DEV_RAM=y
CONFIG_BLK_DEV_RAM_COUNT=1
CONFIG_BLK_DEV_RAM_SIZE=131072 (= 128MB, the number is in unit of 1014B)And then the problem was gone! The initrd was mounted on /dev/ram and the first init process ran well.
It turns out running make defconfig didn’t set thses values by default for me.
answered Feb 22, 2021 at 1:11

Chan KimChan Kim
4,42110 gold badges40 silver badges88 bronze badges
maybe your system image file is bad and can not be mounted.
You may try these command to mount the image file and check if it is a valid root file system for linux.
losetup /dev/loop0 /var/lib/libvirt/images/Debian.img
kpartx -av /dev/loop0
mount /dev/mapper/loop0p1 /mnt/tmpanswered Oct 30, 2013 at 2:45

HouchengHoucheng
2,48623 silver badges31 bronze badges
The most likely thing is that the kernel doesn’t know the correct device to boot from.
You can supply this explicitly from the qemu command line. So if the root is on partition 2, you can say:
qemu -kernel /path/to/bzImage \ -append root=/dev/sda2 \ -hda /path/to/hda.img \ . . .Notice I use /dev/sda2 even though the disk is IDE. Even virtual machines seem to use SATA nowadays.
The other possibilities are that as @Houcheng says, your root FS is corrupted, or else that the kernel does not have that particular FS type built in. But I think you would get a different error if that were the case.
answered Nov 1, 2014 at 7:05

Adrian RatnapalaAdrian Ratnapala
5,3071 gold badge28 silver badges39 bronze badges
QEMU version
QEMU emulator version 2.5.0 (Debian 1:2.5+dfsg-5ubuntu10.11), Copyright (c) 2003-2008 Fabrice Bellardrunning build-root 4.9.6 with the following arguments to be passed
qemu-system-x86_64 -kernel output/images/bzImage -hda output/images/rootfs.qcow2 -boot c -m 128 -append root=/dev/sda -localtime -no-reboot -name rtlinux -net nic -net user -redir tcp:2222::22 -redir tcp:3333::3333was accepting only /dev/sda as an option for the root fs to mount (it will show you a little hint for the root fs option once it will boot and hang with the following error):
VFS: Cannot open root device "hda" or unknown-block(0,0): error -6
Please append a correct "root=" boot option; here are the available partitions:
0800 61440 sda driver: sdanswered May 10, 2017 at 8:53

Oleg KokorinOleg Kokorin
1,8572 gold badges14 silver badges25 bronze badges
I had a similar problem. Trying to run a full-system emulation of both Ubuntu and Linaro minimal (from the gem5 website) under a 64-bit kernel, with the original starter_fs.py script, gives me this kernel panic:
[ 0.224367] List of all partitions:
[ 0.224394] fe00 1048320 vda
[ 0.224397] driver: virtio_blk
[ 0.224440] fe01 1048288 vda1 00000000-01
[ 0.224441]
[ 0.224480] No filesystem could mount root, tried:
[ 0.224481] ext3
[ 0.224510] ext4
[ 0.224524] ext2
[ 0.224537] squashfs
[ 0.224551] vfat
[ 0.224566] fuseblk
[ 0.224579]
[ 0.224606] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(254,0)
[ 0.224656] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 4.18.0+ #1
[ 0.224692] Hardware name: V2P-CA15 (DT)
[ 0.224717] Call trace:
[ 0.224741] dump_backtrace+0x0/0x1c0
[ 0.224765] show_stack+0x14/0x20
[ 0.224790] dump_stack+0x8c/0xac
[ 0.224812] panic+0x130/0x288
[ 0.224836] mount_block_root+0x22c/0x294
[ 0.224861] mount_root+0x140/0x174
[ 0.224884] prepare_namespace+0x138/0x180
[ 0.224910] kernel_init_freeable+0x1c0/0x1e0
[ 0.224939] kernel_init+0x10/0x108
[ 0.224961] ret_from_fork+0x10/0x18
[ 0.224987] Kernel Offset: disabled
[ 0.225009] CPU features: 0x21c06492
[ 0.225032] Memory Limit: 2048 MB
[ 0.225056] ---[ end Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(254,0) ]---Weird thing is that, few weeks ago, it worked like a charm. The problem lying into the specification of the root partition, on the kernel command line. In the starter_fs.py, change this line:
"root=/dev/vda",
By this:
"root=/dev/vda1",
You can see that before, the VirtIO block device was specified. The kernel wants a partition, not a block device. Then, you can run gem5:
build/ARM/gem5.opt -configs/example/arm/starter_fs.py —cpu=»hpi» —num-cores=1 —disk-image=»linaro-minimal-aarch64.img» —kernel=»vmlinux.arm64″
And for me, the kernel panic is gone and I am able to boot my system again:
[ 0.228847] EXT4-fs (vda1): mounted filesystem without journal. Opts: (null)
[ 0.228906] VFS: Mounted root (ext4 filesystem) on device 254:1.
[ 0.229539] devtmpfs: mounted
[ 0.229792] Freeing unused kernel memory: 448K
INIT: version 2.88 booting
[ 0.234168] random: fast init done
Starting udev
[ 0.277039] udevd[715]: starting version 182
[ 0.411534] EXT4-fs (vda1): re-mounted. Opts: block_validity,delalloc,barrier,user_xattr
Starting Bootlog daemon: bootlogd.
[ 0.426573] random: dd: uninitialized urandom read (512 bytes read)
Populating dev cache
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.all.rp_filter = 1
hwclock: can't open '/dev/misc/rtc': No such file or directory
Mon Jan 27 08:00:00 UTC 2014
hwclock: can't open '/dev/misc/rtc': No such file or directory
INIT: Entering runlevel: 5
Configuring network interfaces... ifconfig: SIOCGIFFLAGS: No such device
Starting rpcbind daemon...rpcbind: cannot create socket for udp6
rpcbind: cannot create socket for tcp6
done.
rpcbind: cannot get uid of '': Success
creating NFS state directory: done
starting statd: done
Starting auto-serial-console: done
Stopping Bootlog daemon:
bootlogd.
Last login: Mon Jan 27 08:00:00 UTC 2014 on tty1
INIT: no more processes left in this runlevel
root@genericarmv8:~# id
id
uid=0(root) gid=0(root) groups=0(root)
root@genericarmv8:~#@ED6E0F17 thanks for the suggestions. Following worked to make sda7 partition bootable again. Regarding gparted, i think it is using fsck, so i wanted to try to fix it with basic tools that are already part of the Raspbian 10, so i did this:
in /boot/cmdline.txt set root to be SD card, not my external drive sda. The grub boot line was missing «fsck.mode=force fsck.repair=yes» parameters btw, maybe it means that auto mode is used, but even when i forced it using that parameters later, it was unable to repair the invalid superblock issue of the /dev/sda7.
So RPi booted from SD and via SSH i ran:
lsblk
i see external drive is attached, so i tried to unmount root partition on it and scan it:
umount /dev/sda
sudo fsck -v /dev/sda
Found a dos partition table in /dev/sda
dmesg command outputs:
tried:
sudo e2fsck -b 8193 /dev/sda
sudo e2fsck -b 32768 /dev/sda
but it continue to output same error as fsck command above
sudo mke2fs -n /dev/sda
Then i risked and ran command:
sudo fsck -v -b 32768 /dev/sda7
i hold enter for maybe 30 seconds confirming tons of prompts of fixing «Free inodes count wrong for group xy».
result:
root: ***** FILE SYSTEM WAS MODIFIED *****
155391 inodes used (2.17%, out of 7151616) 837 non-contiguous files (0.5%) 67 non-contiguous directories (0.0%) # of inodes with ind/dind/tind blocks: 0/0/0 Extent depth histogram: 142377/34 25735444 blocks used (89.97%, out of 28605813) 0 bad blocks 2 large files 128513 regular files 13704 directories 7 character device files 0 block device files 0 fifos 1155 links 13149 symbolic links (12956 fast symbolic links) 9 sockets
when mounting /dev/sda, it shows wrong fs type error (likely i had to use not sda but sda7)
then i installed gparted (apt install gparted) and ran it in GUI mode, selected sda drive and clicked sda7 partition and selected to check it, it ran: e2fsck -f -y -v -C 0 /dev/sda7
(later i found that this e2fsck command alone is sufficing to fix the issue described on this page). I am able to mount root partition of the external drive:
sudo mount /dev/sda7 /mnt/
and see contents and when i added /dev/sda7 into root boot parameter of the /boot/cmdline.txt it now boots OK.
I would welcome feedback. To close this issue, i am wondering if Raspbian can be made to automatically check FS at boot using e2fsck -f -y -v -C 0 /dev/sda7 to repair invalid super block?
После попытки обновления с 10.10 до 11.04, казалось, все шло хорошо до перезагрузки. Это сообщение об ошибке, что появляется:
Kernel Panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)Как мы это исправим?
Ответы:
Вам не хватает initramfs для этого ядра. Выберите другое ядро в меню GRUB в разделе « Дополнительные параметры» для Ubuntu и запустите, sudo update-initramfs -u -k versionчтобы сгенерировать initrd для version(затем замените versionстроку версии ядра, например 4.15.0-36-generic) sudo update-grub.
Начните с livecd, откройте терминал
sudo fdisk -l
sudo mount /dev/sdax /mnt
sudo mount --bind /dev /mnt/dev
sudo mount --bind /dev/pts /mnt/dev/pts
sudo mount --bind /proc /mnt/proc
sudo mount --bind /sys /mnt/sys
sudo chroot /mnt и теперь вы можете сделать update-initramfsи обновить-grub без ошибок.
update-initramfs -u -k 2.6.38-8-generic (or your version)Если вы не знаете свою версию. Использование:
dpkg --list | grep linux-imageИ просто обновить Grub.
update-grub2Перезагрузите вашу систему.
В моей ситуации проблема была в том, что /bootемкость была 100%, поэтому последние 2 обновления ядра не были успешно завершены, поэтому при перезагрузке, когда GRUB2 выбрал последнее ядро, произошел сбой.
Я решил проблему путем загрузки самого старого установленного ядра и удаления некоторых неиспользуемых ядер с помощью aptitude. Используя aptitude , после того, как деинсталляция произошла, dpkg автоматически попытался настроить поврежденные пакеты, и на этот раз это удалось.
В случае, если это произошло после прерванного обновления ядра (например, сбой системы во время aptitude safe-upgrade),
- загрузиться с более старым ядром и
- бежать
dpkg --configure -a.
Это завершит обновление, включая настройку параметров загрузки, как объясняет psusi .
В загрузочных сообщениях ядра указано, какие диски вы можете использовать
Например, если в моем тесте Linux 4,17 виртуальной установки машины я заменяю правильно root=/dev/vdaс root=/dev/vdbпоследним сообщением является:
---[ end Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)-Тем не менее , несколькими строками выше показаны сообщения типа:
VFS: Cannot open root device "vdb" or unknown-block(0,0): error -6
Please append a correct "root=" boot option; here are the available partitions:
fe00 524288 vda driver: virtio_blkкоторый в основном говорит мне прямо, что vdbне был найден, но что есть, /dev/vdaкоторый может быть прочитан из-за virtio_blkдрайвера ( CONFIG_VIRTIO_BLK=y).
В дополнение к инструкциям Tomeu, перед chroot мне нужно было:
sudo mount —bind /dev /mnt/dev
Дополнительно после chroot:
cp -r /usr/lib/i386-linux-gnu/pango /usr/lib/
( Получил это отсюда. )
Я получил эту проблему из-за того, что мой / boot раздел был переполнен, поэтому мои обновления ядра не были выполнены. Мне удалось это исправить, загрузившись со старого ядра в меню GRUB.
Когда мне удалось загрузиться, я начал очищать старые ядра, но мне удалось получить некоторые проблемы с зависимостями, поэтому сначала мне пришлось удалить пакет linux-server
apt-get remove linux-server
apt-get update
apt-get -f install
apt-get upgradeПотом я перезагрузился и все работало нормально!
If you followed that tutorial exactly, then you’ve now overwritten the bootloader on /dev/sda with the new bootloader of your LFS installation.
The partitioning on /dev/sda should be fine: if you want to restore the Mint installation, you’ll just need to boot the system from some live-Linux ISO, mount the root and /boot filesystems from /dev/sda*, chroot to the Mint installation and run grub-install /dev/sda. Since the GRUB configuration files of the Mint installation are untouched, that should be enough to restore the Mint installation to full working order.
The new bootloader attempts to load the OS kernel from /dev/sdband is actually successful at that: the Kernel Panic message is coming from the kernel of the LFS installation, not the bootloader.
(The bootloader installation is described in Chapter 11 of the video tutorial at time 15:30 onwards.)
At Chapter 11 time 16:12 the tutorial talks about creating /boot/grub/grub.cfg, and there is a line:
linux /boot/vmlinuz-4.7.2-lfs-7.10 root=<something> roIn your case, the should be /dev/sdb. If you got this wrong, this could have caused the error. At Chapter 11 time 18:20 the tutorial discusses about how to fix that: when you see the GRUB boot menu, press e to edit the boot options at boot time. You’ll see the same line mentioned above and can make temporary changes to make your LFS installation boot.
Another possible error is not having the driver for your root filesystem compiled in to your LFS kernel: this would be specified in the kernel configuration phase in Chapter 11 time 14:32, but the tutorial pretty much glosses over it.
In other words, in the kernel configuration menus, in the File systems sub-menu, the line The Extended 4 (ext4) filesystem should be selected as Y (represented as an asterisk), not as M. If you missed this step, then having the root=/dev/sdb correct on the boot options line won’t help: in that case, your best option would be to recover the Mint installation, use it to reconfigure & recompile your LFS kernel, and then place the recompiled vmlinuz-4.7.2-lfs-7.10 file to the /boot directory on /dev/sdb, and finally reinstall the LFS’s GRUB.
Having said that, in my opinion the tutorial made a fundamental mistake of not partitioning /dev/sdb in the beginning. Instead they used the whole disk for a single filesystem (mkfs /dev/sdb = the «superfloppy» configuration). That makes it impossible to install GRUB2 on /dev/sdb: GRUB2 needs a few disk blocks after the MBR, which are normally unused on a partitioned disk, but would overwrite the beginning of the filesystem on a «superfloppy». As a result, they’re forced to install the bootloader on /dev/sda instead, breaking the Mint host installation in the process.
The minimal changes I would have done:
- make
/dev/sdba single big partition (/dev/sdb1) and create a filesystem on it - do everything else using
/dev/sdb1instead of/dev/sdbexcept thegrub-installcommand: that would begrub-install /dev/sdb. - in
/boot/grub/grub.cfgof the LFS, the GRUB root device should then be specified asset root=(hd0,1)and the Linux root filesystem boot option should beroot=/dev/sdb1. This is because of a quirk of BIOS: whichever disk you select to boot from at the BIOS level will normally be(hd0)for GRUB, even if it is/dev/sdbfor Linux.
With these changes, you would avoid breaking the bootloader of the Mint installation, and should be able to use VirtualBox’s boot menu to select which installation you boot from: either Mint or your LFS. It should also allow you to completely remove the /dev/sda from the configuration (making /dev/sdb the new /dev/sda) with just changes to /boot/grub/grub.conf of the LFS, to prove that the new LFS installation is completely capable of stand-alone operation.
Thank You very much for your response. I am providing some answers.
- One thing I recognise…that your root filesystem is nearly full… but depending on how write-intense your services are.
I don’t have any read/write intensive services. I use Deluge a little bit to share files. For the most part, however, I use it to store images I take with a DSLR camera.
I use Docker and I have installed programs like Adguard Home, Unbound, Diun and some programs that I test their use like Pi-Hole, Pyload, Wireguard, Ddns-updater, Traefik.
I occasionally use Kodi to watch live IPTV, some series or movie. I used to have it set up for Kodi to start automatically after starting DietPi, but due to over-consumption RAM usage, I now only run it when I need it. Most of the time, however, DietPi only runs as a terminal window and background services.
- A minor enhancement…switch to the modern entropy daemon:
apt install rng-tools5
I installed rng-tools5.
- Aria2 fails to start, as the log file is missing:
Because the local lighttpd web server was in conflict with Adguard Home (port 80), I changed the lighttpd web port to 8088 in the /etc/lighttpd/lighttpd.conf file. As a result, Aria2 most likely does not work. I have now removed Aria2. In the future, if I need it, I’ll look for a docker version.
- Unbound is failing as well. Can you check: journalctl -u unbound
Missing /etc/unbound/ folder. However, since I am currently using Unbound, which is installed in Docker, I removed it from the DietPi system but apparently there were some issues with the removal and it was not removal completely see log.
dietpi-software uninstall 182
Mode: Automated uninstall
[ INFO ] DietPi-Software | 182: Unbound is not currently installed
[ OK ] DietPi-Software | No changes applied for: UnboundI solved Unbound problem by installing Unbound, restarting DietPi and removing Ubound again.
- And the Argon fan service fails. Check via: journalctl -u argononed
argononed.service: Start request repeated too quickly.
argononed.service: Failed with result 'exit-code'.
Failed to start Argon One Fan and Button Service.I removed the Argon One fan service, reboot and install the OSMC version curl https://download.argon40.com/argonone-setup-osmc.sh | bash. Then reboot and install the regular version curl https://download.argon40.com/argon1.sh | bash. After another reboot, it runs perfectly.
- You have DietPi-RAMlog enable but rsyslog installed and running as well…
I have removed DietPi-RAMlog and I will temporarily use rsyslog. When there are no more problems in restarting DietPi, I will remove rsyslog as well.
- You may also remove the obsolete elevator entry from your cmdline.txt…
I removed elevator=deadline.
- And there is still an obsolete CloudPrint service file installed:
apt purge cloudprint-service cloudprint
Although Google has discontinued the Cloud print service, I only use the CUPS print service. If I removed cloudprint and cloudprint-service then I would also remove CUPS, right?
- Ah and the install state of the DHCP client (you don’t use it, I know) is not as it should be:
apt install isc-dhcp-client
I already have isc-dhcp-client on the latest version: isc-dhcp-client is already the newest version (4.4.1-2).
- But I couldn’t see an issue/error that would explain kernel panics at boot. How is the drive powered? Via dedicated PSU or via USB only?
HDD is powered directly from RaspberryPi (USB only) with Official Raspberry Pi 4 USB-C 15.3W power supply, 5.1V, 3.0A (KSA-15E-051300-HX, SC0213).
I don’t have USB power meter, but I measured on the power side with a WiFi plug-in with a power meter.
Raspberry Pi | Current | Power | Voltage
Off | 0 mA | 0 W | 255,3 V
On + SD | 31 mA | 3,4 W | 256,2 V
On + SD + HDD | 68 mA | 8,7 W | 256,6 V
Power 8,7 W is the maximum, usually is between 5 W and 6 W.
- Could you also run and paste the output of the following command:
vcgencmd get_throttled = throttled=0x0
- Also checking the above listed issues/steps might give a hint, when the issue and the boot problems had the same root cause.
So far there was no boot problems. I hope this will remain so in the future.
To begin, it will probably take at least 30 minutes resolve this issue…
This fix solved my problem with the “vfs unable to mount root fs” error, but of course your results may vary. As always, first backup your system or do an export of the vm so you have a copy of the system as it existed before you started screwing around with it 😉
After running apt-get update / apt-get upgrade and then a reboot, you may receive the following error: kernel panic not syncing vfs unable to mount root fs on unknown-block 0 0 on ubuntu 16.04.
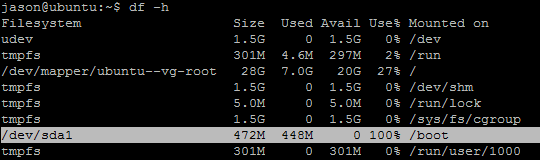
In many cases this will be due to the /boot drive becoming 100% full because many updates have been made to the kernel. By default, ubuntu will retain the old kernels and add them to the list of available kernels you can boot into in the Grub2 boot loader menu. You can confirm that your drive is full by issueing the command:
df -h
The result will likely show the following:
In order to resolve this issue and boot successfully, while you’re looking at the error during boot, (you should already be at the console), and restart the vm or computer into the Grub2 menu then choose “Advanced options for ubuntu” view where you can see a list of old kernels you can boot into. Some report you can do this booting with the Shift key held down, or in the event it’s a virtual machine, you should be able to arrow-down in the Grub start screen and choose Advanced options for ubuntu on startup:
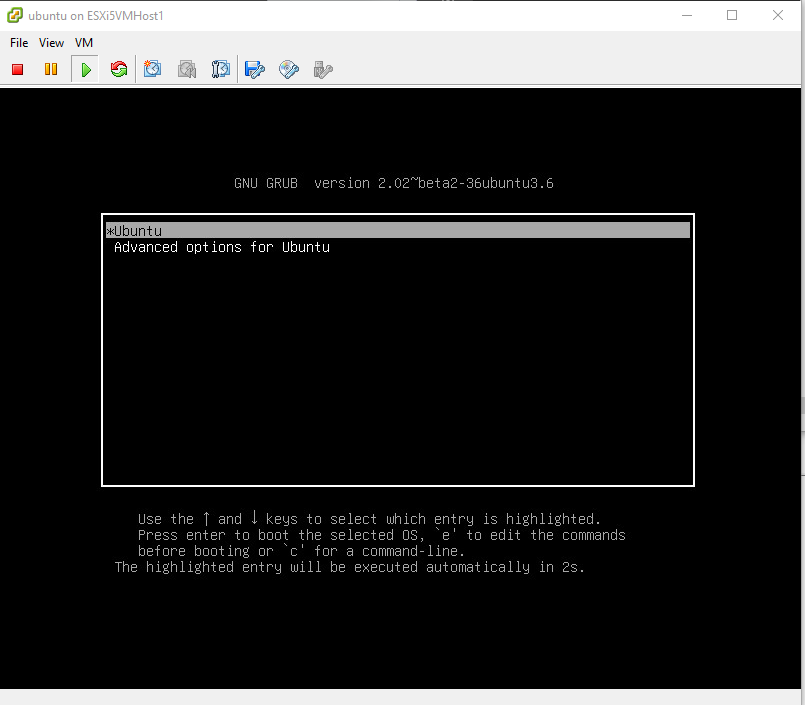
Grub2 boot menu.
Once you go into the advanced boot menu you will likely see several kernels listed. Choose the next-oldest kernel from the top/highest version of kernels. In my case I booted into the version labeled Ubuntu, with Linux 4.4.0-57-generic (my boot menu screenshot below is clean, but you’ll likely see several kernels listed).
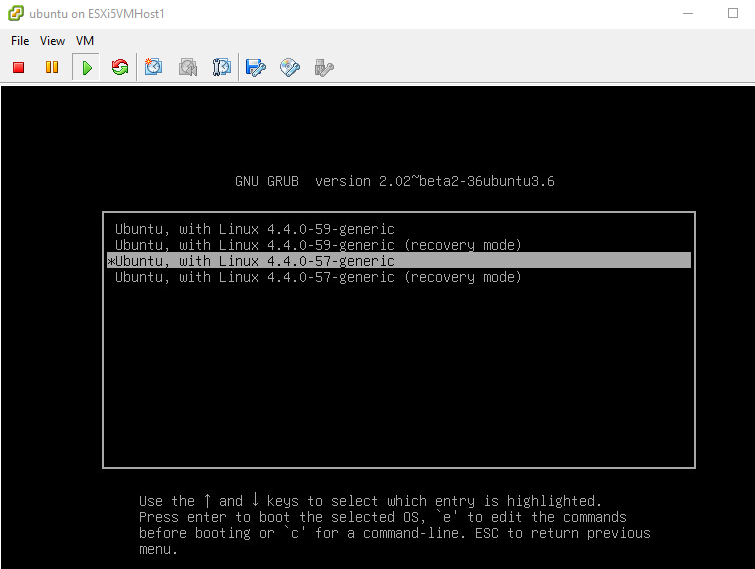
Cross your fingers and hope you get to your login prompt. From here I jumped on putty and connected from that client, as I prefer it over the console.
Next, login and follow the directions that I found here:
http://askubuntu.com/questions/2793/how-do-i-remove-old-kernel-versions-to-clean-up-the-boot-menu
To save you the search, here are the instructions I used to first list and then remove the old kernels:
Open terminal and check your current kernel:
uname -a
DO NOT REMOVE THIS KERNEL! Make a note of the version in notepad or something.
Next, type the command below to view/list all installed kernels on your system.
dpkg --list | grep linux-image
Find all the kernels that are lower than your current kernel version. When you know which kernel to remove, continue below to remove it. Run the commands below to remove the kernel you selected.
sudo apt-get purge linux-image-x.x.x.x-generic
Or:
sudo apt-get purge linux-image-extra-x.x.x-xx-generic
Finally, run the commands below to update grub2
sudo update-grub2
Reboot your system.
sudo reboot
As you can see from my terminal history, I had to remove a few:
589 uname -a 590 dpkg --list | grep linux-image 591 sudo apt-get purge linux-image-4.4.0-21-generic 592 sudo apt-get purge linux-image-4.4.0-22-generic 593 sudo apt-get purge linux-image-4.4.0-24-generic 594 df -h 595 sudo apt-get purge linux-image-4.4.0-24-generic 596 sudo apt-get purge linux-image-4.4.0-28-generic 597 sudo apt-get purge linux-image-4.4.0-31-generic 598 sudo apt-get purge linux-image-4.4.0-34-generic 599 sudo apt-get purge linux-image-4.4.0-36-generic 600 sudo apt-get purge linux-image-4.4.0-38-generic 601 df -h 602 sudo apt-get purge linux-image-4.4.0-42-generic 603 sudo apt-get purge linux-image-4.4.0-45-generic 604 sudo apt-get purge linux-image-4.4.0-47-generic 605 sudo apt-get purge linux-image-4.4.0-51-generic 606 sudo apt-get purge linux-image-4.4.0-53-generic 607 sudo update-grub2 608 dpkg --list | grep linux-image 609 df -h 610 sudo apt-get purge linux-image-extra-4.4.0-21-generic 611 sudo apt-get purge linux-image-extra-4.4.0-22-generic 612 sudo apt-get purge linux-image-extra-4.4.0-24-generic 613 sudo apt-get purge linux-image-extra-4.4.0-28-generic 614 sudo apt-get purge linux-image-extra-4.4.0-31-generic 615 sudo update-grub2 616 df -h 617 sudo reboot 618 dpkg --list | grep linux-image 619 uname -a 620 sudo reboot
After the reboot, you can see my /boot partition returned to a manageable size:
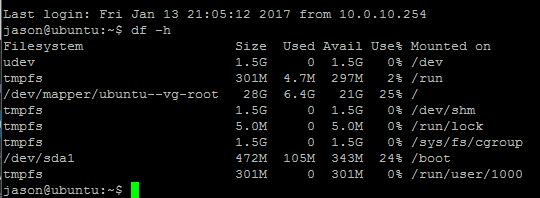
I hope this post helps someone save some time and help them fix their ubuntu boot problems. Please leave a comment if this helped resolve your issue or if there is a smarter/faster way to fix this problem.
Cleaning up Boot partition on Ubuntu 16
When on Rescue Mode, select the option clean followed by dpkg, grub and fsck.

This will make sure that the space on your boot partition is free, will repair any broken packages, check all file systems and that they are correct and update your grub bootloader.
After this, you are very likely to get a stable Ubuntu 16.04 back.
The command line way to clean up /boot partition
It can be that you open your computer, and it will boot normally, but Ubuntu will complain that the boot partition is almost full, in this case you can execute the auto-remove:

$ sudo apt-get autoremove --purge [sudo] password for ninja: Reading package lists... Done Building dependency tree Reading state information... Done The following packages will be REMOVED: linux-headers-4.4.0-79 linux-headers-4.4.0-79-generic linux-headers-4.4.0-81 linux-headers-4.4.0-81-generic linux-headers-4.8.0-49 linux-headers-4.8.0-49-generic linux-headers-4.8.0-51 linux-headers-4.8.0-51-generic linux-headers-4.8.0-52 linux-headers-4.8.0-52-generic linux-headers-4.8.0-54 linux-headers-4.8.0-54-generic linux-image-4.4.0-79-generic linux-image-4.4.0-81-generic linux-image-4.8.0-49-generic linux-image-4.8.0-51-generic linux-image-4.8.0-52-generic linux-image-4.8.0-54-generic linux-image-extra-4.4.0-79-generic linux-image-extra-4.4.0-81-generic linux-image-extra-4.8.0-49-generic linux-image-extra-4.8.0-51-generic linux-image-extra-4.8.0-52-generic linux-image-extra-4.8.0-54-generic 0 upgraded, 0 newly installed, 24 to remove and 93 not upgraded. 9 not fully installed or removed. After this operation, 1854 MB disk space will be freed. Do you want to continue? [Y/n] y (Reading database ... 497711 files and directories currently installed.) Removing linux-headers-4.4.0-79-generic (4.4.0-79.100) ... Removing linux-headers-4.4.0-79 (4.4.0-79.100) ... Removing linux-headers-4.4.0-81-generic (4.4.0-81.104) ... Removing linux-headers-4.4.0-81 (4.4.0-81.104) ... Removing linux-headers-4.8.0-49-generic (4.8.0-49.52~16.04.1) ... Removing linux-headers-4.8.0-49 (4.8.0-49.52~16.04.1) ... Removing linux-headers-4.8.0-51-generic (4.8.0-51.54~16.04.1) ... Removing linux-headers-4.8.0-51 (4.8.0-51.54~16.04.1) ... Removing linux-headers-4.8.0-52-generic (4.8.0-52.55~16.04.1) ... Removing linux-headers-4.8.0-52 (4.8.0-52.55~16.04.1) ... Removing linux-headers-4.8.0-54-generic (4.8.0-54.57~16.04.1) ... Removing linux-headers-4.8.0-54 (4.8.0-54.57~16.04.1) ... Removing linux-image-extra-4.4.0-79-generic (4.4.0-79.100) ... (...) Warning: Setting GRUB_TIMEOUT to a non-zero value when GRUB_HIDDEN_TIMEOUT is set is no longer supported. Found linux image: /boot/vmlinuz-4.8.0-58-generic Found initrd image: /boot/initrd.img-4.8.0-58-generic Found linux image: /boot/vmlinuz-4.8.0-56-generic Found initrd image: /boot/initrd.img-4.8.0-56-generic Found linux image: /boot/vmlinuz-4.4.0-83-generic Found initrd image: /boot/initrd.img-4.4.0-83-generic Found memtest86+ image: /memtest86+.elf Found memtest86+ image: /memtest86+.bin done Setting up linux-image-generic-hwe-16.04 (4.8.0.58.29) ... Setting up linux-generic-hwe-16.04 (4.8.0.58.29) ... Setting up linux-image-extra-virtual (4.4.0.83.89) ... ninja@ninja:~$ sudo apt-get autoremove --purge Reading package lists... Done Building dependency tree Reading state information... Done 0 upgraded, 0 newly installed, 0 to remove and 93 not upgraded.
Then finally you can update GRUB kernel list:
$ sudo update-grub Generating grub configuration file ... Warning: Setting GRUB_TIMEOUT to a non-zero value when GRUB_HIDDEN_TIMEOUT is set is no longer supported. Found linux image: /boot/vmlinuz-4.8.0-58-generic Found initrd image: /boot/initrd.img-4.8.0-58-generic Found linux image: /boot/vmlinuz-4.8.0-56-generic Found initrd image: /boot/initrd.img-4.8.0-56-generic Found linux image: /boot/vmlinuz-4.4.0-83-generic Found initrd image: /boot/initrd.img-4.4.0-83-generic Found memtest86+ image: /memtest86+.elf Found memtest86+ image: /memtest86+.bin done
Check the partition sizes with lsblk
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop1 7:1 0 88,1M 1 loop /snap/conjure-up/518 loop4 7:4 0 79,5M 1 loop /snap/core/2312 loop2 7:2 0 88,1M 1 loop /snap/conjure-up/527 loop0 7:0 0 79,5M 0 loop /snap/core/1689 nvme0n1 259:0 0 477G 0 disk ├─nvme0n1p5 259:3 0 476,5G 0 part │ └─nvme0n1p5_crypt 253:0 0 476,5G 0 crypt │ ├─ubuntu--vg-root 253:1 0 460,9G 0 lvm / │ └─ubuntu--vg-swap_1 253:2 0 15,6G 0 lvm │ └─cryptswap1 253:3 0 15,6G 0 crypt [SWAP] ├─nvme0n1p1 259:1 0 487M 0 part /boot └─nvme0n1p2 259:2 0 1K 0 part loop5 7:5 0 78,4M 0 loop /snap/core/1577 loop3 7:3 0 88,2M 1 loop /snap/conjure-up/510
Or you can also:
Compiling
make defconfig
CONFIG_EXT4_FS=y
CONFIG_IA32_EMULATION=y
CONFIG_VIRTIO_PCI=y (Virtualization -> PCI driver for virtio devices)
CONFIG_VIRTIO_BALLOON=y (Virtualization -> Virtio balloon driver)
CONFIG_VIRTIO_BLK=y (Device Drivers -> Block -> Virtio block driver)
CONFIG_VIRTIO_NET=y (Device Drivers -> Network device support -> Virtio network driver)
CONFIG_VIRTIO=y (automatically selected)
CONFIG_VIRTIO_RING=y (automatically selected)—> see http://www.linux-kvm.org/page/Virtio
What Causes This?
That is the million dollar question. After inspecting my GCE VM, I found out there were 14 different kernels installed taking up several hundred MB’s of space. Most of the kernels didn’t have a corresponding initrd.img file, and were therefore not bootable (including 3.19.0-39-generic).
I certainly never went around trying to install random kernels, and once removed, they no longer appear as available upgrades, so I’m not sure what happened. Seriously, what happened?
Edit: New response from Google Cloud Support.
I received another disconcerting response. This may explain the additional, errant kernels.
«On rare occasions, a VM needs to be migrated from one physical host to another. In such case, a kernel upgrade and security patches might be applied by Google.»
Even Better — How to recover your instance.
After several back-and-forth emails, I finally received a response from support that allowed me to resolve the issue. Be mindful, you will have to change things to match your unique VM.
Take a snapshot of the disk first in case we need to roll back any of the changes below.
Edit the properties of the broken instance to disable this option: «Delete boot disk when instance is deleted»
Delete the broken instance.
IMPORTANT: ensure not to select the option to delete the boot disk. Otherwise, the disk will get removed permanently!!
Start up a new temporary instance.
Attach the broken disk (this will appear as /dev/sdb1) to the temporary instance
In the temporary instance:
# Run fsck to fix any disk corruption issues
$ sudo fsck.ext4 -a /dev/sdb1
# Mount the disk from the broken vm
$ sudo mkdir /mnt/sdb
$ sudo mount /dev/sdb1 /mnt/sdb/ -t ext4
# Find out the UUID of the broken disk. In this case, the uuid of sdb1 is d9cae47b-328f-482a-a202-d0ba41926661
$ ls -alt /dev/disk/by-uuid/
lrwxrwxrwx. 1 root root 10 Jan 6 07:43 d9cae47b-328f-482a-a202-d0ba41926661 -> ../../sdb1
lrwxrwxrwx. 1 root root 10 Jan 6 05:39 a8cf6ab7-92fb-42c6-b95f-d437f94aaf98 -> ../../sda1
# Update the UUID in grub.cfg (if necessary)
$ sudo vim /mnt/sdb/boot/grub/grub.cfgNote: This ^^^ is where I deviated from the support instructions.
Instead of modifying all the boot entries to set root=UUID=[uuid character string], I looked for all the entries that set root=/dev/sda1 and deleted them. I also deleted every entry that didn’t set an initrd.img file. The top boot entry with correct parameters in my case ended up being 3.19.0-31-generic. But yours may be different.
# Flush all changes to disk
$ sudo sync
# Shut down the temporary instance
$ sudo shutdown -h nowFinally, detach the HDD from the temporary instance, and create a new instance based off of the fixed disk. It will hopefully boot.
Assuming it does boot, you have a lot of work to do. If you have half as many unused kernels as me, then you might want to purge the unused ones (especially since some are likely missing a corresponding initrd.img file).
I used the second answer (the terminal-based one) in this askubuntu question to purge the other kernels.
Note: Make sure you don’t purge the kernel you booted in with!
Kernel panic not syncing
И много еще чего написано. Жаль, скрин сразу не сделал. Делаю ресет системе и снова вижу эту же ошибку. Тут запустилось производство кирпичей. В голове сразу же побежали мысли, что там с бэкапами. Делаться то они делаются, я даже уведомления в почте каждый день смотрю, что все в порядке. Но когда я последний раз вручную разворачивал эти бэкапы? Очень давно.
Еще один рестарт и та же ошибка. Немного запаниковал, встал, прошелся по комнате, подумал, что делать. Оценил обстановку. Больше всего испугался, что накрывается жесткий диск сервера, где куча всяких виртуалок и сайтов. Бэкапы вроде все есть, но все это настраивать, разворачивать, где-то сервак искать и т.д. В общем, думаю, примерно масштаб бедствия вы представляете.
Пошел на гипервизор, там вроде все в порядке, ошибок никаких нет. На других виртуалках тоже. С дисками, по идее, все нормально. А что же тогда тут случилось? В голову приходит мысль загрузиться на старом ядре. Выбираю старое ядро, загружаюсь — все в порядке. ОТЛЕГЛО.
Сразу стало понятно, в чем проблема. На серваке не хватало памяти. Я запустил обновление, оно отработало с ошибкой. Скорее всего не собрался initramfs для нового ядра. Загрузка старого ядра, в данном случае и было решением ошибки:
Kernel panic not syncing: VFS: Unable to mount root fs
Добавил виртуальной машине памяти, обновил ее еще раз. Теперь все прошло нормально. Перезагружаться пока не пробовал, вечером сделаю. Думаю, все в порядке будет.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите подробнее программу по ссылке.
Synopsis
When booting a freshly configured kernel, the boot fails with the following message:
VFS: Cannot open root device "hda3" or unknown-block(2,0) Please append a correct "root=" boot option; here are the available partitions: ... Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(2,0)
The numbers in the unknown-block section can be different.
Analysis
The panic informs that the Linux kernel is unable to:
- Detect the controller for the hard disk (a likely candidate if the message says
unknown-block(0,0)); - Detect the partition because it does not have support for the partition type (less likely, but still possible);
- Mount the partition because it does not know how to access the file system (a likely candidate if the message gives a non-zero figure in the first number set, such as
unknown-block(2,0)); - Detect the partition because the wrong device was passed in the boot loader configuration.
Resolution
Boot with the old kernel (if available), or with a LiveCD, and open the kernel configuration:
- Ensure that the controller chipset has been configured in the Linux kernel (and in-kernel, not as a module);
- Ensure that the used file systems (such as ext2, ext3, ext4, ReiserFS, Btrfs, etc.) are configured in the Linux kernel (and built into the kernel, not as a module);
- When using
root=UUID=..., an initramfs must be built when configuring the bootloader, see «Configuring the linux kernel» of the installation handbook - If running Gentoo as a Qemu guest, ensure that the virtio block drivers and PCI driver for virtio devices are enabled in the kernel (that is,
CONFIG_VIRTIO_BLK=yandCONFIG_VIRTIO_PCI=yin the kernel configuration file).
Also verify that the boot loader configuration (/boot/grub/grub.conf for GRUB legacy and /boot/grub/grub.cfg for GRUB2) refers to the correct partition:
FILE /boot/grub/grub.confGRUB Legacy partition example
title Gentoo Linux root (hd0,0) kernel /kernel-3.0.4 root=/dev/sda3
When using an initramfs and upgrade to another kernel version, make sure the initramfs is recreated correctly in /boot for the new kernel version and that the boot loader configuration refers to the correct initramfs.
How to salvage your current situation?
I would first work on recovering the Mint bootloader on /dev/sda using a live-Linux ISO. Once that is fixed, I would boot to Mint, mount /dev/sdb and pack up everything on it into a tar.bz2 package:
mount /dev/sdb /mnt
cd /mnt
tar jcvf /somewhere/with/plenty/of/space/LFS-recovery.tar.bz2 *
cd /
umount /mntThen I would partition /dev/sdb, create an ext4 filesystem on /dev/sdb1, mount it and restore everything that was on /dev/sdb onto it:
fdisk /dev/sdb
<set up one partition to cover the whole disk>
mkfs -v -t ext4 /dev/sdb1
mount /dev/sdb1 /mnt
cd /mnt
tar xvf /somewhere/with/plenty/of/space/LFS-recovery.tar.bz2The next steps would be the necessary preparations and chrooting into the LFS environment, much like Chapter 6 2:40-4:05 of the tutorial but now the directories should already be there. Then the bootloader can be installed to /dev/sdb, as described earlier.
Выводы
Не понравилась статья и хочешь научить меня администрировать? Пожалуйста, я люблю учиться. Комментарии в твоем распоряжении. Расскажи, как сделать правильно!
- Очень внимательно относитесь к обновлениям. Не запускайте их в обычном терминале по ssh. Если оборвется связь и обновление ядра не выполнится полностью, можете получить такую же проблему, как я сегодня. Обновляйтесь в screen или tmux.
- Не торопитесь перезагружать сервер в случае проблем. Лучше сразу же сделать бэкап свежих данных, пока сервер еще живой. Так у вас как минимум, будут самые актуальные бэкапы, а не ночные. В принципе, я так всегда и делаю, но тут расслабился, так как сервер не сильно критичный и простой допускает.
- Перед перезагрузкой убедитесь, что у вас есть доступ к терминалу. Я всегда это делаю.
- И самый важный пункт — не занимайтесь обслуживанием сайтов, для которых недопустим простой. Нервы и спокойная жизнь дороже. Пусть это делает кто-то другой 🙂
Помогла статья? Подписывайся на telegram канал автора
Анонсы всех статей, плюс много другой полезной и интересной информации, которая не попадает на сайт.
")




")