
This error may occur due to different reasons in different scenarios. Some of them are:
Let’s see, how we fix this access denied error for our customers in detail.
Not able to login
Recently, one of our customers approached us saying that he is getting an error like the one shown below while he is trying to log in to MySQL.

Initially, we opened /etc/mysql/my. cnf
Here we skipped grant tables as there is no other way to log in.
By skipping the grant table option it allows anyone to log in from anywhere and can do anything on the database.
Note: skip-grant-tables is dangerous, so we will remove this at the end.
3 Then, we restarted the MySQL service using the command below:
service mysql restart
Now MySQL is configured to skip the grant-tables. So, we can log in now.
We logged into MySQL using:
mysql -u root
Then, we flushed the privileges using:

Then, we removed skip-grant-tables from /etc/mysql/my. cnf
Finally, we restarted the MySQL service and logged in to MySQL using the new password.
This fixes the error.
No global privilege
If there is no global privilege then this error can happen. In such cases, our Engineers add the privilege by:
Now, to further the discussion, you could be facing the issue due to multiple reasons, some of which include:
- Solution
- FAQs
- How to change the root password for MySQL?
- How to recover the root password for MySQL?
- 2) User does not exist
- 4) Password is wrong, or the user forgot his password
- 5) Special characters in the password being converted by Bash
- 6) SSL is required but the client is not using it
- 7) PAM backend not working
- Причина возникновения ошибки 1045
- Что делать?
- Phpmyadmin
- Другие решения
- #1 10. 2015 16
- #10 27. 2015 14
- #12 31. 2016 12
- #13 31. 2016 12
- #15 03. 2016 22
- Установка Elasticsearch
- Centos 7 / 8
- Ubuntu / Debian
- Настройка Elasticsearch
- Установка Kibana
- Ubuntu/Debian
- Настройка Kibana
- Установка и настройка Logstash
- Установка Filebeat для отправки логов в Logstash
- Установка и настройка Winlogbeat
- Проксирование подключений к Kibana через Nginx
- Автоматическая очистка индексов в elasticsearch
- Часто задаваемые вопросы по теме статьи (FAQ)
- Зачем нужен Zabbix proxy
- Установка Zabbix proxy
Solution
mysql> FLUSH PRIVILEGES;
The main solution to this is to connect MySQL as root by switching authentication from auth_socket to mysql_native_password in the terminal:
- Select Use Legacy Password Encryption from the two options available, the other one being Use Strong Password Encryption.
- Using the search tool, openMySQL.prefPane and select the configuration tab.
- Click ‘Select’ option of the ‘Configuration File’ and select/private/etc/my.cnf
With skipping the grant table, you can log in from anywhere and do almost anything on the database server.
/usr/local/mysql—macos-x86_64/bin/mysql -uroot -p
- Since you have already reset the password, it is time to remove ‘skip-grant-tablesetc/mysql/my.cnf
- Restart MySQL again and log in using the new password. The service will no longer show the error.
FAQs
Error logs are one of the most important logs in terms of IT operations because it helps in detecting and diagnosing functional problems that simply improves performance.
The MYSQL error log basically contains error messages, warnings and different notes which are created during the startup and shutdown phases.
A file or the console is a general location or, say, destination of error logs. When no location is specified, then in windows, the error logs are written to host_name. err ( host_name is the host system name) in the data directory, whereas in UNIX/Linux, the console is the default destination of errors.
How to change the root password for MySQL?
To change the root password in MySQL:
- ~/mysql-pwd
- Stop MYSQL withsudo systemctl stop mysqlcommand and then issue the command:sudo mysqld -init-file=~/mysql-pwd. As the command prompt returns, restart the MYSQL using thesudo systemctl start mysql
How to recover the root password for MySQL?
To recover the root password in MySQL:
- sudo service mysql stopcommand to stop the MYSQL server.
- mysql -u root
mysql> use mysql;
mysql> flush privileges;
Note: In the above commands, NEWPASSWORD is the new password to be used.
If not specifying the host to connect (with -h flag), MySQL client will try to connect to the localhost instance while you may be trying to connect to another host/port instance.
Fix: Double check if you are trying to connect to localhost, or be sure to specify host and port if it’s not localhost:
2) User does not exist
or for public IP:
4) Password is wrong, or the user forgot his password
Fix: Check and/or reset password:
5) Special characters in the password being converted by Bash
Fix: Prevent bash from interpreting special characters by wrapping password in single quotes:
6) SSL is required but the client is not using it
Fix: Adding –ssl-mode flag (–ssl flag is deprecated but can be used too)
7) PAM backend not working
To reset password:
Finally, if you are genuinely locked out and need to circumvent the authentication mechanisms in order to regain access to the database, here are a few simple steps to do so:
- Stop the instance
- Start the instance
- Start MySQL again
Причина возникновения ошибки 1045
Таким образом, причина возникновения MySQL error 1045 — неправильная комбинация трех параметров: имени пользователя, хоста и пароля.
В качестве имени хоста могут выступать ip адреса, доменные имена, ключевые слова (например, localhost для обозначения локальной машины) и групповые символы (например, % для обозначения любого компьютера кроме локального). Подробный синтаксис смотрите в документации
Примеры. 1) Если вы не указали в явном виде имя хоста
GRANT ALL ON publications. * TO ‘ODBC’ IDENTIFIED BY ‘newpass’;
2) Другой первопричиной ошибки mysql 1045 может быть неправильное использование кавычек.
Что делать?
Если изначально была ошибка:
Phpmyadmin
Устанавливаете новую версию MySQL, но в конце при завершении конфигурации выпадает ошибка:
Это происходит потому, что ранее у вас стоял MySQL, который вы удалили без сноса самих баз. Если вы не помните старый пароль и вам нужны эти данные, то выполните установку новой версии без смены пароля, а потом смените пароль вручную через режим —skip-grant-tables.
Статья написана по материалам форума SQLinfo, т. в ней описаны не все потенциально возможные случаи возникновения ошибки mysql №1045, а только те, что обсуждались на форуме. Если ваш случай не рассмотрен в статье, то задавайте вопрос на форуме SQLinfo
Вам ответят, а статья будет расширена.
Дата публикации: 25. 2013
Другие решения
Причина, по которой это происходит, заключается в том, что forge запускает команду post install в вашем проекте, и вы, вероятно, обращаетесь к базе данных у одного из ваших поставщиков услуг, так как for может быть переменной, которую вы хотите присоединить к вашим представлениям, попробуйте комментировать код в поставщик услуг, установите репозиторий, а затем снова вставьте код, он должен работать нормально
Проверьте файл env, убедитесь, что после = нет пробелов и что имена переменных совпадают с именами в конфигурации базы данных. У меня также были проблемы, когда мне нужно было обернуть пароли и другие значения, содержащие специальные символы в ». Наконец, помните, что дело имеет значение — я видел проблемы, когда все работало локально и не работало на сервере dev, потому что кто-то изменил регистр переменной. Мой Mac не заботился, но сервер Ubuntu сделал.
Try specify environment
php artisan migrate —env=local
Check MySQL UNIX Socket
5
убедитесь, что ваш. env файл выглядит примерно так:
try changing localhost into 127. 1 in. env DB_HOST or try add your mysql port
#1 10. 2015 16
Была та же проблема, помогла очистка внутреннего кэша laravel:
php artisan config:cache
S config/database. php мне менять не пришлось, достаточно было изменить. env
#10 27. 2015 14
env ибо его предназначение мне тоже не совсем понятно.
Файлик полезный например ты с другом делаеш проект на локальных машинах и пушите его в репозиторий на гит, у вас на локальных машинах свои настройки подключения к базе данных, этот файлик добовляется в гит игнор, в итоге ты не перетираеш настройки подключения к базе друга когда пушиш в гит, а он твои. Ну а когда проект на боевом сервер запускаеш этот файлик вообще можно удалить и настройки подключения прописать уже в config.
#12 31. 2016 12
Спасибо. Не знал, все не мог понять зачем он нужен и почему коннекты прописывать в двух местах приходилось. А кроме удаление. env файла где-то можно прописать что использовать из config/database. php например? Или работает по принципу файл есть — env, файла нет — из конфига?
Изменено won (31. 2016 12:11:13)
#13 31. 2016 12
В одном месте на выбор — конфиг-файл или файл окружения (. env).
Если говорить строго, то данные ВСЕГДА берутся из конфиг-файла, но вот сам конфиг по умолчанию часть значений берет из хелпера env() — а это переменные окружения из файла. env.
Laravel при использовании внутреннего механизма конфигурации всегда идёт только в config/какой-то-файл. php, а уже там может быть как явное задание значения:
Так и косвенное, к примеру через хелпер env():
Более того, вторым параметром хелпер-функции env() можно отдать значение по умолчанию — функция вернет его, если в окружении (. env) не было ключа
#15 03. 2016 22
Для установки одиночного инстанса с полным набором компонентов ELK необходимы следующие системные ресурсы.
Системные требования для ELK Stack
минимальныерекомендуемые
CPU24+
Memory6 Gb8+ Gb
Disk10 Gb10+ Gb
Некоторое время назад для тестовой установки ELK Stack достаточно было 4 Gb оперативной памяти. На текущий момент с версией 7. 15 у меня не получилось запустить одновременно Elasticsearch, Logstash и Kibana на одной виртуальной машине с четырьмя гигабайтами памяти. После того, как увеличил до 6, весь стек запустился. Но для комфортной работы с ним нужно иметь не менее 8 Gb и 4 CPU. Если меньше, то виртуальная машина начинает тормозить, очень долго перезапускаются службы. Работать некомфортно.
В системных требованиях для ELK я указал диск в 10 Gb. Этого действительно хватит для запуска стека и тестирования его работы на небольшом объеме данных. В дальнейшем, понятное дело, необходимо ориентироваться на реальный объем данных, которые будут храниться в системе.
Установка Elasticsearch
Устанавливаем ядро системы по сбору логов — Elasticsearch. Его установка очень проста за счет готовых пакетов под все популярные платформы.
Centos 7 / 8
Копируем публичный ключ репозитория:
Подключаем репозиторий Elasticsearch:
# mcedit /etc/yum. repos. d/elasticsearch. repo
Приступаем к установке еластика:
# yum install —enablerepo=elasticsearch elasticsearch
В в завершении установки добавим elasticsearch в автозагрузку и запустим его с дефолтными настройками:
# systemctl daemon-reload
# systemctl enable elasticsearch. service
# systemctl start elasticsearch. service
Проверяем, запустилась ли служба:
# systemctl status elasticsearch. service
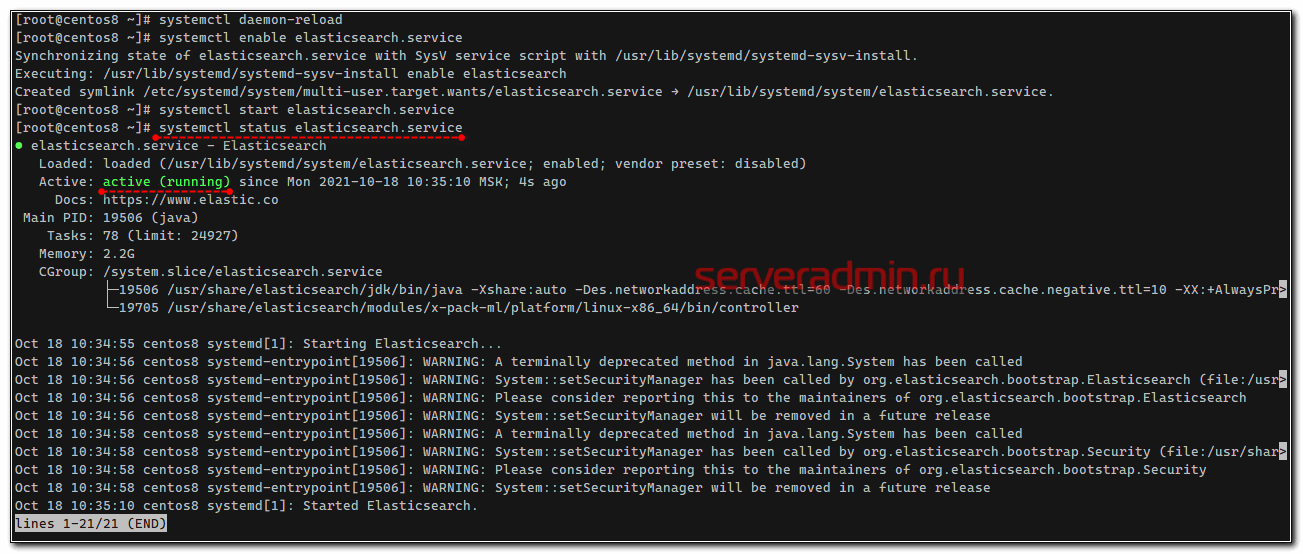
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос о его статусе.
Все в порядке, сервис реально запущен и отвечает на запросы.
Ubuntu / Debian
Копируем себе публичный ключ репозитория:
Добавляем репозиторий Elasticsearch в систему:
Если вы выполняете установку с российских ip адресов, то доступ к репозиториям elastic будет заблокирован. Используйте зеркало Yandex.
Устанавливаем Elasticsearch на Debian или Ubuntu:
# apt update && apt install elasticsearch
После установки добавляем elasticsearch в автозагрузку и запускаем.
# systemctl daemon-reload
# systemctl enable elasticsearch. service
# systemctl start elasticsearch. service
Проверяем, запустился ли он:
Если все в порядке, то переходим к настройке Elasticsearch.
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch. yml. На начальном этапе нас будут интересовать следующие параметры:
path. data: /var/lib/elasticsearch # директория для хранения данных
network. host: 127. 1 # слушаем только локальный интерфейс
По умолчанию Elasticsearch слушает localhost. Нам это и нужно, так как данные в него будет передавать logstash, который будет установлен локально. Обращаю отдельное внимание на параметр для директории с данными. Чаще всего они будут занимать значительное место, иначе зачем нам Elasticsearch 🙂 Подумайте заранее, где вы будете хранить логи. Все остальные настройки я оставляю дефолтными. После изменения настроек, надо перезапустить службу:
# systemctl restart elasticsearch. service
Смотрим, что получилось:
Elasticsearch повис на локальном интерфейсе. Причем я вижу, что он слушает ipv6, а про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Переходим к установке Kibana. Если вы хотите, чтобы elasticsearch слушал все сетевые интерфейсы, настройте параметр:
Только не спешите сразу же запускать службу. Если запустите, получите ошибку:
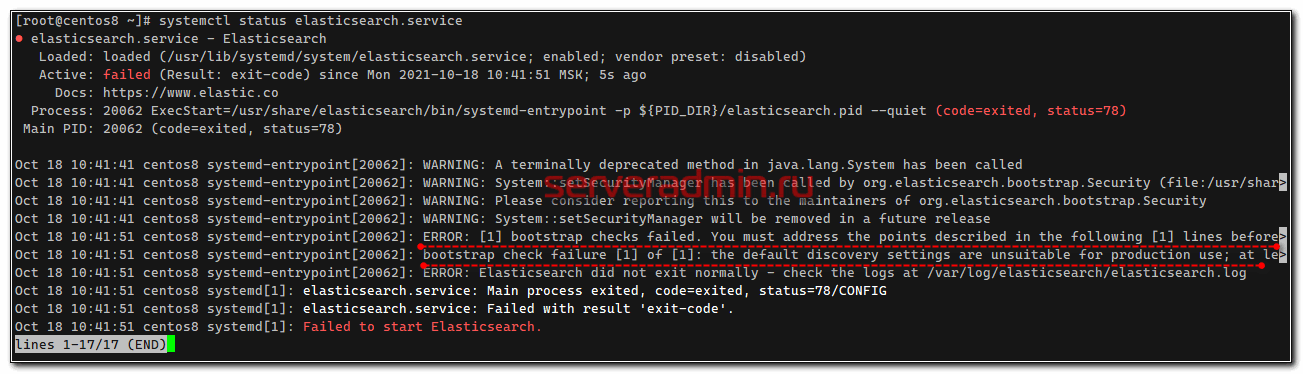
Чтобы ее избежать, дополнительно надо добавить еще один параметр:
Этим мы указываем, что хосты кластера следует искать только локально.
Установка Kibana
Дальше устанавливаем web панель Kibana для визуализации данных, полученных из Elasticsearch. Тут тоже ничего сложного, репозиторий и готовые пакеты есть под все популярные платформы. Репозитории и публичный ключ для установки Kibana будут такими же, как в установке Elasticsearch. Но я еще раз все повторю для тех, кто будет устанавливать только Kibana, без всего остального. Это продукт законченный и используется не только в связке с Elasticsearch.
Импортируем ключ репозитория:
Добавляем конфиг репозитория:
# mcedit /etc/yum. repos. d/kibana. repo
Запускаем установку Kibana:
# yum install kibana

Добавляем Кибана в автозагрузку и запускаем:
# systemctl daemon-reload
# systemctl enable kibana. service
# systemctl start kibana. service
Проверяем состояние запущенного сервиса:
# systemctl status kibana. service
По умолчанию, Kibana слушает порт 5601. Только не спешите его проверять после запуска. Кибана стартует долго. Подождите примерно минуту и проверяйте.
Ubuntu/Debian
Установка Kibana на Debian или Ubuntu такая же, как и на центос — подключаем репозиторий и ставим из deb пакета. Добавляем публичный ключ:
Добавляем рпозиторий Kibana:
# apt update && apt install kibana
Настройка Kibana
Файл с настройками Кибана располагается по пути — /etc/kibana/kibana. yml. На начальном этапе можно вообще ничего не трогать и оставить все как есть. По умолчанию Kibana слушает только localhost и не позволяет подключаться удаленно. Это нормальная ситуация, если у вас будет на этом же сервере установлен nginx в качестве reverse proxy, который будет принимать подключения и проксировать их в Кибана. Так и нужно делать в production, когда системой будут пользоваться разные люди из разных мест. С помощью nginx можно будет разграничивать доступ, использовать сертификат, настраивать нормальное доменное имя и т. Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server. host, указав ip адрес сервера, например вот так:
Если хотите, чтобы она слушала все интерфейсы, укажите в качестве адреса 0. После этого Kibana надо перезапустить:
# systemctl restart kibana. service

Можно продолжать настройку и тестирование, а когда все будет закончено, запустить nginx и настроить проксирование. Я настройку nginx оставлю на самый конец. В процессе настройки буду подключаться напрямую к Kibana. При первом запуске Kibana предлагает настроить источники для сбора логов. Это можно сделать, нажав на Add your data. К сбору данных мы перейдем чуть позже, так что можете просто изучить интерфейс и возможности этой веб панели
Периодически вы можете видеть в веб интерфейсе предупреждение:
server. publicBaseUrl is missing and should be configured when running in a production environment. Some features may not behave correctly.
Чтобы его не было, просто добавьте в конфиг Kibana параметр:
Или доменное имя, если используете его.
Установка и настройка Logstash
Logstash устанавливается так же просто, как Elasticsearch и Kibana, из того же репозитория. Не буду еще раз показывать, как его добавить. Просто установим его и добавим в автозагрузку. Установка Logstash в Centos:
# yum install logstash
Установка Logstash в Debian/Ubuntu:
# apt install logstash
Добавляем logstash в автозагрузку:
# systemctl enable logstash. service
Запускать пока не будем, надо его сначала настроить. Основной конфиг logstash лежит по адресу /etc/logstash/logstash. yml. Я его не трогаю, а все настройки буду по смыслу разделять по разным конфигурационным файлам в директории /etc/logstash/conf. Создаем первый конфиг input. conf, который будет описывать прием информации с beats агентов.
Тут все просто. Указываю, что принимаем информацию на 5044 порт. Этого достаточно. Если вы хотите использовать ssl сертификаты для передачи логов по защищенным соединениям, здесь добавляются параметры ssl. Я буду собирать данные из закрытого периметра локальной сети, у меня нет необходимости использовать ssl. Теперь укажем, куда будем передавать данные. Тут тоже все относительно просто. Рисуем конфиг output. conf, который описывает передачу данных в Elasticsearch.
Что мы настроили? Передавать все данные в elasticsearch под указанным индексом с маской в виде даты. Разбивка индексов по дням и по типам данных удобна с точки зрения управления данными. Потом легко будет выполнять очистку данных по этим индексам. Я закомментировал последнюю строку. Она отвечает за логирование. Если ее включить, то все поступающие данные logstash будет отправлять дополнительно в системный лог. В centos это /var/log/messages. Используйте только во время отладки, иначе лог быстро разрастется дублями поступающих данных. Остается последний конфиг с описанием обработки данных. Тут начинается небольшая уличная магия, в которой я разбирался некоторое время. Расскажу ниже. Рисуем конфиг filter. conf.
Первое, что делает этот фильтр, парсит логи nginx с помощью grok, если указан соответствующий тип логов, и выделяет из лога ключевые данные, которые записывает в определенные поля, чтобы потом с ними было удобно работать. С обработкой логов у новичков возникает недопонимание. В документации к filebeat хорошо описаны модули, идущие в комплекте, которые все это и так уже умеют делать из коробки, нужно только подключить соответствующий модуль.
Модули filebeat работают только в том случае, если вы отправляете данные напрямую в Elasticsearch. На него вы тоже ставите соответствующий плагин и получаете отформатированные данные с помощью elastic ingest. Но у нас работает промежуточное звено Logstash, который принимает данные. С ним плагины filebeat не работают, поэтому приходится отдельно в logstash парсить данные. Это не очень сложно, но тем не менее. Как я понимаю, это плата за удобства, которые дает logstash. Если у вас много разрозненных данных, то отправлять их напрямую в Elasticsearch не так удобно, как с использованием предобработки в Logstash.
Для фильтра grok, который использует Logstash, есть удобный дебаггер, где можно посмотреть, как будут парситься ваши данные. Покажу на примере одной строки из конфига nginx. Например, возьмем такую строку из лога:
И посмотрим, как ее распарсит правило grok, которое я использовал в конфиге выше.
Собственно, результат вы можете сами увидеть в дебаггере. Фильтр распарсит лог и на выходе сформирует json, где каждому значению будет присвоено свое поле, по которому потом удобно будет в Kibana строить отчеты и делать выборки. Только не забывайте про формат логов. Приведенное мной правило соответствует дефолтному формату main логов в nginx. Если вы каким-то образом модифицировали формат логов, внесите изменения в grok фильтр. Надеюсь понятно объяснил работу этого фильтра. Вы можете таким образом парсить любые логи и передавать их в еластикс. Потом на основе этих данных строить отчеты, графики, дашборды.
Дальше используется модуль date для того, чтобы выделять дату из поступающих логов и использовать ее в качестве даты документа в elasticsearch. Делается это для того, чтобы не возникало путаницы, если будут задержки с доставкой логов. В системе сообщения будут с одной датой, а внутри лога будет другая дата. Неудобно разбирать инциденты.
Закончили настройку logstash. Запускаем его:
# systemctl start logstash. service
Можете проверить на всякий случай лог /var/log/logstash/logstash-plain. log, чтобы убедиться в том, что все в порядке. Признаком того, что скачанная geoip база успешно добавлена будет вот эта строчка в логе:
Теперь настроим агенты для отправки данных.
Установка Filebeat для отправки логов в Logstash
В Debian/Ubuntu ставим так:
# yum install filebeat
# apt install filebeat
После установки рисуем примерно такой конфиг /etc/filebeat/filebeat. yml для отправки логов в logstash.
Некоторые пояснения к конфигу, так как он не совсем дефолтный и минималистичный. Я его немного модифицировал для удобства. Во-первых, я разделил логи access и error с помощью отдельного поля type, куда записываю соответствующий тип лога: nginx_access или nginx_error. В зависимости от типа меняются правила обработки в logstash. Плюс, я включил мониторинг и для этого указал адрес elastichsearch, куда filebeat передает данные мониторинга напрямую. Показываю это для вас просто с целью продемонстрировать возможность. У меня везде отдельно работает мониторинг на zabbix, так что большого смысла в отдельном мониторинге нет. Но вы посмотрите на него, возможно вам он пригодится. Чтобы мониторинг работал, его надо активировать в соответствующем разделе в Management — Stack Monitoring.

И не забудьте запустить elasticsearch на внешнем интерфейсе. В первоначальной настройке я указал слушать только локальный интерфейс. Запускаем filebeat и добавляем в автозагрузку.
# systemctl start filebeat
# systemctl enable filebeat
Проверяйте логи filebeat в дефолтном системном логе. По умолчанию, он все пишет туда. Лог весьма информативен. Если все в порядке, увидите список всех логов в директории /var/log/nginx, которые нашел filebeat и начал готовить к отправке. Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет индекса, нас перенаправит в раздел Managemet, где мы сможем его добавить.


Новый индекс добавлен. Теперь при переходе в раздел Discover, он будет открываться по умолчанию со всеми данными, которые в него поступают.

Получение логов с веб сервера nginx на linux настроили. Подобным образом настраивается сбор и анализ любых логов. Можно либо самим писать фильтры для парсинга с помощью grok, либо брать готовые. Вот несколько моих примеров по этой теме:
- Мониторинг производительности бэкенда с помощью ELK Stack
- Сбор и анализ логов samba в ELK Stack
- Дашборд для логов nginx
Теперь сделаем то же самое для журналов windows.
Установка и настройка Winlogbeat
Для настройки централизованного сервера сбора логов с Windows серверов, установим сборщика системных логов winlogbeat. Для этого скачаем его и установим в качестве службы. Идем на страницу загрузок и скачиваем msi версию под вашу архитектуру — 32 или 64 бита. Запускаем инсталлятор и в конце выбираем открытие директории по умолчанию.
Создаем и правим конфигурационный файл winlogbeat. yml. Я его привел к такому виду:
Думаю, по тексту понятен смысл. Я разделил по разным индексам логи nginx, системные логи виндовых серверов и добавил отдельный индекс unknown_messages, в который будет попадать все то, что не попало в предыдущие. Это просто задел на будущее, когда конфигурация будет более сложная, можно будет ловить сообщения, которые по какой-то причине не попали ни в одно из приведенных выше правил. Я не смог в одно правило поместить оба типа nginx_error и nginx_access, потому что не понял сходу, как это правильно записать, а по документации уже устал лазить, выискивать информацию. Так получился рабочий вариант. После этого перезапустил logstash и пошел на windows сервер, запустил службу Elastic Winlogbeat 7. Подождал немного, пока появятся новые логи на виндовом сервере, зашел в Kibana и добавил новые индексы. Напомню, что делается это в разделе Stack Management -> -> Index Patterns. Добавляем новый индекс по маске winsrv-*. Можно идти в раздел Discover и просматривать логи с Windows серверов.
У меня без проблем все заработало в том числе на серверах с русской версией Windows. Все логи, тексты в сообщениях на русском языке нормально обрабатываются и отображаются. Проблем не возникло нигде. На этом я закончил настройку ELK стека из Elasticsearch, Logstash, Kibana, Filebeat и Winlogbeat. Описал основной функционал по сбору логов. Дальше с ними уже можно работать по ситуации — строить графики, отчеты, собирать дашборды и т. В отдельном разделе ELK Stack у меня много примеров на этот счет.
Проксирование подключений к Kibana через Nginx
Я не буду подробно рассказывать о том, что такое проксирование в nginx. У меня есть отдельная статья на эту тему — настройка proxy_pass в nginx. Приведу просто пример конфига для передачи запросов с nginx в kibana. Я рекомендую использовать ssl сертификаты для доступа к Kibana. Даже если в этом нет объективной необходимости, надоедают уведомления браузеров о том, что у вас небезопасное подключение. Подробная инструкция по установке, настройке и использованию ssl в nginx так же есть у меня на сайте — настройка web сервера nginx. Все подробности настройки nginx смотрите там. Вот примерный конфиг nginx для проксирования запросов к Kibana с ограничением доступа по паролю:
Создаем файл для пользователей и паролей:
Если утилиты htpasswd нет в системе, то установите ее:
Автоматическая очистка индексов в elasticsearch
Некоторое время назад для автоматической очистки индексов в Elasticsearch необходимо было прибегать к помощи сторонних продуктов. Наиболее популярным был Curator. Сейчас в Kibana есть встроенный инструмент для очистки данных — Index Lifecycle Policies. Его не трудно настроить самостоятельно, хотя и не могу сказать, что там всё очевидно. Есть некоторые нюансы, так что я по шагам расскажу, как это сделать. Для примера возьму всё тот же индекс nginx-*, который использовал ранее в статье.
Настроим срок жизни индексов следующим образом:
- Первые 30 дней — Hot phase. В этом режиме индексы активны, в них пишутся новые данные.
- После 30-ти дней — Cold phase. В этой фазе в индексы невозможна запись новых данных. Запросы к этим данным имеют низкий приоритет.
- Все, что старше 90 дней удаляется.
Чтобы реализовать эту схему хранения данных, идем в раздел Stack Management -> Index Lifecycle Management и добавляем новую политику. Я её назвал Nginx_logs. Выставляем параметры фаз в соответствии с заданными требованиями.
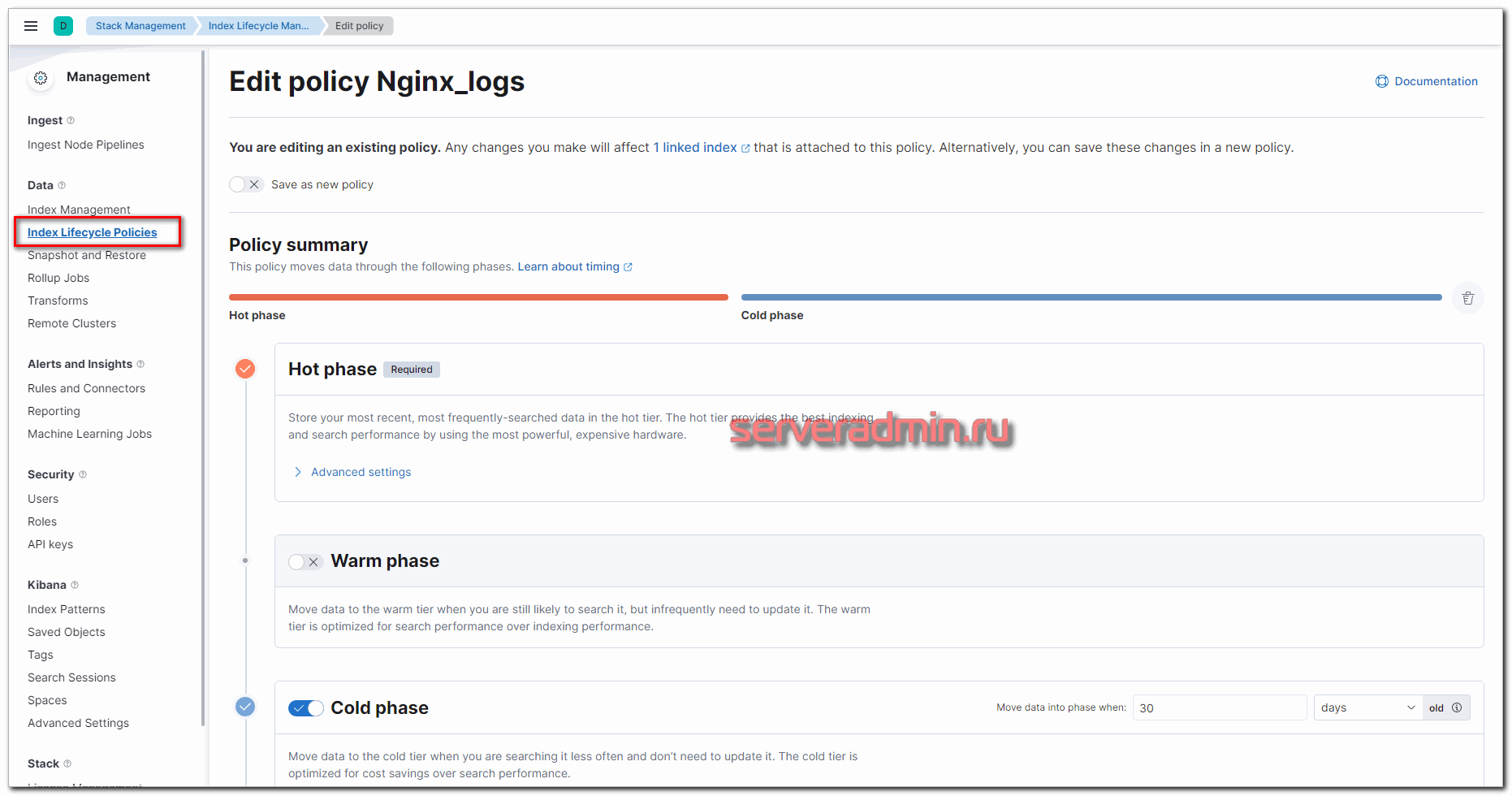
Не уместилось полное изображение настроек, но, думаю, вы там сами разберётесь, что выбрать. Ничего сложного тут нет. Далее нам нужно назначить новую политику хранения данных к индексам. Для этого переходим в Index Management -> Index Templates и добавляем новый индекс. В качестве шаблона укажите nginx-*, все остальные параметры можно оставить дефолтными.
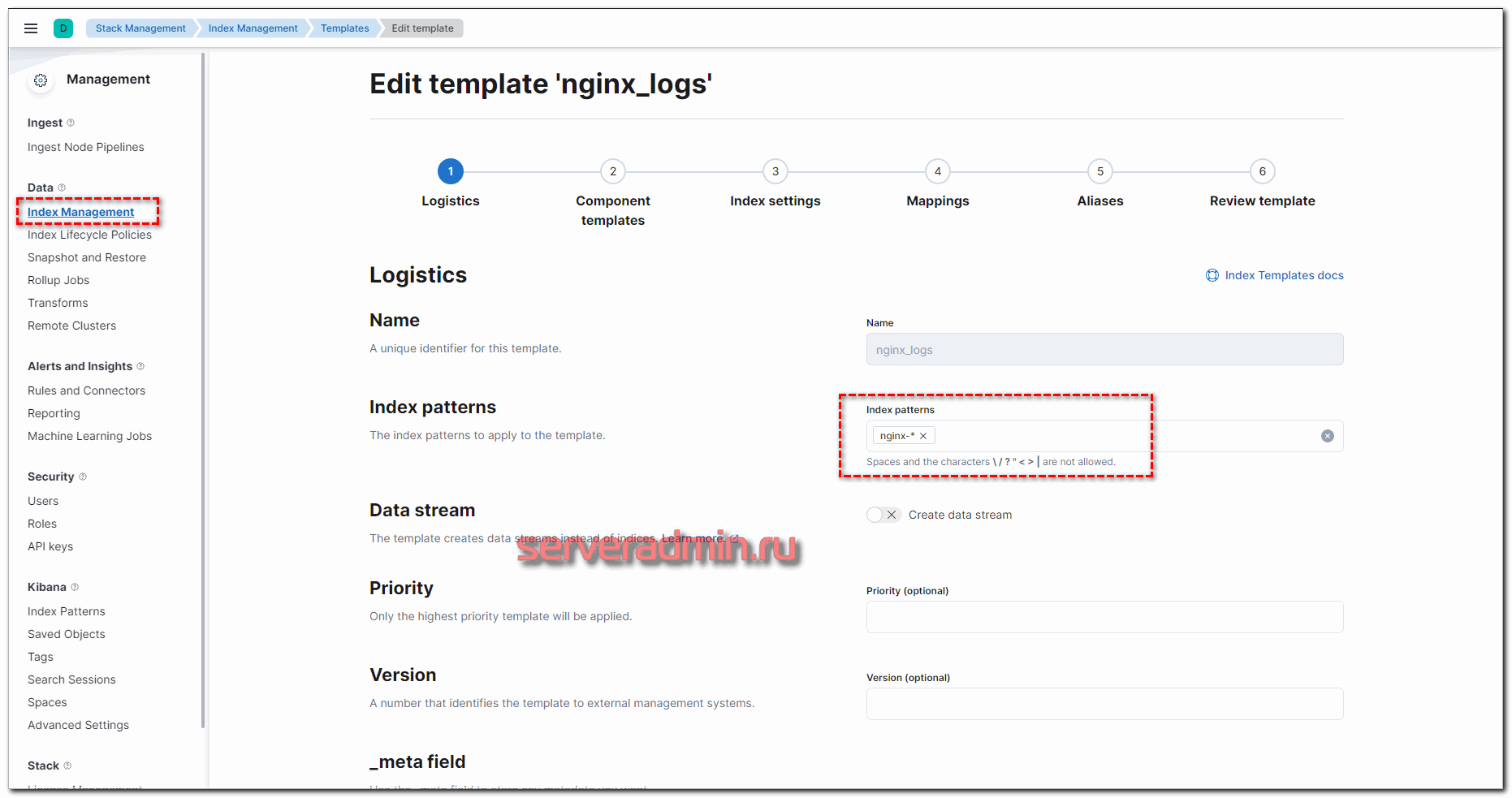
Теперь возвращаемся в Index Lifecycle Policies, напротив нашей политики нажимаем на + и выбираем только что созданный шаблон.
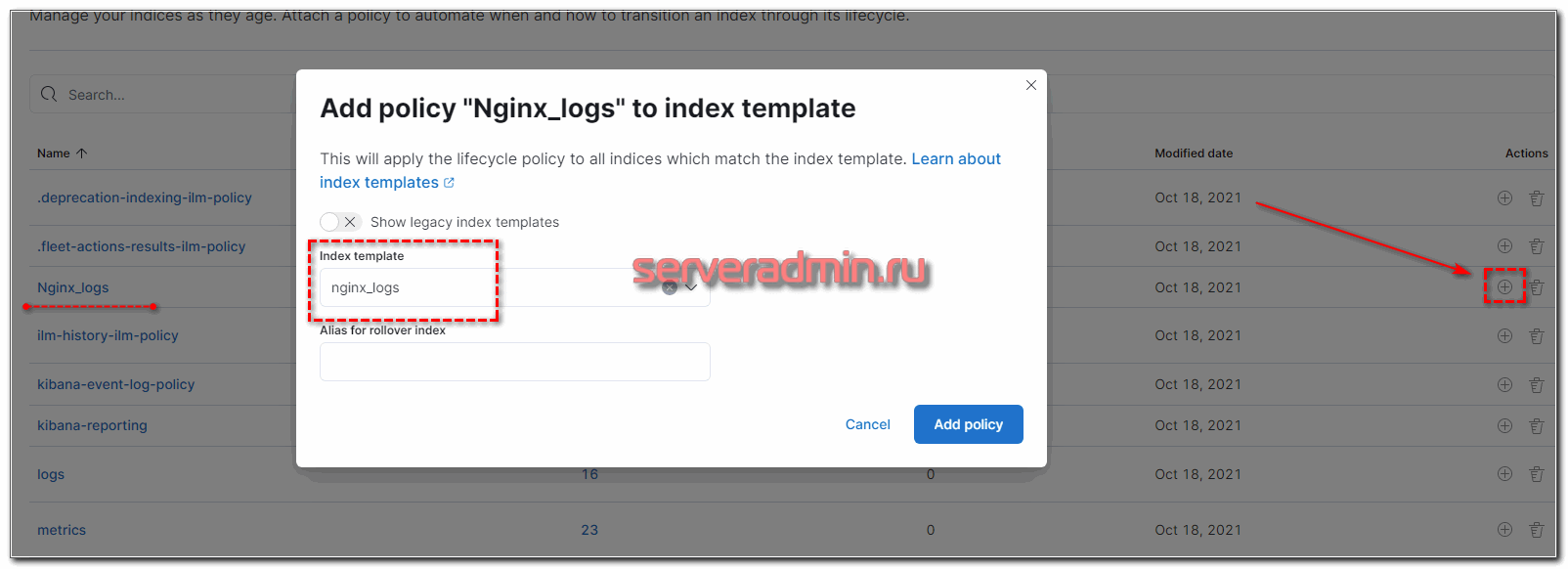
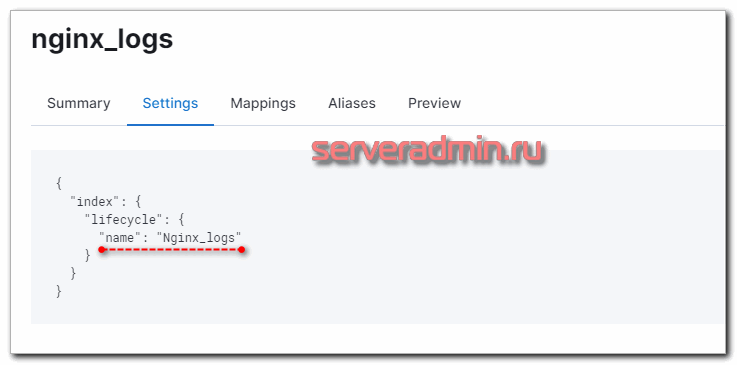
Проверяем свойства шаблона и убеждаемся в том, что Lifecycle Policies применилась.
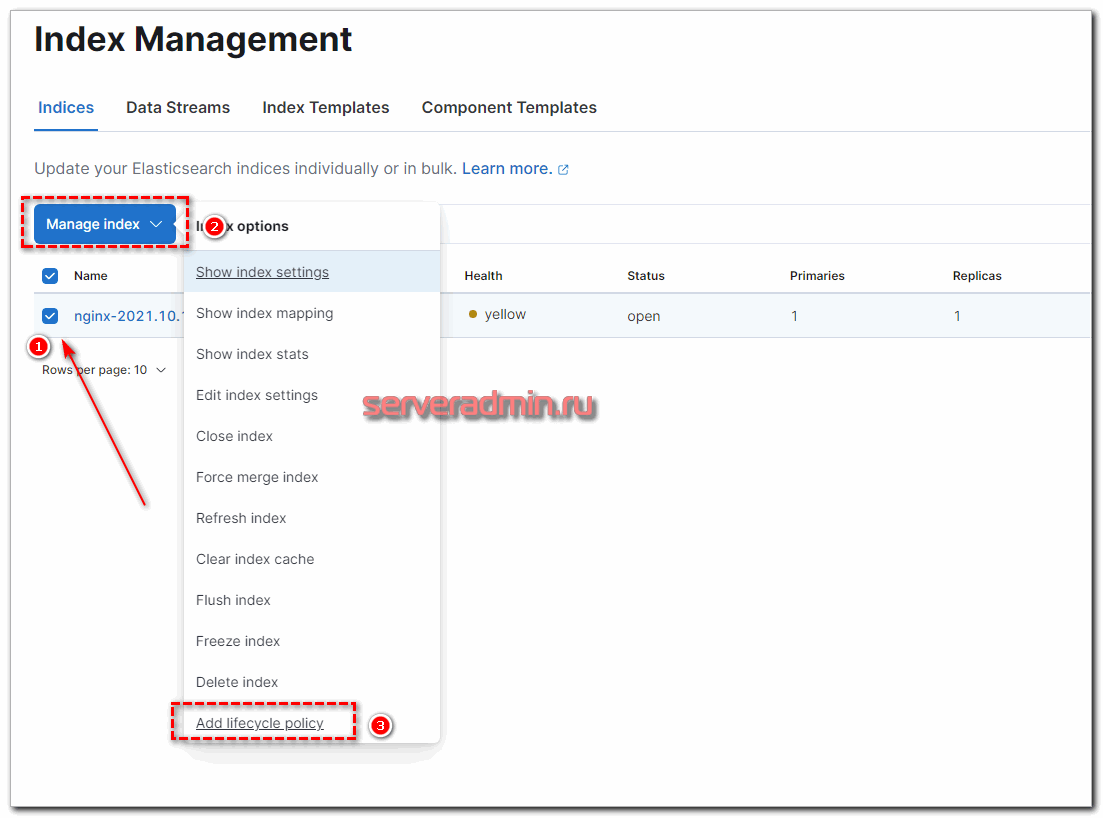
Теперь ко всем новым индексам, созданным по этому шаблону, будет применяться политика хранения данных. Для уже существующих это нужно проделать вручную. Достаточно выбрать нужный индекс и в выпадающем списке с опциями выбрать нужное действие.
Такими несложными действиями можно настроить автоматическую очистку индексов встроенными инструментами Elasticsearch и Kibana. В некоторых случаях быстрее и удобнее воспользоваться Curator, особенно если нужно быстро реализовать много разных схем. Единый конфиг куратора выглядит более наглядным, но это уже вкусовщина и от ситуации зависит.
Часто задаваемые вопросы по теме статьи (FAQ)
Можно ли вместо filebeat использовать другие программы для сбора логов?
Да, можно. Наиболее популярной заменой filebeat является Fluentd. Она более функциональна и производительна. В некоторых случаях может взять на себя часть функционала по начально обработке данных. В итоге, можно отказаться от logstash.
Можно ли в данной связке обойтись без logstash?
Да, если вы просто собираете логи, без предварительной обработки и изменения, можно отправлять данные напрямую в elasticsearch. На нем их так же можно обработать с помощью grok фильтра в elastic node. Вариант рабочий, но не такой функциональный, как logstash.
Есть ли в elasticsearch какой-то штатный механизм очистки старых данных?
Да, есть такой механизм — Index Lifecycle Policies, который требует отдельной настройки в Kibana. Также можно использовать сторонний софт. Пример такого софта — curator.
Как штатно настроить tls сертификат в Kibana?
Проще всего использовать для этого nginx в режиме proxy_pass. С его помощью можно без проблем подключить бесплатные сертификаты от Let’s Encrypt.
Какие минимальные системные требования для запуска ELK Stack?
Начать настройку можно с 2CPU и 6Gb RAM. Но для более ли менее комфортной работы желательно 8G RAM.
Зачем нужен Zabbix proxy
Расскажу своими словами что такое zabbix proxy и зачем он нужен. Допустим у вас есть распределенная сеть, где отдельные сегменты никак не связаны друг с другом. То есть условно, у вас 5 разных сетей с адресацией 192. 168. 0/24. Вам нужно настроить мониторинг узлов в этих сетях. Сети ничего не знаю друг о друге, у них нет прямого IP, только доступ в интернет.
В таком случае вы устанавливаете zabbix сервер на внешний ip адрес, в каждом сегменте сети настраиваете прокси, который будет собирать данные с узлов в этом сегменте и отправлять их на основной сервер мониторинга. Все управление при этом происходит на основном сервере, достаточно только один раз подключить прокси к основному серверу. Схематично подобная схема изображена в документации с официального сайта:
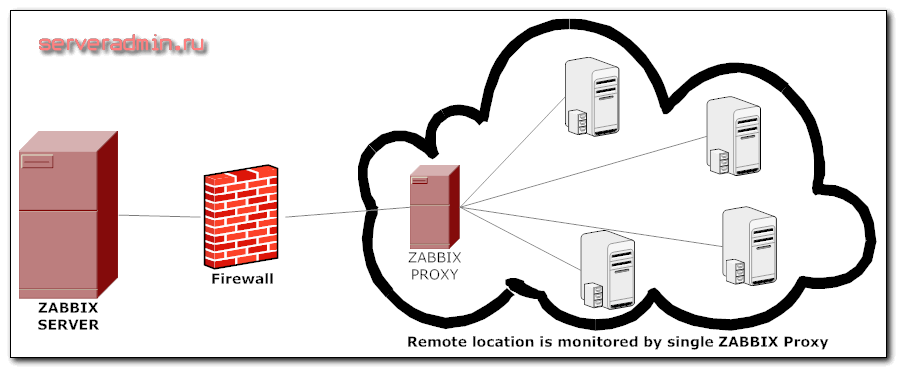
Если у вас полностью связаная сеть, в которой каждый узел имеет прямой доступ к серверу мониторинга, proxy сервера имеет смысл устанавливать и использовать для распределения нагрузки. 100 узлов, отправляющиие данные напрямую на сервер мониторинга, нагружают его сильнее, чем прокси, который собирает данные с этих 100 узлов и отправляяет их на основной сервер.
Вроде понятно и доступно объяснил. Приступим теперь к установке zabbix proxy. Устанавливать будем на сервер под управлением CentOS 7. Если у вас его еще нет, то читайте об установке centos 7 и его первоначальной настройке. Требования к железу зависят от нагрузки на прокси, но в общем случае они будут не высоки. Для мониторинга 20-30 узлов я использовал виртуальную машину с 512 мб оперативной памяти и 10 гб диском. Сама прокси почти ничего не хранит, отправялет данные на сервер.
В качестве основного сервера мониторинга у нас будет выступать Zabbix 3. Если вы его еще не настроили, то рекомендую мою подробную статью с видео по установке и настройке zabbix. Дальше я буду считать, что у вас уже настроен сервер мониторинга, к которму мы будем подключать proxy и добавлять новые узлы из подключенного сегмента сети.
Установка Zabbix proxy
Перед установкой добавлю еще пару слов о работе proxy. Прокси серверу нужна отдельная локальная база данных, которая никак не связана с базой основного сервера мониторинга. Я для простоты в качестве такой базы использую sqlite. Для proxy этого вполне достаточно. Так что наша установка будет разделена на этапы:
- Непосредственно установка zabbix proxy.
- Создание базы данных.
- Подключение к основному серверу мониторинга.
- Подключение zabbix agent через zabbix proxy.
Приступаем к установке. Подключаем репозиторий заббикса:
Устанавливаем прокси и агента. Агент, кстати, ставить не обязательно, но я обычно ставлю, чтобы мониторить сам сервер.
# yum install zabbix-agent zabbix-proxy-sqlite3 zabbix-sql-scripts
Распаковываем файл со схемой базы:
Обращаю внимание на выделенную часть пути. Когда вы будете устанавливать zabbix proxy, версия может быть уже другой, а соответственно и путь к папке. Не забудьте его изменить на актуальный.
Создаем папку для базы данных и саму базу:
Устанавливаем владельцем базы заббикс:
# chown -R zabbix. /var/lib/sqlite
На этом установка заббикс прокси закончена. Мы все подготовили, теперь ее надо правильно настроить и подключить к серверу. Займемся этим.
")




")