

30 декабря 2021 г.
- Introduction
- How does it work?
- Implementation
- Off-chain code
- Creating the Merkle root
- Creating a Merkle proof
- On-chain code
- Merkle proofs and rollups don’t mix
- Conclusion
- Была ли эта страница полезной?
- Merkle Proofs in Bitcoin
- Merkle Proofs in Ethereum
- Patricia Trees
- Что такое дерево Меркла
- Кто создал концепцию
- В чем смысл концепции: объясняем на простом примере
- Как работает концепция и при чем тут деревья
- Как хеш-дерево защищает данные
- Дисклеймер
- What Is a Merkle Root?
- Key Takeaways
- Understanding a Merkle Root
- How Bitcoin’s Algo Hashes Transactions
- What Is A Merkle Root?
- History of The Merkle Tree
- Hashing Data on Bitcoin
- Bitcoin Block Metadata
- Validating Blocks Using the Merkle Tree
- Conclusion
Introduction
Ideally we’d like to store everything in Ethereum storage, which is stored across thousands of computers and has
extremely high availability (the data cannot be censored) and integrity (the data cannot be modified in an
unauthorized manner), but storing a 32-byte word typically costs 20,000 gas. As I’m writing this, that cost is
equivalent to $6.60. At 21 cents per byte this is too expensive for many uses.
To solve this problem the Ethereum ecosystem developed many alternative ways to store data in a decentralized
fashion. Usually they involve a tradeoff between availability
and price. However, integrity is usually assured.
How does it work?
In theory we could just store the hash of the data on chain, and send all the data in transactions that require it. However, this is still too expensive. A byte of data to a transaction costs about 16 gas, currently about half a cent, or about $5 per kilobyte. At $5000 per megabyte, this is still too expensive for many uses, even without the added cost of hashing the data.
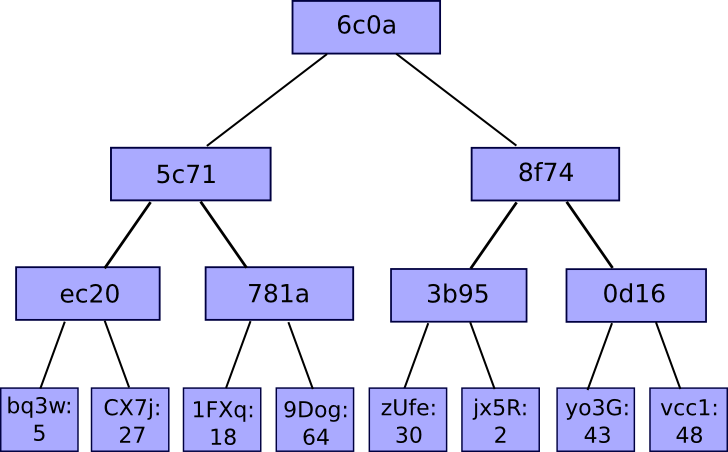
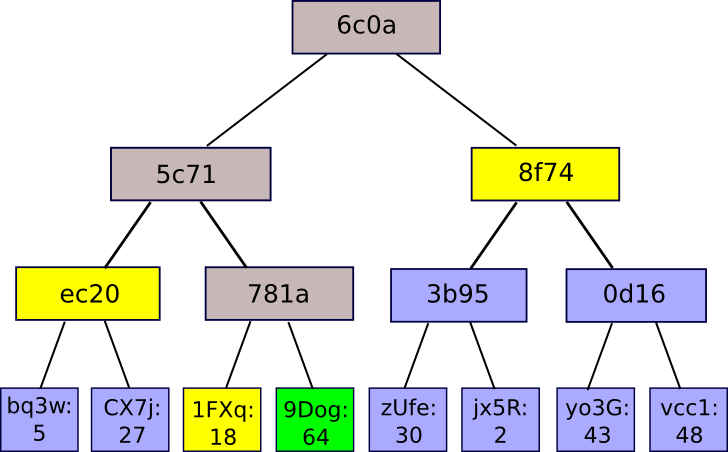
The solution is to repeatedly hash different subsets of the data, so for the data that you don’t need to send you can just send a hash. You do this using a Merkle tree, a tree data structure where each node is a hash of the nodes below it:

(opens in a new tab)
The root hash is the only part that needs to be stored on chain. To prove a certain value, you provide all the hashes that need to be combined with it to obtain the root. For example, to prove C you provide D, H(A-B), and H(E-H).

(opens in a new tab)
Implementation
The sample code is provided here(opens in a new tab).
Off-chain code
In this article we use JavaScript for the off-chain computations. Most decentralized applications have their off-chain component in JavaScript.
Creating the Merkle root
First we need to provide the Merkle root to the chain.
We use the hash function from the ethers package(opens in a new tab).
Encoding each entry into a single 256-bit integer results in less readable code than using JSON, for example. However, this means significantly less processing to retrieve the data in the contract, so much lower gas costs. You can read JSON on chain(opens in a new tab), it’s just a bad idea if avoidable.
The ethers hash function expects to get a JavaScript string with a hexadecimal number, such as 0x60A7, and responds with another string with the same structure. However, for the rest of the code it’s easier to use BigInt, so we convert to a hexadecimal string and back again.
This function is symmetrical (hash of a xor(opens in a new tab) b). This means that when we check the Merkle proof we don’t need to worry about whether to put the value from the proof before or after the calculated value. Merkle proof checking is done on chain, so the less we need to do there the better.
Warning:
Cryptography is harder than it looks.
The initial version of this article had the hash function hash(a^b).
That was a bad idea because it meant that if you knew the legitimate values of a and b you could use b' = a^b^a' to prove any desired a' value.
With this function you’d have to calculate b' such that hash(a') ^ hash(b') is equal to a known value (the next branch on the way to root), which is a lot harder.
When the number of values is not an integer power of two we need to handle empty branches. The way this program does it is to put zero as a place holder.

(opens in a new tab)
This function «climbs» one level in the Merkle tree by hashing the pairs of values at the current layer. Note that this is not the most efficient implementation, we could have avoided copying the input and just added hashEmpty when appropriate in the loop, but this code is optimized for readability.
To get the root, climb until there is only one value left.
Creating a Merkle proof
A Merkle proof is the values to hash together with the value being proved to get back the Merkle root. The value to prove is often available from other data, so I prefer to provide it separately rather than as part of the code.
On-chain code
Finally we have the code that checks the proof. The on-chain code is written in Solidity(opens in a new tab). Optimization is a lot more important here because gas is relatively expensive.
//SPDX-License-Identifier: Public Domain
pragma solidity ^0.8.0;

I wrote this using the Hardhat development environment(opens in a new tab), which allows us to have console output from Solidity(opens in a new tab) while developing.
// Extremely insecure, in production code access to
// this function MUST BE strictly limited, probably to an
merkleRoot = _merkleRoot;
} // setRoot
Set and get functions for the Merkle root. Letting everybody update the Merkle root is an extremely bad idea in a production system. I do it here for the sake of simplicity for sample code. Don’t do it on a system where data integrity actually matters.
return hash(hash(_a) ^ hash(_b));
This function generates a pair hash. It is just the Solidity translation of the JavaScript code for hash and pairHash.
Note: This is another case of optimization for readability. Based on the function definition(opens in a new tab), it might be possible to store the data as a bytes32(opens in a new tab) value and avoid the conversions.
// Verify a Merkle proof
uint temp = _value;
return temp == merkleRoot;
} // MarkleProof
Merkle proofs and rollups don’t mix
Merkle proofs don’t work well with rollups. The reason is that rollups write all the transaction data on L1, but process on L2. The cost to send a Merkle proof with a transaction averages to 638 gas per layer (currently a byte in call data costs 16 gas if it isn’t zero, and 4 if it is zero). If we have 1024 words of data, a Merkle proof requires ten layers, or a total of 6380 gas.
Looking for example at Optimism(opens in a new tab), writing L1 gas costs about 100 gwei and L2 gas costs 0.001 gwei (that is the normal price, it can rise with congestion). So for the cost of one L1 gas we can spend a hundred thousand gas on L2 processing. Assuming we don’t overwrite storage, this means that we can write about five words to storage on L2 for the price of one L1 gas. For a single Merkle proof we can write the entire 1024 words to storage (assuming they can be calculated on chain to begin with, rather than provided in a transaction) and still have most of the gas left over.
Conclusion
In real life you might never implement Merkle trees on your own. There are well known and audited libraries you can use and generally speaking it is best not to implement cryptographic primitives on your own. But I hope that now you understand Merkle proofs better and can decide when they are worth using.
Note that while Merkle proofs preserve integrity, they do not preserve availability. Knowing that nobody else can take your assets is small consolation if the data storage decides to disallow access and you can’t construct a Merkle tree to access them either. So Merkle trees are best used with some kind of decentralized storage, such as IPFS.
Последнее редактирование: , Invalid DateTime
Была ли эта страница полезной?
First, the basics. A Merkle tree, in the most general sense, is a way of hashing a large number of «chunks» of data together which relies on splitting the chunks into buckets, where each bucket contains only a few chunks, then taking the hash of each bucket and repeating the same process, continuing to do so until the total number of hashes remaining becomes only one: the root hash.
So what is the benefit of this strange kind of hashing algorithm? Why not just concatenate all the chunks together into a single big chunk and use a regular hashing algorithm on that? The answer is that it allows for a neat mechanism known as Merkle proofs:
Merkle Proofs in Bitcoin
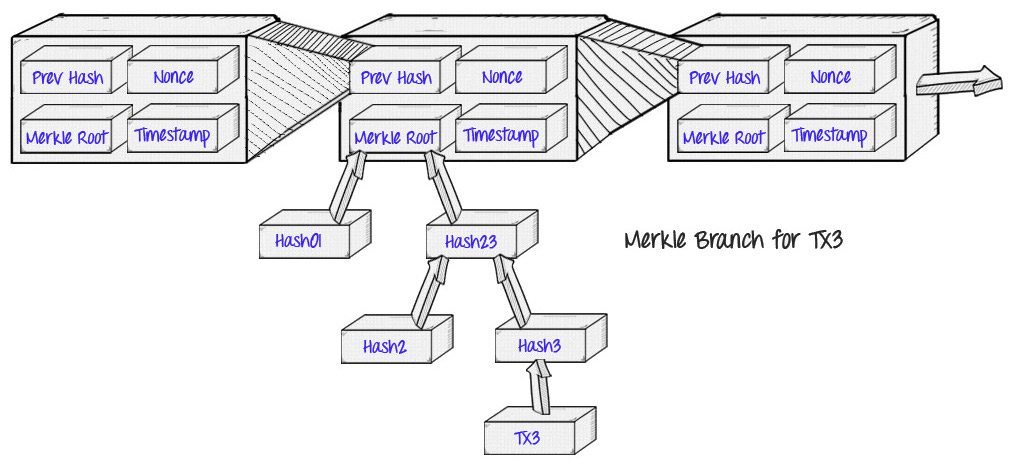
- A hash of the previous header
- A timestamp
- A mining difficulty value
- A proof of work nonce
- A root hash for the Merkle tree containing the transactions for that block.
This gets us pretty far, but Bitcoin-style light clients do have their limitations. One particular limitation is that, while they can prove the inclusion of transactions, they cannot prove anything about the current state (eg. digital asset holdings, name registrations, the status of financial contracts, etc). How many bitcoins do you have right now? A Bitcoin light client can use a protocol involving querying multiple nodes and trusting that at least one of them will notify you of any particular transaction spending from your addresses, and this will get you quite far for that use case, but for other more complex applications it isn’t nearly enough; the precise nature of the effect of a transaction can depend on the effect of several previous transactions, which themselves depend on previous transactions, and so ultimately you would have to authenticate every single transaction in the entire chain. To get around this, Ethereum takes the Merkle tree concept one step further.
Merkle Proofs in Ethereum
- Transactions
- Receipts (essentially, pieces of data showing the effect of each transaction)
- State
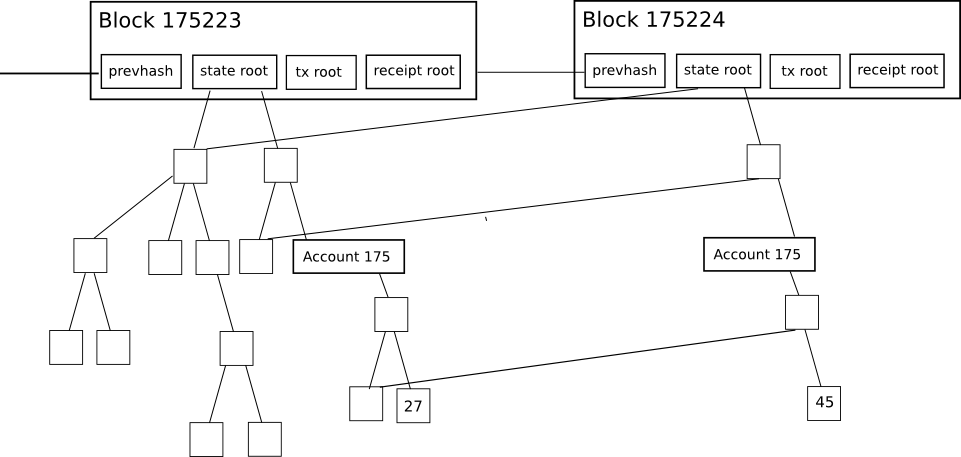
This allows for a highly advanced light client protocol that allows light clients to easily make and get verifiable answers to many kinds of queries:
- Has this transaction been included in a particular block?
- Tell me all instances of an event of type X (eg. a crowdfunding contract reaching its goal) emitted by this address in the past 30 days
- What is the current balance of my account?
- Does this account exist?
- Pretend to run this transaction on this contract. What would the output be?
The first is handled by the transaction tree; the third and fourth are handled by the state tree, and the second by the receipt tree. The first four are fairly straightforward to compute; the server simply finds the object, fetches the Merkle branch (the list of hashes going up from the object to the tree root) and replies back to the light client with the branch.
The fifth is also handled by the state tree, but the way that it is computed is more complex. Here, we need to construct what can be called a Merkle state transition proof. Essentially, it is a proof which make the claim «if you run transaction on the state with root , the result will be a state with root , with log and output » («output» exists as a concept in Ethereum because every transaction is a function call; it is not theoretically necessary).
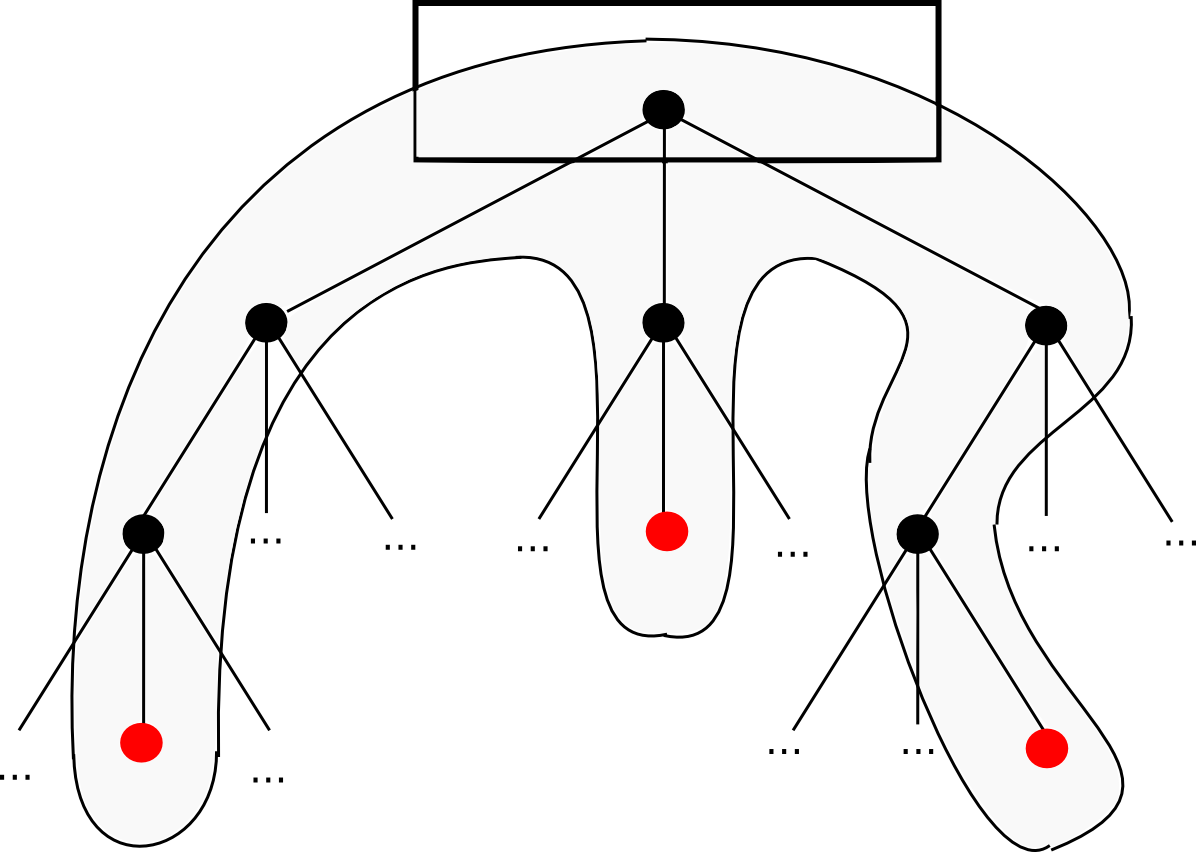
Patricia Trees
It was mentioned above that the simplest kind of Merkle tree is the binary Merkle tree; however, the trees used in Ethereum are more complex — this is the «Merkle Patricia tree» that you hear about in our documentation. This article won’t go into the detailed specification; that is best done by this article and this one, though I will discuss the basic reasoning.
Binary Merkle trees are very good data structures for authenticating information that is in a «list» format; essentially, a series of chunks one after the other. For transaction trees, they are also good because it does not matter how much time it takes to edit a tree once it’s created, as the tree is created once and then forever frozen solid.
{ "0000000000000000000000000000000000000001": { "balance": "1" }, "0000000000000000000000000000000000000002": { "balance": "1" }, "0000000000000000000000000000000000000003": { "balance": "1" }, "0000000000000000000000000000000000000004": { "balance": "1" }, "102e61f5d8f9bc71d0ad4a084df4e65e05ce0e1c": { "balance": "1606938044258990275541962092341162602522202993782792835301376" }
}Unlike transaction history, however, the state needs to be frequently updated: the balance and nonce of accounts is often changed, and what’s more, new accounts are frequently inserted, and keys in storage are frequently inserted and deleted. What is thus desired is a data structure where we can quickly calculate the new tree root after an insert, update edit or delete operation, without recomputing the entire tree. There are also two highly desirable secondary properties:
- The depth of the tree is bounded, even given an attacker that is deliberately crafting transactions to make the tree as deep as possible. Otherwise, an attacker could perform a denial of service attack by manipulating the tree to be so deep that each individual update becomes extremely slow.
- The root of the tree depends only on the data, not on the order in which updates are made. Making updates in a different order and even recomputing the tree from scratch should not change the root.
The Patricia tree, in simple terms, is perhaps the closest that we can come to achieving all of these properties simultaneously. The simplest explanation for how it works is that the key under which a value is stored is encoded into the «path» that you have to take down the tree. Each node has 16 children, so the path is determined by hex encoding: for example, the key hex encoded is 6 4 6 15 6 7, so you would start with the root, go down the 6th child, then the fourth, and so forth until you reach the end. In practice, there are a few extra optimizations that we can make to make the process much more efficient when the tree is sparse, but that is the basic principle. The two articles mentioned above describe all of the features in much more detail.
Now we can start to understand the hashing process. Hash the hashes of the «leaves» and include that as part of the 2nd level branches that those leaves are attached to (these are called child nodes and parent nodes). Now hash the hashes of those hashes and include that as part of the third level branches. And so on. (And if you had more than 8 transactions, all you need are more levels to the pyramid.)
So now you have a root node that effectively has a hash that verifies the integrity of all of the transactions. If one transaction is added/removed or changed it will change the hash of its parent. Which will change the hash of its parent, and so on, resulting in the root node’s hash (which is the Merkle root) changing as well.
In short, the Merkle tree creates a single value that proves the integrity of all of the transactions under it. Satoshi could have just included the hash of a big list of all of the transactions in the Bitcoin header. But if he had done that that would have required you to hash the entire list of transactions in order to verify its integrity. With this way, even if there are an extremely large number of transactions the work you need to do (and the number of hashes you need to request/download) in order to verify the integrity is only log(O).

Airdrop — популярный способ раздать токены проекта сообществу. Настолько популярный, что порой приводит к заторам в сети Ethereum и огромным комиссиям в транзакциях. Совсем недавно подобная механика, которая использовалась для голосования на бирже FCoin, привела к печальным последствиям для всей сети Ethereum. О том, как можно модифицировать механизм airdrop, в специальном материале для ForkLog рассказал Head of Research Smartz Сергей Прилуцкий.
Хороший алгоритм позволяет решить сразу несколько проблем смарт-контрактов, которые оперируют большими списками адресов пользователей. Дело в том, что положить в контракт список даже из нескольких тысяч адресов и позволить этому набору адресов что-то делать в контракте напрямую не получится — в блокчейне экономится каждый байт и это слишком дорого.
Для решения задачи необходимо в коде контракта определить, принадлежит ли данный адрес списку «белых» адресов. Если да, то разрешить произвести нужное действие. Предлагаемый вариант позволяет довольно просто решить эту проблему, держа в контракте всего одно число. Алгоритм блестящего криптографа Ральфа Меркла широко используется в практически любом децентрализованном софте для обеспечения целостности наборов данных.
Airdrop и ACL
Есть такая практика — выпустить свой токен и разослать его небольшие количества по десяткам тысяч адресов, у которых на балансе есть, для примера, хотя бы 1 ETH. Такой спам крайне популярен сейчас для продвижения собственных токенов. Мало кому нравится появление на своем балансе чьих-то неведомых токенов. Тем не менее, проектам это нужно, и заказы на airdrop очень популярны. Делается это обычно по старинке, вот так (на примере Ethereum, но подходят и другие блокчейны с контрактами, EOS, например):
- парсят блокчейн и находят много адресов по заданным критериям;
- создают адрес, на котором хранится достаточно токенов для рассылки всем из списка, либо предусматривают в контракте токена возможность создавать (минтить) нужное количество токенов заданному адресу (при отправке транзакции со специального привилегированного адреса);
- кладут на этот адрес достаточно Ethereum, чтобы хватило на оплату комиссии за каждую отправку токенов пользователю;
- запускают скрипт рассылки, который перебирает адреса и для каждого создает транзакцию, переводящую (или минтящую) токены заданному адресу.
То есть это просто проход по куче адресов и рассылка токенов каждому. В децентрализованных системах такая push-стратегия обычно довольно хромая, стоит дорого, порождает дыры в безопасности и вообще — это спам. В числе ее недостатков:
- на комиссии уходит много средств (чем больше адресов, тем больше комиссия). Кроме того, в момент рассылки комиссия может расти, т.к. растет нагрузка на сеть, стоимость транзакции растет тоже;
- рассылка требует написания скрипта, который будет слать транзакции, а в скрипте зашит секретный ключ, который дает доступ к куче токенов;
- рассылку необходимо запрограммировать и уметь продолжить с места, где все сломалось.
При этом есть решение гораздо проще, которое, как принято в децентрализованных сетях, большую часть работы отдает софту на стороне клиента. Это контроль доступа с использованием дерева Меркла — крайне удобной структуры данных, чтобы хранить в контракте лишь одно число фиксированного размера (merkleRoot), которое содержит в себе информацию обо всех включенных в дерево данных (об огромном списке адресов получателей, например).
Никакого волшебства здесь нет: информацию, доказывающую, что адрес присутствует в списке разрешенных, клиентский код предоставляет самостоятельно, делая относительно объемные вычисления, и избавляя контракт от необходимости просмотра огромного списка адресов. Структура дерева Меркла крайне полезна для множества задач.
Так, этот алгоритм годится для создания огромных ACL (Access Control List), которые позволяют предоставить доступ к некоторой функции контракта миллионам аккаунтов. Для этого нужно записать в контракт единственное число для проверки принадлежности аккаунта к списку.
Рассмотрим схему с airdrop, т.к. она сейчас крайне востребована на рынке и является простым и демонстративным примером смарт-контрактов с большими ACL.
Для начала стоит напомнить, что смарт-контракт сначала деплоится в сеть Ethereum, после чего получает свой собственный адрес и баланс в сети, а далее принимает и процессит внутри себя входящие транзакции.
В схеме merkle-airdrop токены не рассылаются по адресам, а пользователи сами «требуют» свои токены, отправляя транзакции в контракт и оплачивая комиссию. Секрет в том, что в транзакцию пользователи добавляют данные, позволяющие контракту легко проверить, находятся ли они в «белом» списке адресов, причем сам список контракту помнить совершенно не обязательно. Сам контракт при этом является крайне экономным, ему необходимо всего лишь одно (!) число для списка адресов любого (!) размера — именно в этом суть этого отличного алгоритма. А еще такой контракт крайне прост в запуске, после которого не требует вообще никакой поддержки, и, за счет этой простоты, еще и крайне безопасен в использовании. Но об этих моментах чуть позже.
Вот как приблизительно работает вся схема с контрактом merkle-airdrop:
- В сеть выкладывается (или уже присутствует там) контракт токена.
- Создается список адресов, которым позволено «потребовать» свои токены. Список генерируется на основе анализа блокчейна, собирается на сайте или иным способом.
- Все адреса помещаются в один довольно массивный файл, который будет доступен публично по некоторому URL. Например, можно поместить его в протокол IPFS, но можно использовать любой способ залить файл и прочитать его потом из клиентского браузера.
- На файл «натравливается» скрипт, который из всех содержащихся в нем адресов строит Merkle tree, и получает один единственный хеш — Merkle root. Этот root — главный параметр нашего контракта, который будет выдавать токены.
- Контракт merkle-airdrop выкладывается в сеть. При выкладке он запоминает merkle root и адрес контракта-токена, чтобы он мог делать трансфер этого токена получателям.
- На баланс airdrop-контракта кладется большое число токенов (обычным трансфером), достаточное чтобы выдать всем участникам списка.
- Теперь у airdrop-контракта доступна снаружи функция claim-tokens-by-merkle-proof, которая принимает на вход от пользователя merkle-proof — доказательство того, что пользователь есть в том самом большом «белом» списке адресов. Если доказательство верное, то контракт выполняет transfer() со своего адреса и переводит пользователю токены.
А вот что происходит в браузере клиента (все операции проводятся клиентским JavaScript прямо на странице DApp-a):
- Находит свой адрес в «белом» списке, который публично размещен где-то в Сети (например в IPFS) и убеждается, что имеет право на токены.
- Строит из всех адресов в списке дерево Меркла, и из него получает тот самый merkle-proof, который представляет собой несколько чисел (хешей), их количество зависит от размера списка, но по сравнению с ним очень мало, например для ~100 000 адресов достаточно ~17 хешей (размер merkle-proof: log₂N, где N — число элементов).
- Отправляет в контракт транзакцию, вызывающую функцию claim-tokens-by-merkle-proof и отправляющую туда полученный merkle-proof. Контракту остается проверить proof (при помощи сохраненного merkle-root) и сделать transfer() токенов, если proof верный.
- Контракт запоминает, кому он выдал токены, чтобы предотвратить повторную выдачу.
Общими словами merkle-proof можно описать как «путь, которым можно пройти от адреса пользователя по дереву Меркла до самого merkle-root». Это довольно серьезная вычислительная работа и лишние данные, которые мы таким образом вынесли из контракта, сэкономив самое дорогое в блокчейне — хранилище.
Merkle-proof доказательство состоит из log₂N хешей (с округлением вверх до целого). Каждый хеш — такого же размера как и merkle-root, который мы записали в контракт-airdrop. То есть для списка из 1024 адресов, пользователь должен предоставить 10 хешей, а для ~4 млрд адресов — всего 32 хеша. Именно в протоколе построения и предъявления доказательства и прячется основная «фишка» контракта — хранение минимального количества информации для определения принадлежности некоторых данных к очень большому списку. Причем чем список больше, тем больше выигрыш.
В реальности контракт дополняется еще и возможностью забрать неиспользованные токены, обновить merkle root и ввести ограничения по времени, например запретить выдачу токенов после некоторого времени. Контракт несложно дорабатывается для раздачи произвольного количества токенов каждому адресу, в этом случае в файле хранятся не просто адреса получателей, но и необходимые суммы токенов, и слегка дорабатывается функция для проверки merkle-proof, но общий алгоритм от этого почти не меняется.
Преимущества и недостатки merkle-airdrop
Отдельно можно выделить преимущества и недостатки вышеуказанного метода по сравнению с традиционной рассылкой скриптом:
- транзакция, требующая токены, стоит мало газа, причем это число — константа, зависящая от размера «белого» списка;
- после запуска контракта он не требует ни малейшей поддержки, вся активность обеспечивается пользователями;
- позволяет работать со списками практически произвольного размера с минимальным расходованием storage блокчейна.
- надо куда-то выкладывать публичный список адресов;
- клиентскому коду необходимо просмотреть все адреса в «белом» списке и выполнить довольно ресурсоемкий код.
В данном алгоритме нет никаких секретов, такой выигрыш по памяти контракта щедро «оплачен» работой кода на клиентской стороне по проверке принадлежности к списку. Такой подход крайне удачно демонстрирует различие моделей использования смарт-контрактов в сравнении с традиционными централизованными системами.
Традиционная рассылка токенов скриптом в ответ может противопоставить лишь простую и понятную схему работы. А усилия программиста для запуска обычного airdrop в разы превышают усилия для выкладки merkle-airdrop контракта, запущенный скрипт надо мониторить, чтобы не отвалился посередине списка, чтобы у него не закончились средства на комиссии за транзакции, следить, чтобы никто не украл ключ, которым скрипт подписывает транзакции. Плюс, если у вас есть файл с адресами, собственно программист вам и не нужен — деплой такого контракта крайне просто осуществить через публичные сервисы.
Помимо основного смарт-контракта, полный DApp для merkle-airdrop имеет некоторые особенности в реализации. В схеме merkle-airdrop большое количество работы возлагается на код в браузере пользователя, например построение merkle proof, для которого нужно пробежать по всему списку адресов. Сам список адресов надо где-то публично хранить, а для пользователя это должно быть не сложнее чем залить файл на сервер.
Поэтому в конструкторе merkle-airdrop на платформе Smartz разработчикам пришлось реализовать загрузку списка адресов в IPFS, отдачу этого списка клиенту и сделать для всего этого специальные JS-виджеты для работы с загруженным в IPFS файлом с адресами. В финальной версии DApp-а планируется сохранять информацию об IPFS напрямую в контракте, чтобы иметь 100% необходимых для airdrop данных в блокчейне. На данный момент выпущена рабочая alpha-версия, которая без проблем умеет раздавать токены по большому списку, но элементы управления пока не совсем удобны. Такой же конструктор airdrop для токенов EOS разрабатывается параллельно, поскольку имеет похожий интерфейс и внутреннюю логику.
В целом, тенденция к утяжелению клиентского кода имеет место во всех продвинутых решениях, и merkle tree — лишь первый из интересных алгоритмов. Другие схемы, такие как кольцевые подписи или zkSNARKs также требуют серьезных вычислений на стороне браузера, поэтому компания Smartz готовится к реализации больших и сложных JS компонентов в конструкторах интерфейсов на клиентской стороне.
Главное «преимущество» традиционной рассылки токенов по списку в том, что эта схема позволяет закинуть токены даже тем, кто не желает этого. Есть и особые извращения, когда токенов можно разослать так мало, что биржа даже не позволяет делать с ними транзакции, и юзеры вынуждены наблюдать эти “ошметки” на своих адресах не имея возможности от них избавиться.
Проблема airdrop, когда компания раздает часть токенов системы в комьюнити, конечно крайне важна для развития проектов. Но такое решение, по мнению команды Smartz, недружелюбно к пользователям и неэффективно в целом. Да и вообще смарт-контракты крайне тяготеют к концепции «pull», а не «push», в которой именно пользователи сети являются инициаторами и контролерами бизнес-процессов, а истории, когда кто-то централизованно что-то навязывает десяткам тысяч пользователей, постепенно уходят в прошлое.
Нашли ошибку в тексте? Выделите ее и нажмите CTRL+ENTER
Рассылки ForkLog: держите руку на пульсе биткоин-индустрии!
Количество информации, которая окружает современного человека, стремительно растет на фоне цифровизации. Данные нужно как-то хранить. Желательно, чтобы они не занимали много места и к ним можно было бы легко получить доступ. Решением проблемы стала концепция деревьев Меркла. Рассказываем, как она работает.
Хотите обсудить эффективность деревьев Меркла с криптоэнтузиастами или задать вопросы по концепции? Приходите в Телеграм-канал BeInCrypto. У нас не только новости и обзоры, но и живое общение с трейдерами, инвесторами и просто фанатами криптовалюты. Задавайте вопросы экспертам, участвуйте в промоакциях, будьте в курсе вместе с BeInCrypto.
В этой статье:
- Что такое дерево Меркла
- Кто создал концепцию
- В чем смысл концепции: объясняем на простом примере
- Как работает концепция и при чем тут деревья
- Как хеш-дерево защищает данные
Что такое дерево Меркла
Дерево Меркла (анг. Merkle tree) – это концепция работы с данными. У нее есть и другие названия. Дерево Меркла также называют деревом хешей или хеш-деревом. При чем тут деревья, мы выясним чуть позже. А пока сосредоточимся на хешах.
Хеш или хеш-функция – технология преобразования записей в уникальный набор символов, который присущ только этому конкретному массиву данных. Детали конвертации зависят от выбранного алгоритма. Возьмем SHA-256, в котором число – количество бит (единица измерения количества информации). На этом алгоритме работает самая капитализированная криптовалюта – биткоин (BTC).
Хеширование на SHA-256 позволяет привести любой массив данных в строку из 64 символов. Вот пример:
Согласитесь, строчка из 64 символов «весит» меньше, чем томик Бродского. Поэтому хранение информации в хешированном виде не требует большого объема памяти. Следовательно, не нужно тратиться на организацию дополнительных хранилищ. При этом чем меньше запись – тем легче ей оперировать. Поэтому хеширование, в том числе, ускоряет работу систем.
В переводе с английского hash (хеш) – мешанина.
Кто создал концепцию
Автор концепции – американский криптограф Ральф Меркл. Он предложил схему компоновки данных в 1979 году. Но настоящая популярность пришла к концепции лишь с появлением криптовалют.
По состоянию на момент написания обзора, Ральф Меркл занят разработками в сфере молекулярных нанотехнологий. Вот одна из его лекций:
https://youtube.com/watch?v=cdKyf8fsH6w%3Ffeature%3Doembed
В чем смысл концепции: объясняем на простом примере
Смысл концепции дерева Меркла в том, чтобы как можно эффективнее систематизировать информацию и организовать ее безопасное хранение.
Представьте, что у вас есть коллекция книг: одни – на английском, другие – редкие экземпляры классиков, третьи – коллекционные издания, четвертые – энциклопедии. Они лежат в одной куче на арендованном у малознакомого человека складе. Некоторые – в громоздких упаковках, другие – в пакетах. Если вам потребуется определенная книга из коллекции на поиски, вероятно, уйдет много времени. При этом никто не гарантирует, что интересующий том будет с сохранности.
Неразбериха – не единственный недостаток такого способа хранения книг. Складское помещение могут ограбить. При этом владелец книг вряд ли сможет сразу же обнаружить потерю, так как разобраться в куче литературы будет непросто.
Вот какое решение проблемы предлагает концепция Меркла:
- Полная систематизация библиотеки. Все экземпляры нужно избавить от упаковок, пакетов и другого «мусора», который может усложнить поиск. Каждая книга должна быть промаркирована и привязана к другой. Например, если мы говорим о сборнике стихов в трех томах, каждую из книг нужно снабдить отметкой о ее принадлежности к коллекции. При этом сами издания необходимо держать рядом. Также нужно сделать отметки о принадлежности книг конкретному человеку.
- Создание копий состава библиотеки. Информации о метках книг и расположения каждого издания. Дубликаты записей необходимо хранить в безопасном месте. В случае кражи или подмены какого-либо экземпляра из коллекции, эта информация поможет быстро выявить изменения.
- Организация безопасного хранения. Чтобы не полагаться на охранников и других третьих лиц, можно самостоятельно организовать систему оповещения, которая будет присылать сигналы на смартфон, в случае попытки проникновения в помещение.
Вот каких результатов, применимо к книгам, помогает добиться концепция Меркла:
- Контроль над коллекцией.
- Повышение эффективности системы хранения.
- Организация безопасного хранения без обязательного доверия третьей стороне.
С появлением блокчейна и криптовалют концепция деревьев Меркла нашла новое применение – с ее помощью можно организовать безопасное, высокоэффективное хранение цифровых данных.
Как работает концепция и при чем тут деревья
Теперь давайте разберемся, при чем же тут деревья. Для этого нужно подключить воображение и посмотреть на схематичное изображение хеш-дерева на картинке ниже. Вот что на ней изображено:
- Желтые блоки (data block 1,2,3,4) – блоки с исходной информацией, какой именно – не важно. Например, в них могут быть стихи классиков.
- Блоки hash (0-0, 0-1, 1-0, 1-1) – хеши желтых блоков. Помните, как мы превращали стихи в строку из 64 символов? Здесь произошло то же самое. Только длинные хеши схематично отобразили цифрами 0-0, 0-1, 1-0, 1-1.
- Чтобы уменьшить количество информации, которую нужно хранить, 4 хеша желтых блоков превратили в 2 хеша (hash 0 и hash 1). Для этого каждую из пар хешей вновь прогнали через хеширование. На выходе получили 2 новых хеша – по одному на каждую пару.
- Осталось 2 хеша. Вновь прогоняем пару через хеширование и получаем на выходе 1 хеш.
- На выходе получаем «дерево» с одной «макушкой», в которой содержится конечный хеш (top hash).

Схема только что помогла нам значительно уменьшить размер стихов. При этом мы получили четкую последовательность шифрования.
Фрагменты данных, из которых, в итоге, составляют top hash, называют листьями.
Как хеш-дерево защищает данные
В этом месте на арену выходит децентрализованный принцип хранения информации на блокчейне. Напомним, блокчейн – это цепочка блоков, каждый из которых состоит из различной информации. Каждый блок блокчейна, как показано в схеме дерева Меркла, привязан к предыдущему.
Копии цепочек блока хранятся на компьютерах участников сети. Например, в случае с биткоином, они находятся на сетевых узлах – нодах. Такой подход к хранению данных называют децентрализованным.
А теперь представим, что кто-то попытался изменить информацию в одном из блоков биткоина. Подмена хотя бы одного символа приведет к потере согласования системы, ведь top hash изменится. Чтобы определить изменения, система может сравнить записи с копиями блокчейна других участников сети (ведь мошенник, который попытался изменить блок, не может одновременно получить доступ ко всем сетевым узлам биткоина, а значит большая часть копий будет содержать достоверную информацию).
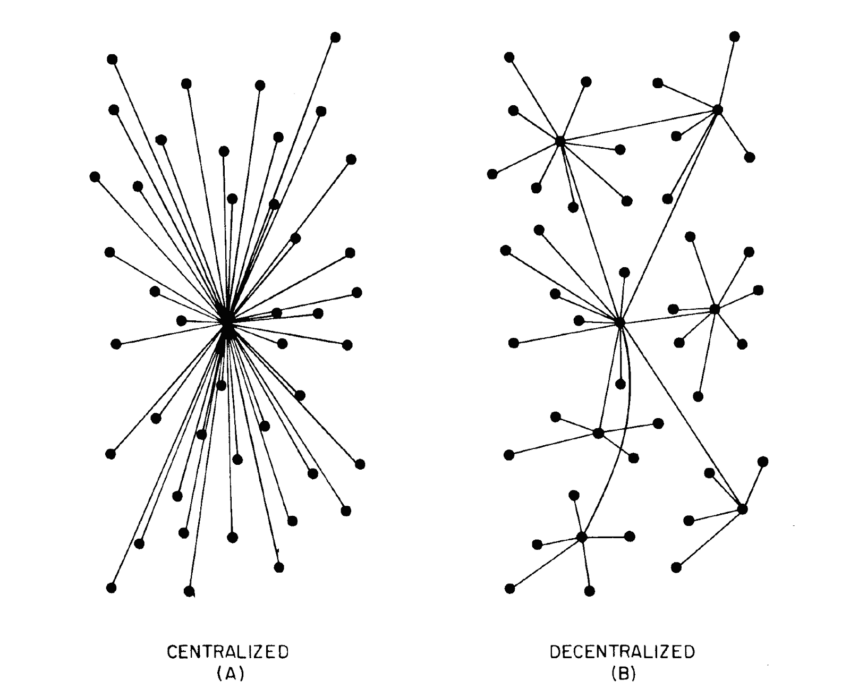
В случае, если бы база данных была в одном экземпляре и находилась под контролем головного центра управления, злоумышленник, получив доступ к ней, мог бы безвозвратно изменить данные. Поэтому централизованные системы небезопасны.
Вот как схематично можно представить два подхода к хранению данных: централизованный (с единым центром управления) и децентрализованный (с несколькими центрами контроля, связанными друг с другом в одной сети):
Деревья Меркла на блокчейне помогают подтверждать информацию. Например, криптобиржи могут использовать схему, чтобы предоставить клиентам доказательство сохранности активов.
Читайте свежие новости криптовалют на портале BeInCrypto и присоединяйтесь к дискуссии в нашем Телеграм-канале.
Дисклеймер
Вся информация на нашем сайте публикуется, основываясь на принципах добросовестности и только для общего ознакомления. Любые действия, основанные на информации, публикуемой на этом сайте, предпринимаются читателем исключительно под его собственную ответственность.
В разделе «База знаний» нашей приоритетной задачей является предоставление высококачественной информации. Мы тщательно определяем, изучаем и создаем образовательный контент, полезный для наших читателей.
Для поддержания этих стандартов на высоком уровне и дальнейшего создания качественного контента наши партнеры могут выплачивать нам вознаграждение за размещение информации о них в наших статьях. Однако такие выплаты никак не влияют на процессы создания объективного, честного и полезного контента.
What Is a Merkle Root?
Key Takeaways
- A Merkle root is a simple mathematical way to verify the data on a Merkle tree.
- Merkle roots are used in cryptocurrency to make sure data blocks passed between peers on a peer-to-peer network are whole, undamaged, and unaltered.
- Merkle roots are central to the computation required to maintain cryptocurrencies like bitcoin and ether.
Understanding a Merkle Root
Effectively, you get an upside-down binary tree, with each node of the tree connecting to only two nodes below it (hence the name «binary tree»). It has one root hash at the top, which connects to two hashes at level one, each of which again connects to the two hashes at level three (leaf-level), and the structure continues depending upon the number of transaction hashes.
The hashing starts at the lowest level (leaf-level) nodes, and all four hashes are included in the hash of nodes that are linked to it at level one. Similarly, hashing continues at level one, which leads to hashes of hashes reaching to higher levels, until it reaches the single top root hash.
Enter the Merkle root, which further speeds up verification. Since it carries all the information about the entire tree, one only needs to verify that transaction hash, its sibling-node (if it exists), and then proceed upward until it reaches the top.
Essentially, the Merkle tree and Merkle root mechanism significantly reduce the levels of hashing to be performed, enabling faster verification and transactions.
How Bitcoin’s Algo Hashes Transactions
Date: March 3, 2022

Unlike a physical tree in the real world, tree structures are usually reversed with the root node at the top and branches spreading downward, each terminating in one or more leaf nodes.

What Is A Merkle Root?
A Merkle root is the ultimate hash that combines all hashes in the Merkle tree. Once all the transactions in a Merkle tree are hashed together, they produce the final hash known as the Merkle root.
Let’s say you have 200 transactions at the bottom of the Merkle tree, then those are hashed to 50 transactions, then 10, then 5, then 1. The final hash would represent all previous hashes in a group and used as an identifier for all those transactions combined.
History of The Merkle Tree
The technology behind the Merkle Tree was patented in 1989. It’s named after Stanford professor, Ralph Merkle, who invented the technology by publishing a paper on digital signatures called “A Certified Digital Signature”.

Decades before Bitcoin was invented, cryptography was used in software development to secure data. The Merkle tree was one of the ways to verify giant batches of data and save memory.
If you have a large encrypted database and don’t want to individually verify the validity of small parts of the database, you could use the Merkle root to verify the hash data of an individual part of the database and save on memory.
Merkle’s paper was featured in the Bitcoin Whitepaper as one of the core components of Bitcoin. He remained a supporter of crypto and advocated for the advancement of DAOs (Decentralized Autonomous Organizations).
Hashing Data on Bitcoin
To understand how Merkle trees help save memory, we start at the hash. Hashing is cryptographic technology that produces a unique number for each encrypted computation.
If you compile a set of data and hash it, it will produce a number that cannot be changed for that set of data. For example, if you upload your Bitcoin private keys and hash them, then the output will be the same no matter how many times you re-hash it. If you change one number, the output hash will be different.


Bitcoin Block Metadata

As mining difficulty increases, the network consumes more energy for computation. In the past when the computation difficulty requirements were lower, people were able to mine Bitcoin on their laptops using their graphics cards.
Recently, mining work is done on ASIC miners such as AntMiners that are energy-intensive and cost tens of thousands of dollars.

Validating Blocks Using the Merkle Tree

At the highest level is the single Merkle root. Everything below it comprises the Merkle tree. There are two types of nodes below the Merkle root: leaf nodes and non-leaf nodes.

The payment verification process on Bitcoin. (Source: CoinGeek)


Conclusion
Merkle trees and Merkle roots are tools whose primary purpose is to hash cryptographic data and make it accessible for software applications.
")




")