
Tree is a non-linear data structure which organizes data in hierarchical structure and this is a recursive definition.
Tree data structure is a collection of data (Node) which is organized in hierarchical structure recursively
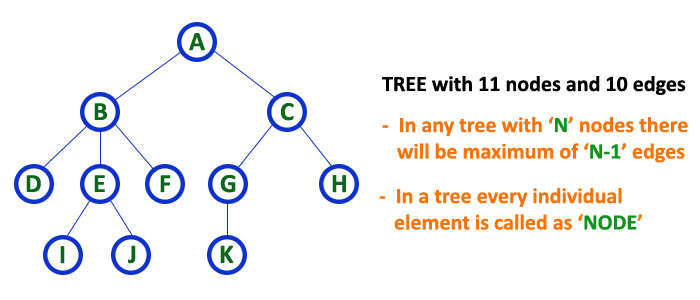
In tree data structure, every individual element is called as Node. Node in a tree data structure stores the actual data of that particular element and link to next element in hierarchical structure.
In a tree data structure, if we have N number of nodes then we can have a maximum of N-1 number of links.
An important special kind of binary tree is the binary search tree
(BST).
In a BST, each node stores some information including a unique key
value, and perhaps some associated data.
A binary tree is a BST iff, for every node n in the tree:
Here are some BSTs in which each node just stores an integer key:
These are not BSTs:
In the left one 5 is not greater than 6. In the right one 6 is not
greater than 7.
Question 2:
Using which kind of traversal (preorder, postorder, inorder, or level-order)
visits the nodes of a BST in sorted order?
Introduction
A tree is recursively defined non-linear (hierarchical) data structure. It comprises nodes linked together in a hierarchical manner. Each node has a label and the references to the child nodes. Figure 1 shows an example of a tree.
One of the nodes in the tree is distinguished as a root and we call this tree as a rooted tree. In figure 1, the node labeled A is a root of the tree. All the nodes except the root node have exactly one parent node and each node has 0 or more child nodes.
Mathematically, a tree can be defined as an acyclic, undirected, and connected graph.
In mathematics and graph theory, trees are mostly undirected but in computer science, a tree is mostly assumed to be directed. That means in the tree data structure, we don’t have references that point to the parents.
Rooted trees
A tree is a collection of nodes. An empty
tree has
no nodes. Non-empty trees have these properties:
A Family Tree
There is a great deal of terminology associated with trees, most of it
relates to family trees.
Height and depth
There are several ways to impose order among the nodes of a tree, all
centered around these two notions:
Binary trees
There are numerous ways to implement binary trees:
A first attempt
Cdirected acyclic graph (DAG) Tree traversals
A tree traversal is the process of iterating over the value stored
at each node in a tree exactly once. In the process you may actually pass
through a node more than once, but the action is performed on the value of
the node only one time. When the action is performed largely determines the
order of traversal. Sometimes performing the action at a node is referred
to as visiting.
(8)
/ (2) (21)
/ /
(1) (5) (13)
/
(3)
pre-order: 8, 2, 1, 5, 3, 21, 13
post-order: 1, 3, 5, 2, 13, 21, 8
in-order: 1, 2, 3, 5, 8, 13, 21
Traversals need be performed recursively — we use the recursion to allow us
to backtrack up the tree without repeating ourselves.
Algorithm for a pre-order traversal:
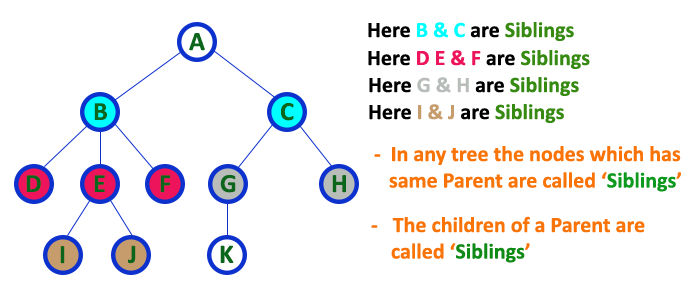
Siblings
In a tree data structure, nodes which belong to same Parent are called as SIBLINGS. In simple words, the nodes with the same parent are called Sibling nodes.
Tree Traversals
Tree traversal is a process of visiting each node of the tree exactly once. There are two types of traversals.
Pre-order traversal
In pre-order traversal, we first visit the node and recursively visit all its children. The algorithm for pre-order traversal can be written as
If we do the pre-order traversal on the tree given in Figure 1, we get A, B, E, F, C, G, J, K, D, H, I
Post-order traversal
Post-order traversal is the exact opposite of the pre-order traversal. We visit the children of the node first and only we visit the node. The algorithm for post-order traversal is
If we do the post order traversal on the tree given in Figure 1, we get E, F, B, J, K, G, C, H, I, D, A.
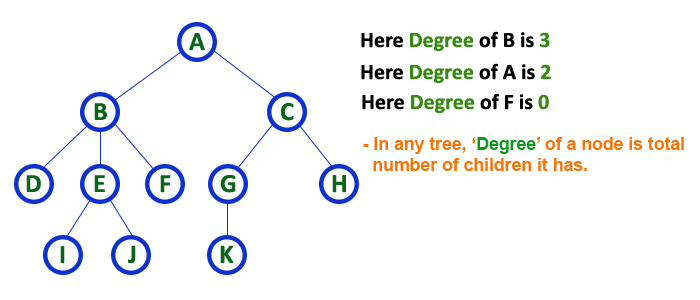
Degree
In a tree data structure, the total number of children of a node is called as DEGREE of that Node. In simple words, the Degree of a node is total number of children it has. The highest degree of a node among all the nodes in a tree is called as ‘Degree of Tree’
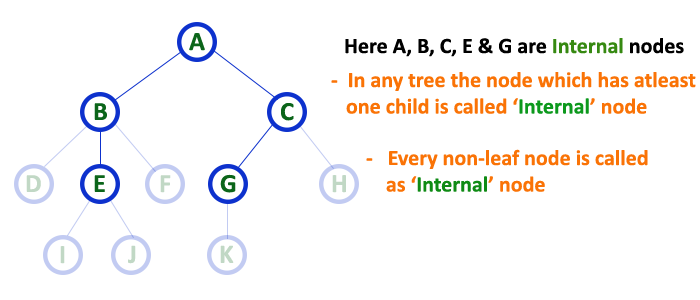
Internal Nodes
In a tree data structure, the node which has atleast one child is called as INTERNAL Node. In simple words, an internal node is a node with atleast one child.
In a tree data structure, nodes other than leaf nodes are called as Internal Nodes. The root node is also said to be Internal Node if the tree has more than one node.
Level
A node is an element of a tree. A tree is nothing but nodes linked together. Figure 2 illustrates this.
All the circle in the figure are nodes.
Root is the first node of the tree. We can consider root as an origin of a tree. A tree has exactly one root. Once we have the root, we can get to any nodes in the tree. Figure 3 illustrates a root node.
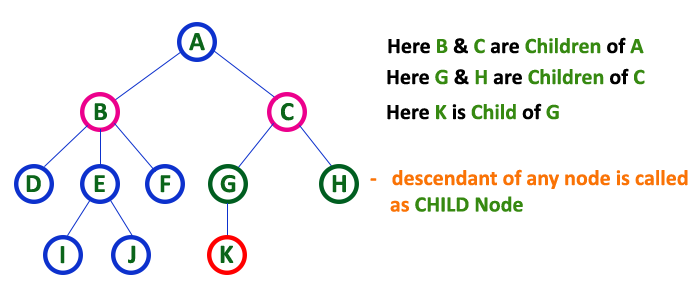
Child
A child is a node that is directly connected to another node when moving away from the root. In Figure 4, (B, C, D) are child nodes of A, (E, F) are child nodes of B, G is a child node of C, (H, I) are child nodes of D and (J, K) are child nodes of G.
Parent
A parent node is a node that has one or more child nodes. This is a converse notion of a child node. In Figure 5, A is a parent of (B, C, D), B is a parent of (E, F), C is a parent of G, D is a parent of (H, I) and G is a parent of (J, K).
A group of nodes with the same parent are called siblings. Figure 6 shows the siblings in the tree. The nodes with the same border color are siblings.
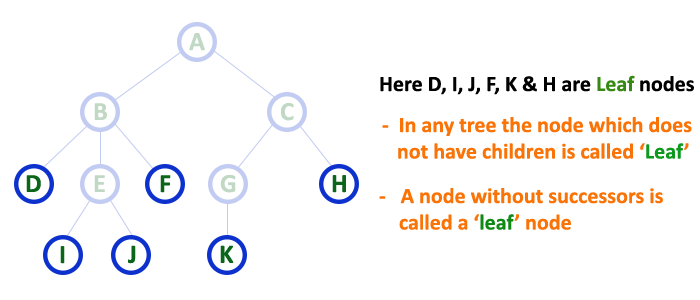
Leaf Node
A node with no children is called a leaf. A leaf node is also called an external node or a terminal node. We can not go further down the tree from the leaf node. In Figure 7, E, F, J, K, H and I are leaf nodes.
An internal node has at least one child. All nodes except leaf nodes are internal nodes of the tree. It is also called a branch node. Figure 8 shows the internal nodes of the tree.
Edge
An edge is a connection between one node and another. In a tree, parent and child are connected by an edge.
Descendant
A descendant node of a node is any node in the path from that node to the leaf node (including the leaf node). The immediate descendant of a node is the “child” node. In figure 10, the descendant nodes of node C are G, J and K
Ancestor
An ancestor node of a node is any node in the path from that node to the root node (including the root node). In figure 10, the ancestor nodes of node J are G, C and A.
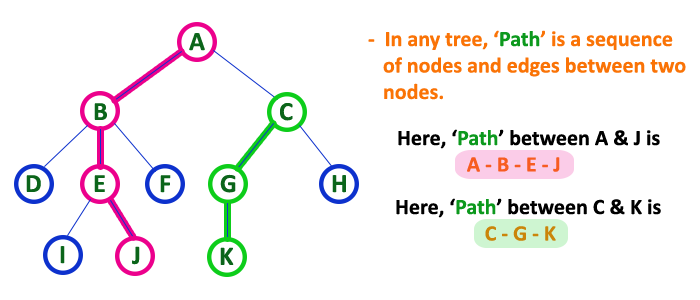
Path
The sequence of nodes and edges connecting a node and its descendants is called a path. In Figure 11, the path between A and E is A-B-E and the path between C and J is C-G-J
A degree of a node is the number of children. Since leaf node doesn’t have children, its degree is 0. The degree of a node can be any whole number from 0 to N. Figure 12 shows nodes with the corresponding degree.
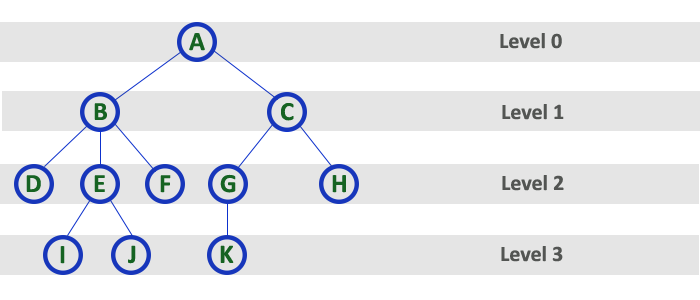
A level of a particular node is the number of edges between the node and a root + 1. The level always starts with 1 i.e. the level of a root is 1. The children of the root have level 2. The children of a level 2 node have level 3 and so on. Figure 13 illustrates this.
The height of a node is the number of edges on the longest path between that node and a leaf. The height of a leaf node is 0 and the root has the largest height. The height of the root node is called the Height of Tree. In Figure 14, the height of the tree is 3.
The depth of a node is the number of edges between the node and the root of the tree. The depth of the tree is 0. The depth of the tree is the depth of a leaf node on the longest path. In Figure 15, the depth of the tree is 3.
Subtrees
A node and all its descendants form a subtree. The subtree of a root node is the tree itself. Figure 16 shows some of the subtrees of the tree.
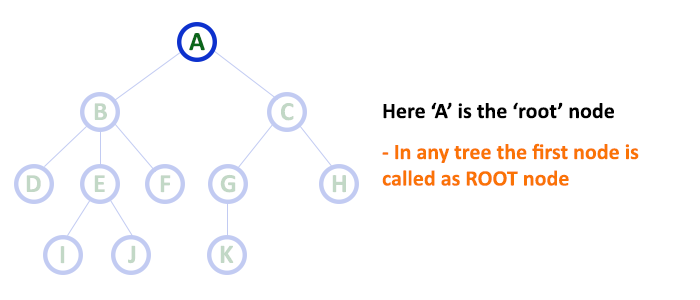
In a tree data structure, the first node is called as Root Node. Every tree must have a root node. We can say that the root node is the origin of the tree data structure. In any tree, there must be only one root node. We never have multiple root nodes in a tree.
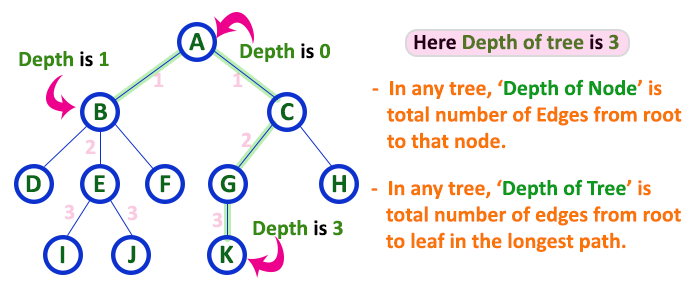
In a tree data structure, the total number of egdes from root node to a particular node is called as DEPTH of that Node. In a tree, the total number of edges from root node to a leaf node in the longest path is said to be Depth of the tree. In simple words, the highest depth of any leaf node in a tree is said to be depth of that tree. In a tree, depth of the root node is ‘0’.
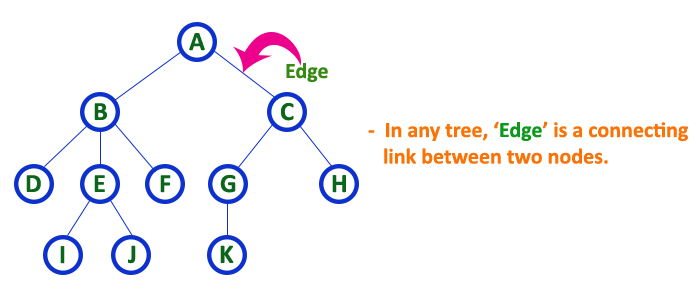
In a tree data structure, the connecting link between any two nodes is called as EDGE. In a tree with ‘N’ number of nodes there will be a maximum of ‘N-1’ number of edges.
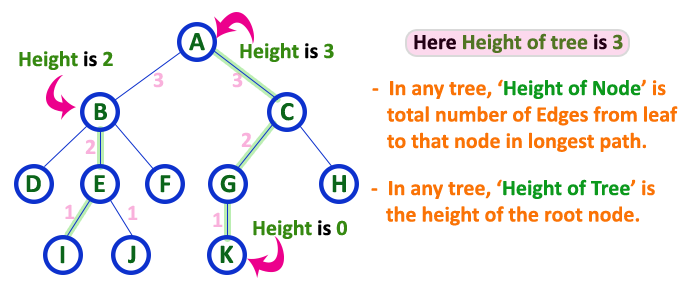
In a tree data structure, the total number of edges from leaf node to a particular node in the longest path is called as HEIGHT of that Node. In a tree, height of the root node is said to be height of the tree. In a tree, height of all leaf nodes is ‘0’.
Sub Tree
In a tree data structure, each child from a node forms a subtree recursively. Every child node will form a subtree on its parent node.
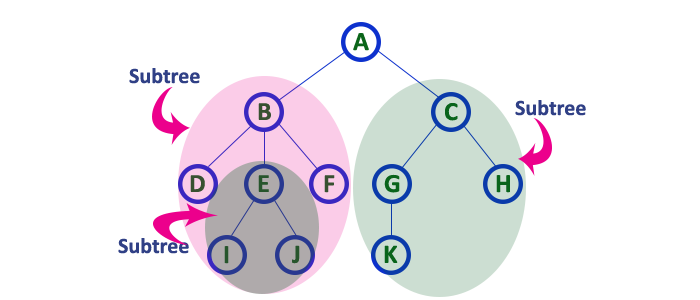
In a tree data structure, the sequence of Nodes and Edges from one node to another node is called as PATH between that two Nodes. Length of a Path is total number of nodes in that path. In below example the path A — B — E — J has length 4.
Applications of tree data structure
There are so many applications of trees. Most popular applications are listed below.
Implementing BSTs
From now on, we will assume that BSTs only store key values, not
associated data.
We will also assume that null is not a valid key value (i.e., if someone
tries to insert or lookup a null value, that should cause an exception).
In general, to determine whether a given value is in the BST,
we will start at the root of the tree and determine whether
the value we are looking for:
The code for the lookup method uses an auxiliary, recursive method with
the same name (i.e., the lookup method is overloaded):
and searching for 12:
What if we search for 15:
In general, we’d like to know how much time is required for lookup as a
function of the number of values stored in the tree.
In other words, what is the relationship between the number of nodes in a
BST and the height of the tree?
This depends on the «shape» of the tree.
In the worst case, all nodes have just one child, and the tree is essentially
a linked list.
For example:
50
/
10
15
30
/
20
In the best case, all nodes have 2 children, and all leaves are at the
same depth; for example:
This tree has 7 nodes, and height = 3.
In general, a tree like this (a «full» tree) will have height
approximately log2(N), where N is the number of nodes in the tree.
The value log2(N) is (roughly) the number of times you can divide
N by two, before you get to zero.
For example:
7/2 = 3 // divide by 2 once
3/2 = 1 // divide by 2 a second time
1/2 = 0 // divide by 2 a third time, the result is zero so quit
The reason we use log2. (rather than say log3) is
because every non-leaf node in a full BST has two children.
The number of nodes in each of the root’s subtrees is (approximately) 1/2 of
the nodes in the whole tree, so the length of a path from the root to a leaf
will be the same as the number of times we can divide N (the total number
of nodes) by 2.
However, when we use big-O notation, we just say that the height of a full
tree with N nodes is O(log N) — we drop the «2» subscript, because
log2(N) is proportional to logk(N) for any constant k;
i.e., for any constants B and k, and any value N:
To summarize:
The worst-case time required to do a lookup in a BST is O(height of tree).
In the worst case (a «linear» tree), this is O(N), where N is the
number of nodes in the tree.
In the best case (a «full» tree), this is O(log N).
Where should a new item go in a BST?
The answer is easy: it needs to go where you would have found it using lookup!
If you don’t put it there then you won’t find it later.
The code for insert is given below.
Note that:
As you would expect, deleting an item involves a search to locate the node
that contains the value to be deleted.
Here is an outline of the code for the delete method.
There are several things to note about this code:
If the search for the node containing the value to be deleted succeeds,
there are three cases to deal with:
Here’s what happens when the node containing the value 15 is removed
from the example BST:
When the node to delete has one child, we can simply replace that node with
its child by returning a pointer to that child.
As an example, let’s delete 16 from the BST just formed:
Here’s the code for delete, handling the two cases we’ve discussed so far
(the new code is shown in red):
The hard case is when the node to delete has two children.
We’ll call the node to delete n.
We can’t replace node n with one of its children, because what would
we do with the other child?
Instead, we will replace node n with another node, x, lower down in the tree,
then (recursively) delete node x.
The question is what node can we use to replace node n?
We have to choose that node so that the tree is still a BST; i.e.,
so that all of the values in n’s left subtree are less than the value
in n, and all of the values in n’s right subtree are greater than
the value in n.
There are two possibilities that work:
the node in the left subtree with the largest value, or
the node in the right subtree with the smallest value.
We’ll arbitrarily decide to use the node in the right subtree (with the
smallest value).
Below is a slightly different example BST;
let’s see what happens when we delete 13 from that tree.
Write the auxiliary method smallestNode used by the delete method
given above.
The header for smallestNode is:
In a tree data structure, the node which is descendant of any node is called as CHILD Node. In simple words, the node which has a link from its parent node is called as child node. In a tree, any parent node can have any number of child nodes. In a tree, all the nodes except root are child nodes.
In a tree data structure, the node which does not have a child is called as LEAF Node. In simple words, a leaf is a node with no child.
In a tree data structure, the leaf nodes are also called as External Nodes. External node is also a node with no child. In a tree,
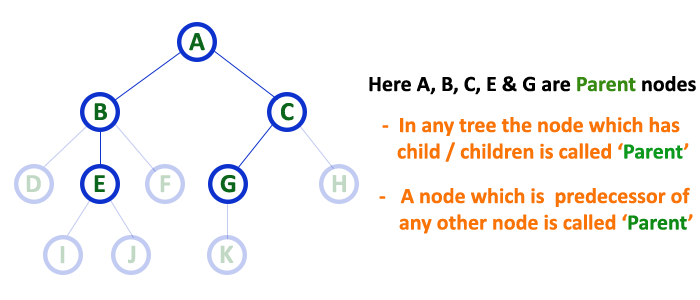
In a tree data structure, the node which is a predecessor of any node is called as PARENT NODE. In simple words, the node which has a branch from it to any other node is called a parent node. Parent node can also be defined as «The node which has child / children».
")




")