
Главная | Случайная страница | Контакты
Non-semantic grouping is used in all branches of applied linguistics in the alphabetical organization,inverted andpart of sp,by length,by frequancy
Most of the English lexicon is constituted by word which have several morphemes. (75 % engl. Words – polymorphemic words).
In ME most English vocabulary arises grows by making new lexemes out of old one, by adding an affixation to previously existing forms altering their words class and meaning by combining the existing words (basis) to produce compounds: derivatives, derived words (friendly – unfriendly, teapot, bag bone).
The contribution of word formation to the grows and development of English lexicons is second to none, although a great deal belong to borrowing and semantic derivation.
1. A complex word structure – the result of different word-formation process (illegal, discouraging, uninteresting)
2. A complex word structure may be connected with borrowing and further identification of certain morpheme in the system of language recipient.
Moreover similar international structure may be the result of different word formation process. E.g. discouraging – discourage + ing; uninteresting – un + interesting – morphologically(structurally) they are the same.
The morphemic analyses and derived analyses they are differ in the aims and basic elements.
To eye – monomorphic (root word)
It’s a derived word.
A morpheme – the smallest meaningful language unit.
Morphemes may be classified:
1. from the semantic point of view.
ü non-root or affixational morphemes include inflectional morphemes or inflections and affixational morphemes or affixes. Roots and affixes make two distinct classes of morphemes due to the different roles they play in word-structure.
Roots and affixational morphemes are generally easily distinguished and the difference between them is clearly felt as, e.g., in the words helpless, handy, blackness, Londoner, refill, etc.: the root-morphemes help-, hand-, black-, London-, -fill are understood as the lexical centres of the words, as the basic constituent part of a word without which the word is inconceivable.
2. Structurally morphemes fall into three types:
ü A free morpheme is defined as one that coincides with the stem or a word-form. A great many root-morphemes are free morphemes, for example, the root-morpheme friend — of the noun friendship is naturally qualified as a free morpheme because it coincides with one of the forms of the noun friend.CAN USE SEPARATEBLY
ü A bound morpheme occurs only as a constituent part of a word. Affixes are, naturally, bound morphemes, for they always make part of a word, e.g. the suffixes -ness, -ship, -ise (-ize), etc., the prefixes un-,dis-, de-, etc. (e.g. readiness, comradeship, to activise; unnatural, to displease, to decipher).
Many root-morphemes also belong to the class of bound morphemes which always occur in morphemic sequences, i.e. in combinations with ‘ roots or affixes. All unique roots and pseudo-roots are-bound morphemes. Such are the root-morphemes theor- in theory, theoretical, etc., barbar- in barbarism, barbarian, etc., -ceive in conceive, perceive, etc.
Semi-bound (semi-free) morpheme are morphemes that can function in a morphemic sequence both as an affix and as a free morpheme. For example, the morpheme well and half on the one hand occur as free morphemes that coincide with the stem and the word-form in utterances like sleep well, half an hour,” on the other hand they occur as bound morphemes in words like well-known, half-eaten, half-done. Speaking of word-structure on the morphemic level two groups of morphemes should be specially mentioned.
To the first group belong morphemes of Greek and Latin origin often called combining forms, e.g. telephone, telegraph, phonoscope, microscope, etc. The morphemes tele-, graph-, scope-, micro-, phone- are characterised by a definite lexical meaning and peculiar stylistic reference: tele- means ‘far’, graph- means ‘writing’, scope — ’seeing’, micro- implies smallness, phone- means ’sound.’ Comparing words with tele- as their first constituent, such as telegraph, telephone, telegram one may conclude that tele- is a prefix and graph-, phone-, gram- are root-morphemes. On the other hand, words like phonograph, seismograph, autograph may create the impression that the second morpheme graph is a suffix and the first — a root-morpheme. These morphemes are all bound root-morphemes of a special kind and such words belong to words made up of bound roots. The fact that these morphemes do not possess the part-of-speech meaning typical of affixational morphemes evidences their status as roots.
The second group embraces morphemes occupying a kind of intermediate position, morphemes that are changing their class membership.
According to the number of morphemes words are classified into monomorphic and polymorphic.
Monomorphiс or root-words consist of only one root-morpheme, e.g. small, dog, make, give, etc.ИХ БОЛЬШЕ
Pоlуmоrphiс words according to the number of root-morphemes are classified into two subgroups:
1) polyradical words, i.e. words which consist of two or more roots.
Polyradical words fall into two types:
ü polyradical proper words which consist of two or more roots with no affixational morphemes, e.g. book-stand, eye-ball, lamp-shade, etc. and
ü words which contain at least two roots and one or more affixational morphemes, e.g. safety-pin, wedding-pie, class- consciousness, light-mindedness, pen-holder, etc.
2. Monoradical words fall into two subtypes:
ü radical-suffixal words, i.e. words that consist of one root-morpheme and one or more suffixal morphemes, e.g. acceptable, acceptability, blackish, etc.;
ü radical-prefixal words, i.e. words that consist of one root-morpheme and a prefixal morpheme, e.g. outdo, rearrange, unbutton, etc. and
ü prefixo-radical-suffixal, i.e. words which consist of one root, a prefixal and suffixal morphemes, e.g. disagreeable, misinterpretation, etc.
Three types of morphemic segmentability of words are distinguished: complete, conditional and defective.
Complete segmentability is characteristic of a great many words the morphemic structure of which is transparent enough, as their individual morphemes clearly stand out within the word lending themselves easily to isolation.Teacher
Conditional morphemic segmentability characterises words whose segmentation into the constituent morphemes is doubtful for semantic reasons. The morphemes making up words of conditional segmentability thus differ from morphemes making up words of complete segmentability in that the former do not rise to the full status of morphemes for semantic reasons and that is why a special term is applied to them in linguistic literature: such morphemes are called pseudo-morphemes or quasi-morphemes.
Defective(Hamlet) morphemic segmentability is the property of words whose component morphemes seldom or never recur in other words. One of the component morphemes is a unique morpheme in the sense that it does not, as a rule, recur in a different linguistic environment. A unique morpheme is isolated and understood as meaningful because the constituent morphemes display a more or less clear denotational meaning. The morphemic analysis of words like cranberry, gooseberry, strawberry shows that they also possess defective morphemic segmentability: the morphemes cran-, goose-, straw- are unique morphemes.
Morphemic analyses – the aim is to state the number and type of morphemes the word possess.
The procedure generally employed for the purposes of segmenting words into the constituent morphemes is the method of Immediate and Ultimate Constituents.=BYNARY PRINCIPL This method is based on a binary principle, i.e. each stage of the procedure involves two components the word immediately breaks into. At each stage these two components are referred to as the Immediate Constituents (ICs). Each IC at the next stage of analysis is in turn broken into two smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes. In terms of the method employed these are referred to as the Ultimate Constituents (UCs). For example the noun friendliness is first segmented into the IC friendly recurring in the adjectives friendly-looking and friendly and the -ness found in a countless number of nouns, such as happiness, darkness, unselfishness, etc. The IC -ness is at the same time a UC of the noun, as it cannot be broken into any smaller elements possessing both sound-form and meaning. The IC friendly is next broken into the ICs friend- and -ly recurring in friendship, unfriendly, etc. on the one hand, and wifely, brotherly, etc., on the other. Needless to say that the ICs friend- and -ly are both UCs of the word under analysis.
The morphemic analysis according to the IC and UC may be carried out on the basis of two principles: the so-called root principle and the affix principle. According to the affix principle the segmentation of the word into its constituent morphemes is based on the identification of an affixational morpheme within a set of words; for example, the identification of the suffixational morpheme -less leads to the segmentation of words like useless, hopeless, merciless, etc., into the suffixational morpheme -less and the root-morphemes within a word-cluster; the identification of the root-morpheme agree- in the words agreeable, agreement, disagree makes it possible to split these words into the root -agree- and the affixational morphemes -able, -ment, dis-. As a rule, the application of one of these
11. Derivational analyses.
The nature, type and arrangement of the ICs of the word is known as its derivative structure. According to the derivative structure all words fall into two big classes: simple, non-derived words and complexes or derivatives. Simplexes are words which derivationally cannot’ be segmented into ICs. Derivatives are words which depend on some other simpler lexical items that motivate them structurally and semantically, i.e. the meaning and the structure of the derivative is understood through the comparison with the meaning and the structure of the source word.
The basic elementary units of the derivative structure of words are: derivational bases, derivational affixes and derivational patterns and degree
Derivational base: is defined as the constituent to which a rule of word-formation is applied. Structurally derivational bases fall into three classes:
1) bases that coincide with morphological stems of different degrees of complexity, e.g. duti ful, dutiful ly; day-dream, to day-dream, daydream er.
Derivationally the stems may be:
ü simple, which consist of only one, semantically non motivated constituent (pocket, motion, retain, horrible).
ü derived stems are semantically and structurally motivated, and are the results of the application of word-formation rules (girlish-girlishness)
ü compound stems are always binary and semantically motivated (weekend,match-box, letter-writer)
2) bases that coincide with word-form(gerund?participle); e.g. paper- bound, un smiling, un known. This class of bases is confined to verbal word-forms,phrases
blue-eyed, long-fingered, old-fashioned, do-gooder, etc.
Derivational affixes: Derivational affixes are ICs of numerous derivatives in all parts of speech. Derivational affixes possess two basic functions: 1) that of stem-building and 2) that of word-building. In most cases derivational affixes perform both functions simultaneously. It is true that the part-of-speech meaning is proper in different degrees to the derivational suffixes and prefixes. It stands out clearly in derivational suffixes but it is less evident in prefixes; some prefixes lack it altogether. Prefixes like en-, un-, de-, out-, be-, unmistakably possess the part-of-speech meaning and function as verb classifiers. The prefix over- evidently lacks the part-of-speech meaning and is freely used both for verbs and adjectives, the same may be said about non-, pre-, post-.
Derivational patterns: A derivational pattern is a regular meaningful arrangement, a structure that imposes rigid rules on the order and the nature of the derivational bases and affixes that may be brought together.
There are two types of DPs — structural that specify base classes and individual affixes, and structural-semantic that specify semantic peculiarities of bases and the individual meaning of the affix. DPs of different levels of generalisation signal: 1) the class of source unit that motivates the derivative and the direction of motivation between different classes of words; 2) the part of speech of the derivative; 3) the lexical sets and semantic features of derivatives. Degree
12. affixation-formation of new word by adding derivational af. To derivational bases. According to the number of words they can create af. Can be devided into PRODUCTIVE(un-,re-,er-,-ish)& NON-PRODUCTIVE(demi-,-ard,-hoood)
-by participation in word formation:ACTIVE&DEAD(for-,-d)
-by functional characteristic:CONVERTIVE(horse-unhorse)&NON-CONVERTIVE(pressedint-ex-pres.)
-by number of consepts:MONOSEMANT(-al)&POLISEMANT(ist)
Af. Can also be homonimon(al,an,am).
Главная | Случайная страница | Контакты
Classification of morphemes
Morphemes may be classified from the semantic and structural points of view.
Semantically morphemes fall into two classes: root-morphemes and non-rootmorphemes.
The root-morpheme is the lexical nucleus of a word. It has its individual lexical meaning and all other types of meaning proper to a morpheme except the part-of-speech meaning. The root-morpheme is isolated as the morpheme common to a set of words making up a word-cluster. E.g.: to read, read er, read ing.
Non-root morphemes include inflectional morphemes or inflections and affixational morphemes or affixes.
Inflections carry only grammatical meaning and are used to form word-forms. They are the object of morphology.
Affixes possess a part-of-speech meaning and a generalized lexical meaning and are used for building word-stems and word-formation. The stem is the part of a word that remains unchanged throughout its paradigm. Lexicology is concerned only withaffixational morphemes.
By the position within the word-structure affixes are subdivided into prefixes, suffixes and infixes.
A prefix precedes the root-morpheme; e.g.: dis charge.
An infix is inside the root-morpheme; e.g.: sta n d as compared to stood.
Structurally morphemes fall into three types: free morphemes, bound morphemes and semi-free or semi-bound morphemes.
A free morpheme is defined as the one that coincides with the stem of a word-form. Generally root-morphemes are free morphemes; e.g.: read er, friend ship, ship wreck.
A bound morpheme occurs only as a constituent part of a word. All affixes and unique and pseudo-roots are bound morphemes; e.g.: good ness, dis charge, friend ship, theor y, de ceive.
Semi-free or semi-bound morphemes can function in a morphemic sequence both as an affix and as a free morpheme. E.g.: the morphemes well and half occur as free morphemes that coincide with the stem and the word-form in utterances like sleep well, half an hour. But they occur as bound morphemes in words like well-known, half-done.
There are two more types of morphemes: combining forms and semi-suffixes.
Bound root-morphemes of Latin and Greek origin are called combining forms. E.g.: tele phone, tele graph and micro phone, photo graph.
A semi-suffix is termed as a word-building element formally coinciding with the stem or word-form of a free separate word but acting as an affix. E.g.: cab man, bar- happy.
Segmentable words can allow of the analysis of their word-structure on the morphemic level.
The operation of breaking a segmentable word into the constituent morphemes is referred to as morphological or morphemic analysis, or the analysis of word-structure on the morphemic level.
The morphemic analysis is aimed at splitting a segmentable word into its constituent morphemes and determining their number, types and arrangement.
The procedure employed for segmenting words into constituent morphemes is the method of Immediate (IC s) and Ultimate Constituents (UC s). This method is based on a binary principle. Each stage of the procedure involves two components into which the word immediately breaks. At each stage these two components are referred to as the ICs. Each IC at the next stage of analysis is in turn broken into two smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes which are referred to as the UCs.
The analysis of the morphemic composition of words defines the ultimate meaningful constituents, their number, types, sequence and arrangement within the word-structure.
Главная | Случайная страница | Контакты
2. Types of meaning in morphemes
3. Morphemic types of words and major ways of word formation
4. Morphemic analysis
7. Basic criteria of semantic derivation in conversion
4.1. Morphemes. Viewed structurally words appear to be divisible into smaller units which are called morphemes. Morphemes do not occur as free forms but only as constituents of words. The morpheme is the smallest meaningful unit of form. Morphemes cannot be segmented into smaller units without losing their constitutive essence, i.e. association of a certain meaning with a certain sound pattern. Morphemes can have different phonetic shapes, e.g. in such words as ‘please, pleasure, pleasant’ the same morpheme ‘pleas-‘ has different phonetic shapes and these various representations of the morpheme are called allomorphs, or morphemic variants.
Structurally morphemes fall into three types: 1) free morphemes; 2) bound morphemes; 3) semi-bound, or semi-free, morphemes.
Free morphemes are those that coincide with the stem or a word-form. For example, the root-morpheme youth- of the adjective youthful is a free morpheme as it coincides with one of the forms of the word youth.
A bound morpheme occurs only as a constituent part of a word. Affixes are bound morphemes for they always make part of a word, e.g. the suffixes –ment, -ness in the words government, kindness, or the prefixes un-, il- in the words unreal, illegal.
Some root morphemes also belong to the class of bound morphemes. They are as a rule roots which can be found in a small number of words such as goose- in gooseberry or –ceive in conceive, or for example, the word telephone consists of two bound roots of Greek origin – tele- and –phone.
Semi-bound morphemes can function in a morphemic sequence both as an affix and as a free morpheme, e.g. the morphemes well, half, proof are free morphemes coinciding with the stem and the word-form in the word utterances to sing well, half a loaf, the proof of the pudding, on the other hand they occur as bound morphemes in the words well-educated, half-known, waterproof.
4.2.Types of meaning in morphemes. Depending on the semantic class morphemes belong to, different types of meanings can be singled out in morphemes. Root morphemes possess lexical, differential and distributional types of meaning. Affixational morphemes have lexical, part-of-speech, differential and distributional types of meaning. Both roots and affixes are devoid of grammatical meaning.
Lexical meaning. Root morphemes have an individual lexical meaning and the same as in words it may be regarded as consisting of denotational and connotational components. The connotational component of meaning may be found not only in root-morphemes but in affixational morphemes as well. For example, endearing and diminutive suffixes bear a heavy emotive charge: -ette in kitchenette, leaflette, -ie in dearie, girlie, -ling in duckling, wolfling etc. the affixational morphemes with the same denotational meaning of similarity may differ only by the denotational component, e.g. womanly, womanlike, womanish cf. Russian женственный, женский, бабий. Stylistic reference may also be found in both root and affixational morphemes, e.g. the suffixes –ine, -oid are bookish (chlorine, rhomboid).
Differential meaning is the semantic component that serves to distinguish one word from all others containing identical morphemes. In words consisting of two or more morphemes, one of the constituent morphemes always has a differential meaning, e.g. in the word bookshelf the morpheme –shelf serves to distinguish this word from other words containing the morpheme book-: bookcase, bookstall.
Distributional meaning is the meaning of the order and arrangement of morphemes making up the word. It is found in all words consisting of more than one morpheme, e.g. ring-finger is composed of two morphemes ring – and -finger, and this order of arrangement of the morphemes endows the word with the denotational meaning of the third finger on the left hand. If we change the order of arrangement of the constituent morphemes into finger-ring, the denotational meaning will be different, the word means ‘a ring to wear on a finger’.
Part-of-speech meaning is characteristic of affixational morphemes, as they serve indicatives of the part of speech to which the derivational word belongs, e.g. the affixational morpheme –ment (development) is used to form nouns, while the affixational morpheme –less (careless) forms adjectives.
4.3. Morphemic types of words and major ways of word formation. According to the number of morphemes words are classified into monomorphic and polymorphic ones. Monomorphic, or root-words, consist only of one root-morpheme (little, doll, baby, make).
Root words mostly belong to the original English stock or to earlier borrowings, such as house, room, book, work, port, street, pen. Modern English has been greatly enlarged by the type of word-building called conversion, e.g. to hand< a hand, to can< a can, to pale < pale (adj.), a go< to go etc.
Polymorphic words according to the number of root-morphemes are classified into a) monoradical, containing one root-morpheme and b) polyradical, consisting of two or more roots.
Monoradical words fall into:
1) radical-suffixal words, such as acceptable, acceptability;
2) radical-prefixal words, such as unbutton, reread;
3) prefixo-radical-suffixal words, such as disagreeable, misinterpretation.
Words which consist of a root and an affix (or several affixes) are called derived words, or derivatives, and are produced by the process of word-building known as affixation or derivation.
Derived words are numerous in the English language successfully competing with root words.
Polyradical words fall into:
1) polyradical words consisting of two or more roots with no affixational morphemes, such as bookstall, lampshade;
2) polyradical words containing at least two roots and one or more affixational morphemes, such as safety-pin, handwriting.
This wide-spread word structure is a compound word consisting of two or more stems, i.e. part of the word formed by a root and an affix /affixes. In English words roots and stems can often coincide, e.g. dining-room, bluebell, mother-in-law etc. words of this type are produced by the word-building process called composition.
Such words as ‘pram, flu, doc, M.P., H-bomb’ are called shortenings, contractions or curtailed words and are produced by the way of word-building called shortening, or contraction.
Root-words, derivatives, compounds and shortenings represent the main structural types of modern English words and conversion, derivation and composition are the most productive ways of word-building.
4.4. The procedure of morphemic analysis generally employed for the purpose of segmenting words into the constituent morphemes is called the method of Immediate and Ultimate Constituents.
This method is based on a binary principle, i.e. each stage of the procedure involves two components the word immediately breaks into. At each stage these two components are referred to as the Immediate Constituents (ICs). Each IC at the next stage of analysis is in its turn broken into smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further subdivision, i.e. morphemes. These morphemes are referred to as the Ultimate Constituents (UCs). For example, the noun friendliness is first segmented into the ICs 1) friendly- and 2) –ness. The IC –ness is at the same time a UC of the noun as it cannot be broken into any smaller elements possessing both sound-form and meaning. The IC friendly- is next broken into the ICs 1) friend- and 2) –ly. The ICs friend- and –ly are both UCs of the word under analysis.
4.5. Affixation. The process of affixation consists in coining a new word by adding an affix or several affixes to some root-morpheme.
From the etymological point of view affixes are classified into the same two large groups as words: native and borrowed.
Native suffixes (most frequent)
Noun-forming: -er; -ness; -ing; -dom; -hood; -ship; -th; -let;
Adjective-forming: -ful; -less; -y; -ish; -ly; -en; -some; -like;
Adverb-forming: -ly; -wise.
Prefixes: be-; mis-; un-; over.
Borrowed affixes are numerous in the English language, especially those of Latin and French origin.
Noun-forming: -ion; -tion;
Verb-forming: -ate; -ute; -ct; -d(e); dis-;
Adjective-forming: -able/-ible; -ate; -ant; -ent; -or; -al; -ar.
Prefixes: extra-; pre-; ultra-.
Noun-forming: -ance; -ence; -ment; -age; -ess; -ard; -ee;
Noun-forming: -ist; -ism;
Verb-forming: -ite (thatcherite, Israelite, vulcanite);
Prefixes: anti-; sym-/syn- (symmetrical, synthesis)/
We should bear in mind that affixes are not borrowed in the same way and for the same reasons as words. An affix of foreign origin is regarded as borrowed only after it has begun an independent and active life in the recipient language, i.e. it takes part in the word-making process. This can only happen when the total of words with this affix is so great in the recipient language that the native speakers do not realize its alien nature.
Affixes can also be classified into productive and non-productive. Productive are those which take part in deriving new words in this particular period of language development. The best way to identify productive affixes is to look for them among neologisms and nonce-words, i.e. words coined and used only for this particular occasion. The latter are usually formed in oral speech and reflect the most productive and progressive patterns in word-building. For example, in the phrase ‘I don’t like Sunday evenings. I feel so Mondayish’ the nonce-word ‘Mondayish’ is coined according to the productive pattern of word-building ‘noun+-ish=adjective’, and the suffix –ish proves to be productive.
Productivity must not be confused with frequency of occrurrence. There are quite a number of high-frequency affixes which are no longer used in word-formation at the present stage of development of the English language.
Some Productive Affixes:
Noun-forming: -er; -ing; -ness; -ism; -ist. –ance; -ation; -ee; -ism; -ist; -ance/ -ancy; -ry; -or; -ics;
Adjective-forming: -y; -ish; -ed; -able; -less; -ic;
Verb-forming: -ize/-ise; -ate; -ify;
Prefixes: un-; re-; dis-.
Some Non-Productive Affixes:
Noun-forming: -th; -hood; -ship;
Adjective-forming: -ly; -some; -en; -ous; -ful;
Valency of affixes and bases. Valency of affixes is their capability to be combined with certain bases, e.g. adjective forming suffixes are mostly attached to nominal bases: gold+-en=golden; meaning+-ful=meaningful; care+-less=careless etc. Some of them, such as the highly-productive suffix –able, can be combined with nominal and verbal bases alike: honorable, advisable.
The combining possibilities are important semantically because the meaning of the derivative depends not only on the morphemes of which it is composed but also on the combinations of bases and affixes that can be contrasted with it. For example, the difference in the suffixes –ity and –ism becomes clear when comparing them as combined with identical bases: formality – formalism, reality – realism.
4.6. Conversion is one of the most productive ways of modern English word-building. It is sometimes referred to as an affixless way of word-building or even affixless derivation, but there are other types of word-building in modern English when new words are formed without affixes, e.g. some compounds, contracted words, onomatopoeic words etc.
Conversion consists in making a new word from some already existing by changing the category of part of speech, the morphemic shape of the original word remaining unchanged. The new word has a new meaning which though can more or less easily be deduced from the original. It has also a new paradigm peculiar to its new category as a part of speech, e.g. to nurse, verb has a verbal paradigm (ending –s in the 3-d person singular, ending –ed in the past indefinite tense and in the past participle, suffix –ing in the present participle and gerund) while the noun ‘nurse’ from which the verb was formed has a different paradigm of that of a noun (grammatical suffix of plurality –s, -‘s in the possessive case and –s’ in the plural form of the possessive case).
The immense productivity of conversion in modern English word formation is due to its analytical structure, which facilitates the process of making words of one category of parts of speech from words of another. Besides, the simplicity of paradigms of English parts of speech also contributes to this type of word-building. Moreover, a great number of monosyllabic words is one more factor in favour of conversion, for such words are naturally more mobile and flexible than polysyllabic ones.
The high productivity of conversion finds its reflection in oral speech where numerous cases of converted words may be found not being registered by dictionaries, e.g. “If anybody oranges me again tonight, I’ll knock his face off”- says the annoyed hero of a story by O’Henry.
Among the main varieties of conversion are: 1) verbalization, e.g. to ape, to hand, to eye; 2) substantivation, e.g. a private<private adj.; 3) adjectivation, e.g. down, adj.< down, adv.; 4) adverbalization, e.g. home, adv.< home, noun.
The two parts of speech especially affected by conversion are nouns and verbs.
Verbs converted from nouns are called denominal verbs. If the noun refers to some object of reality the converted verb may denote:
1) action characteristic of the object: ape n. > to ape v. ‘imitate in a foolish way’;
2) instrumental use of the object: whip n. > to whip v. ‘strike with a whip’;
3) acquisition or addition of the object: fish n. > to fish v. ‘catch or try to catch fish’;
4) deprivation of the object: dust n. > to dust v. ‘remove dust’;
5) location: pocket n. > to pocket v. ‘put into one’s pocket’;
6) activity typical of the profession or occupation denoted by the noun: nurse n. > to nurse v. ‘ fulfill the duties of a nurse’ etc.
Nouns converted from verbs are called deverbal substantives. If the verb refers to an action, the converted noun may denote:
1) instance of the action: jump v. > jump n. ‘sudden spring from the ground’;
2) agent of the action: help v. > help n. ‘a person who helps’;
3) place of the action: drive v. > drive n. ‘a path or road along which one drives’;
4) result of the action: peel v. > peel n. ‘the outer skin of fruit or vegetables taken off’;
5) object of the action: let v. > let n. ‘a property available for rent’.
In case of polysemantic words one and the same member of a conversion pair may belong to several groups, e.g. the deverbal substantive ‘slide’ referring to the place of action means ‘a stretch of smooth ice or hard snow on which to slide’ and referring to the agent of the action, it means ‘a sliding machine part’.
Denominal verbs are the most numerous among conversion pairs, e.g. to hand, to back, to face, to eye, to mouth, to nose, to dog, to wolf, to monkey, to can, to coal, to stage, to screen, to room, to floor, to blackmail, to blacklist, to honeymoon etc.
Deverbal substantives are also frequent, e.g. a do (event, incident), a go (energy), a make, a run, a find, a catch, a cut, a walk, a worry, a show, a move etc.
From the diachronic point of view distinction should be made between homonymous word-pairs, which appeared as a result of the loss of inflections, and those formed by conversion, e.g. carian (v.), caru (n.) > care (v., n.); lufu (n.), lufian (v.) > love (v.,n.). a similar phenomenon is observed in the words borrowed from French, which in course of time lost their affixes and became identical in the process of assimilation, e.g. crier (v.), cri (n.) > cry (v., n.); eschequier (v.), eschec (n.) > check (v., n.).
The diachronic semantic analysis reveals that the semantic structure of the base may acquire a new meaning or several meanings under the influence of the meanings of the converted word. This semantic process is called reconversion, e.g. smoke (n.) – smoke (v.). the noun smoke acquired in 1715 the meaning of ‘the act of smoke coming out into the room instead of passing up the chimney’ under the influence of the meaning of the verb smoke ‘ to emit smoke as the result of imperfect draught or improper burning’, acquired by this verb in 1663.
4.7. Basic criteria of semantic derivation in conversion. There are several criteria of differentiating between the source and the derived word in a conversion pair:
1) the criterion of non-correspondence between the lexical meaning of the root-morpheme and the part-of-speech meaning of the stem of the two words in a conversion pair. For example, in the pair father (n.) – father (v.), the noun is the name for a being. The lexical meaning of the root-morpheme corresponds to the part-of-speech meaning of the stem. The verb ‘to father’ denotes a process, so the part-of-speech meaning of its stem does not correspond to the lexical meaning of the root which is of a substantive character. Thus verbs of this type possess a complex semantic structure, and the semantically more complex word is considered the derived member of the conversion pair.
2) the synonymity criterion is based on the comparison of a conversion pair with analogous synonymous word-pairs, e.g. comparing the conversion pair chat (v.) –chat (n.) with the synonymous pair of words to converse – conversation, it becomes obvious that the noun chat is the derived member as the semantic relations in the case of to chat – chat are similar to those between to converse – conversation. The drawback of this criterion is that it can be applied only to deverbal substantives (v.> n.).
3) the criterion of derivational relations shows to what base derivational suffixes are added, e.g. in the word cluster ‘hand (n.) – hand (v.) – handful – handy’ derivational suffixes are added to the nominal base, so it makes us possible to conclude that the verb to hand is the derived member in the conversion pair under analysis.
4) the criterion of semantic derivation is based on semantic relations within conversion pairs. Relations typical of denominal verbs prove that the verb is the derived member, while relations typical of deverbal substantives mark the contrary, e.g. the semantic relations between crowd (n.) – crowd (v.) are of an object and an action characteristic of it which makes it possible to conclude that the verb to crowd is the derived member.
5) the criterion of the frequency of occurrence testifies a lower frequency value to the derived member, e.g. according to M. West’s “A General Service List of English Words”, the frequency value of the verb ‘to answer’ is 63% while that of the noun ‘answer’ – 35%; thus the noun ‘answer’ is the derived member.
6) the transformational criterion is the change of a predicative syntagma into a nominal one, e.g. She loves nature> Her love of nature. This transformation is made by analogy with the transformation of ‘The committee elected him’ into ‘His election by the committee’, in which the word ‘election’ is a derived one. This analogy makes it possible to conclude that the noun ‘love’ is the derived member.
4.8. Composition is the type of word formation in which new words are produced by combining two or more Immediate Constituents (ICs), which are both derivational bases. The ICs of compound words represent bases of all three structural types: 1) bases that coincide with morphological stems; 2) bases that coincide with word-forms; 3) bases that coincide with word-groups. The bases built on stems may be of different degrees of complexity: 1) simple, e.g. week-end; 2) derived, e.g. letter-writer; 3) compound, e.g. aircraft-carrier.
The meaning of compound words is made up of two components; structural and lexical.
The structural meaning of compounds is formed on the base of the meaning of their distributional pattern and the meaning of their derivational pattern.
The distributional pattern of a compound is understood as the order and arrangement of the ICs that make up a compound word. A change in the order and arrangement of the same ICs signals the compound words of different lexical meanings, cf.: a fruit-market – market-fruit: a finger-ring – a ring-finger. In many cases a change in the order and arrangement may destroy the meaning.
The lexical meaning of compounds is formed on the base of the combined lexical meanings of their constituents. The semantic centre of the compound is the lexical meaning of the second component modified and restricted by the meaning of the first. The lexical meanings of both components are closely fused together to create a new semantic unit with a new meaning, which dominates the individual meanings of the bases and is characterized by some additional component not found in any of the bases, e.g. the lexical meaning of the compound ‘handbag’ is not essentially ‘a bag designed to be carried in the hand’ but ‘a woman’s small bag to carry everyday personal items’.
Classification of compounds.
According to the relations between the ICs compound words fall into two classes: 1) coordinative compounds and 2) subordinative compounds.
In coordinative compounds the two ICs are semantically equally important. There are three groups in coordinative compounds:
a) reduplicative compounds which are made up by the repetition of the same base, e.g. pooh-pooh, fifty-fifty;
b) compounds formed by joining the phonetically variated rhythmic twin forms, e.g. chit-chat, zig-zag, walkie-talkie, dilly-dally, riff-raff, ping-pong;
c) additive compounds which are built on stems of the independently functioning words of the same part of speech, e.g. actor-manager, queen-bee.
In subordinative compounds the components are neither structurally nor semantically equal in importance but are based on the domination of the head member which is as a rule the second IC, e.g. stone-deaf, age-long. The second IC preconditions the part-of-speech meaning of the whole compound.
According to the part of speech compounds represent, they fall into: 1) compound nouns, e.g. sunrise, housemaid; 2) compound adjectives, e.g. care-free, far-going; 3) compound pronouns, e.g. somebody, anybody; 4) compound adverbs, e.g. nowhere, inside; 5) compound verbs, e.g. to bypass, to mass-produce.
From the diachronic point of view many compound verbs of the present-day language are treated not as compounds proper but as polymorphic verbs of secondary derivation. They are called pseudo-compounds and are represented by two groups: a) verbs formed by means of conversion from the stems of compound nouns, e.g. to spotlight (>spotlight, n.); b) verbs formed by back-derivation from the stems of compound nouns, e.g. to babysit (>baby-sitter).
However synchronically compound verbs correspond to the definition of a compound as a word consisting of two free stems and functioning in the sentence as a separate lexical unit.
According to the means of composition compound words are classified into: 1) compounds composed without connecting elements, e.g. backache, school girl; 2) compounds composed with the help of a linking vowel or consonant, e.g. salesgirl, handicraft; 3) compounds composed with the help of linking elements represented by preposition or conjunction stems, e.g. son-in-law, pepper-and-salt.
According to the type of bases that form compounds two classes can be singled out: 1) compounds proper that are formed by joining together bases built on the stems or on the word-forms with or without a linking element, e.g. door-step, street-fighting; 2) derivational compounds that are formed by joining affixes to the bases built on the word-groups or by converting the bases built on the word-groups into other parts of speech, e.g. blue-eyed < (blue eyes) + -ed, a turnkey< (to turn key) + conversion. Thus derivational compounds fall into two groups: a) derivational compounds mainly formed with the help of suffixes –ed and –er applied to bases built on attributive phrases, e.g. doll-faced, left-hander; b) derivational compounds formed by conversion applied to bases built on three types of phrases – verbal-adverbial (a breakdown), verbal-nominal (a kill-joy) and attributive (a sweet-tooth).
However some linguists give a shorter structural classification of compounds, according to G.B. Antrushina, compounds are divided into: 1) neutral; 2) morphological and 3) syntactic (though the term is arbitrary).
In neutral compounds the process of composition is realized without any linking elements, by a mere juxtaposition of two stems. There are three subtypes of neutral compounds depending on the structure of their ICs: a) simple neutral compounds consisting of simple affixless stems, e.g. bedroom, bluebell; b) derivational compounds having affixes in their structure, e.g. absent-mindedness, luncher-out, goose-flesher (this type of composition is productive); c) contracted compounds having a shortened stem in their structure, e.g. TV-set, V-day, FBI-agent.
Morphological compounds are few in number. This type of composition is not productive. It is represented by words in which two compounding stems are combined by a linking vowel or consonant, e.g. Anglo-Saxon, handiwork, craftsmanship, spokesman, statesman, salesgirl.
In syntactic compounds one finds a feature of specifically English word-structure, these words are formed from segments of speech, preserving in their structure numerous traces of syntagmatic relations typical of speech, such as articles, prepositions, adverbs, e.g. lily-of-the-valley, Jack-of-all-trades, good-for-nothing, mother-in-law, sit-at-home, pick-me-up, forget-me-not, know-all, go-between, get-together, whodunit.
Speaking of the semantic aspect of compound words the degree of semantic cohesion of constituent parts must be taken into consideration. As it has already been mentioned, either both or only the second IC is semantically important, but at the same time the semantic meaning of the whole compound cannot be viewed upon as the sum total of the meanings of its ICs, even if we take for example such a compound as ‘a dancing hall’, the meaning of which seems quite transparent, but comparing it with a free word group ‘a dancing girl’, we cannot fail to notice that their meanings are not analogous, the former means ‘a hall to dance in’, while the latter – ‘a girl that is dancing’. So we can assume that there is a shift of meaning in the compound ‘a dancing hall’.
There are cases when one of the ICs (or both) has changed its meaning, e.g. blackboard (is not necessarily black, and may be made of various materials), blackbird (not all types of this bird are black), football (is neither a foot nor a ball, it is a game), lazybones (it is not the bones that are lazy but the man), chatterbox (is not a box but a person). So the meaning of the whole cannot be defined as the sum of meanings of the ICs. Still in these compounds the meaning of the whole is quite clear as the shift of meaning is based on metaphors which are rather transparent.
The thing is quite different with such compounds as ‘ladybird (an insect), tallboy (a piece of kitchen furniture), bluebottle (a fly), wallflower (a girl who is left without a partner at a dancing party) etc.’, as it is impossible to deduce the meaning of the whole from the meanings of their ICs. These compounds show an extreme case of semantic cohesion of their ICs, and the constituent meanings blend to produce entirely new meanings. Thus, the compounds the meaning of which can be deduced from the meanings of their ICs are called non-idiomatic, the compounds with a partial or full shift of meanings are called idiomatic.
1) the graphic criterion, though it may be sufficiently convincing, yet in many cases it cannot wholly be relied upon. The spelling of many compounds can vary even within the same book, one and the same compound may be written solidly (a schoolgirl) or separately (a school girl) or with a hyphen (a school-girl);
2) the semantic criterion seems more reliable, as it is based on the degree of semantic cohesion of the ICs, compounds possess the highest degree of this, e.g. a tallboy does not even denote a person, but a piece of furniture, a chest of drawers supported by a low stand – which is one concept, while the word-group ‘a tall boy’ conveys two concepts, those of a young male person and the height of this person. Yet, as it concerns phraseological units, they can also convey one concept showing a high degree of semantic cohesion of its constituents, so the semantic criterion is not fully reliable either;
3) the phonetic criterion can be applied to many compound nouns as they are characterized by a single stress, but it cannot be applied to compound adjectives possessing a two-stress phonetic pattern (cf. blackbird, tallboy – only the first constituent is stressed, blue-eyed, absent-minded – both ICs are stressed);
4) the morphological and syntactic criteria shows that in free word-group each of the constituents is independently open to grammatical changes typical of its own category as a part of speech, or other words can be inserted between the constituents of the word group, e.g. a tall boy – the tallest boys – a tall handsome boy, while compound words are not subjects to such changes.
All this makes it possible to conclude that in most cases several of the criteria can be helpful to distinguish between a free word-group and a compound.
Semi-affixes. There are some components in words that stand between roots and affixes in their characteristics. They occupy the second position in the word, being attached to a root morpheme, e.g. ‘-proof’: fireproof, waterproof, childproof, kissproof or ‘-man’: sportsman, statesman, fisherman, seaman, policeman, chairman etc. On the one hand, these second components bear all the features of a stem and preserve certain semantic associations with free forms ‘proof, man’. On the other hand, their meanings have become so generalized that they are approaching those of suffixes. The components ‘-proof’, ‘-man’ stand between a stem and an affix and are regarded by some linguists as semi-affixes. Some other examples 0f semi-affixes are: ‘-land’ (Ireland, Scotland, wonderland, fatherland), ‘-like’ (ladylike, businesslike, starlike, flowerlike), ‘-worthy (trustworthy, seaworthy, praiseworthy).
Thus on the level of morphemic analysis the linguist has to operate with two types of elementary units, namely full morphemes and pseudo-(quasi-)morphemes. It is only full morphemes that are genuine structural elements of the language system so that the linguist must primarily focus his attention on words of complete morphemic segmentability. On the other hand, a considerable percentage of words of conditional and
 1 Needless to say that the noun ham denoting ‘a smoked and salted upper part of a pig’s leg’ is irrelevant to the ham- in hamlet.
1 Needless to say that the noun ham denoting ‘a smoked and salted upper part of a pig’s leg’ is irrelevant to the ham- in hamlet.
defective segmentability signals a relatively complex character of the morphological system of the language in question, reveals the existence of various heterogeneous layers in its vocabulary.
§ 3. Classification of Morphemes
Morphemes may be classified:
a) from the semantic point of view,
b) from the structural point of view.
a) Semantically morphemes fall into two classes: root-morphemes and non-root or affixational morphemes. Roots and affixes make two distinct classes of morphemes due to the different roles they play in word-structure.
Roots and affixational morphemes are generally easily distinguished and the difference between them is clearly felt as, e.g., in the words helpless, handy, blackness, Londoner, refill, etc.: the root-morphemes help-, hand-, black-, London-, -fill are understood as the lexical centres of the words, as the basic constituent part of a word without which the word is inconceivable.
Non-root morphemes include inflectional morphemes or inflections and affixational morphemes or affixes. Inflections carry only grammatical meaning and are thus relevant only for the formation of word-forms, whereas affixes are relevant for building various types of stems — the part of a word that remains unchanged throughout its paradigm. Lexicology is concerned only with affixational morphemes.
b) Structurally morphemes fall into three types: free morphemes, bound morphemes, semi-free (semi- bound) morphemes.
A free morpheme is defined as one that coincides with the stem 2 or a word-form. A great many root-morphemes are free morphemes, for example, the root-morpheme friend — of the noun friendship is naturally qualified as a free morpheme because it coincides with one of the forms of the noun friend.
A bound morpheme occurs only as a constituent part of a word. Affixes are, naturally, bound morphemes, for they always make part of a word, e.g. the suffixes -ness, -ship, -ise (-ize), etc., the prefixes un-,
 1 See ‘Semasiology’, §§ 13-16, pp. 23-25. 2 See ‘Word-Structure’, § 8, p. 97.
1 See ‘Semasiology’, §§ 13-16, pp. 23-25. 2 See ‘Word-Structure’, § 8, p. 97.
dis-, de-, etc. (e.g. readiness, comradeship, to activise; unnatural, to displease, to decipher).
Many root-morphemes also belong to the class of bound morphemes which always occur in morphemic sequences, i.e. in combinations with ‘ roots or affixes. All unique roots and pseudo-roots are-bound morphemes. Such are the root-morphemes theor- in theory, theoretical, etc., barbar-in barbarism, barbarian, etc., -ceive in conceive, perceive, etc.
Semi-bound (semi-free) morphemes1 are morphemes that can function in a morphemic sequence both as an affix and as a free morpheme. For example, the morpheme well and half on the one hand occur as free morphemes that coincide with the stem and the word-form in utterances like sleep well, half an hour,” on the other hand they occur as bound morphemes in words like well-known, half-eaten, half-done.

Speaking of word-structure on the morphemic level two groups of morphemes should be specially mentioned.
To the first group belong morphemes of Greek and Latin origin often called combining forms, e.g. telephone, telegraph, phonoscope, microscope, etc. The morphemes tele-, graph-, scope-, micro-, phone- are characterised by a definite lexical meaning and peculiar stylistic reference: tele- means ‘far’, graph- means ‘writing’, scope — ’seeing’, micro- implies smallness, phone- means ’sound.’ Comparing words with tele- as their first constituent, such as telegraph, telephone, telegram one may conclude that tele- is a prefix and graph-, phone-, gram-are root-morphemes. On the other hand, words like phonograph, seismograph, autograph may create the impression that the second morpheme graph is a suffix and the first — a root-morpheme. This undoubtedly would lead to the absurd conclusion that words of this group contain no root-morpheme and are composed of a suffix and a prefix which runs counter to the fundamental principle of word-structure. Therefore, there is only one solution to this problem; these morphemes are all bound root-morphemes of a special kind and such words belong to words made up of bound roots. The fact that these morphemes do not possess the part-of-speech meaning typical of affixational morphemes evidences their status as roots.2
 1 The Russian term is относительно связанные (относительно свободные).
1 The Russian term is относительно связанные (относительно свободные).
2 See ‘Semasiology’, §§ 15, 16, p. 24, 25.
The second group embraces morphemes occupying a kind of intermediate position, morphemes that are changing their class membership.
§ 4. Procedure of Morphemic Analysis
The procedure generally employed for the purposes of segmenting words into the constituent morphemes is the method of Immediate and Ultimate Constituents. This method is based on a binary principle, i.e. each stage of the procedure involves two components the word immediately breaks into. At each stage these two components are referred to as the Immediate Constituents (ICs). Each IC at the next stage of analysis is in turn broken into two smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes. In terms of the method employed these are referred to as the Ultimate Constituents (UCs). For example the noun friendliness is first segmented into the IC friendly recurring in the adjectives friendly-looking and friendly and the -ness found in a countless number of nouns, such as happiness, darkness, unselfishness, etc. The IC -ness is at the same time a UC of the noun, as it cannot be broken into any smaller elements possessing both sound-form and meaning. The IC friendly is next broken into the ICs friend-and -ly recurring in friendship, unfriendly, etc. on the one hand, and wifely, brotherly, etc., on the other. Needless to say that the ICs friend-and -ly are both UCs of the word under analysis.
The procedure of segmenting a word into its Ultimate Constituent morphemes, may be conveniently presented with the help of a box-like diagram
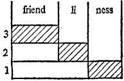
In the diagram showing the segmentation of the noun friendliness the lower layer contains the ICs resulting from the first cut, the upper one those from the second, the shaded boxes representing the ICs which are at the same time the UCs of the noun.
The morphemic analysis according to the IC and UC may be carried out on the basis of two principles: the so-called root principle and the affix principle. According to the affix principle the segmentation of the word into its constituent morphemes is based on the identification of an affixational morpheme within a set of words; for example, the identification of the suffixational morpheme -less leads to the segmentation of words like useless, hopeless, merciless, etc., into the suffixational morpheme -less and the root-morphemes within a word-cluster; the identification of the root-morpheme agree- in the words agreeable, agreement, disagree makes it possible to split these words into the root -agree- and the affixational morphemes -able, -ment, dis-. As a rule, the application of one of these principles is sufficient for the morphemic segmentation of words.
§ 5. Morphemic Types of Words
According to the number of morphemes words are classified into monomorphic
and polymorphic. Monomorphiс or root-words consist of only one root-morpheme, e.g. small, dog, make, give, etc. All pоlуmоrphiс words according to the number of root-morphemes are classified into two subgroups: monoradical (or one-root words) and polyradical words, i.e. words which consist of two or more roots. Monoradical words fall into two subtypes: 1) radical-suffixal words, i.e. words that consist of one root-morpheme and one or more suffixal morphemes, e.g. acceptable, acceptability, blackish, etc.; 2)radical-prefixal words, i.e. words that consist of one root-morpheme and a prefixal morpheme, e.g. outdo, rearrange, unbutton, etc. and 3) prefixo-radical-suffixal, i.e. words which consist of one root, a prefixal and suffixal morphemes, e.g. disagreeable, misinterpretation, etc.
Polyradical words fall into two types: 1) polyradical words which consist of two or more roots with no affixational morphemes, e.g. book-stand, eye-ball, lamp-shade, etc. and 2) words which contain at least two roots and one or more affixational morphemes, e.g. safety-pin, wedding-pie, class-consciousness, light-mindedness, pen-holder, etc.
§ 6. Derivative Structure
The analysis of the morphemic composition of words defines the ultimate meaningful constituents (UCs), their typical sequence and arrangement, but it does not reveal the hierarchy of morphemes making up the word, neither does it reveal the way a word is constructed, nor how a new word of similar structure should be understood. The morphemic analysis does not aim at finding out the nature and arrangement of ICs which underlie the structural and the semantic type of the word, e.g. words unmanly and discouragement morphemically are referred to the same type as both are segmented into three UCs representing one root, one prefixational and one suffixational morpheme. However the arrangement and the nature
of ICs and hence the relationship of morphemes in these words is different — in unmanly the prefixational morpheme makes one of the ICs, the other IC is represented by a sequence of the root and the suffixational morpheme and thus the meaning of the word is derived from the relations between the ICs un- and manly- (‘not manly’), whereas discouragement rests on the relations of the IC discourage- made up by the combination of the. prefixational and the root-morphemes and the suffixational morpheme -ment for its second IC (’smth that discourages’). Hence we may infer that these three-morpheme words should be referred to different derivational types: unmanly to a prefixational and discouragement to a suffixational derivative.
The nature, type and arrangement of the ICs of the word is known as its derivative structure. Though the derivative structure of the word is closely connected with its morphemic or morphological structure and often coincides with it, it differs from it in principle.
§ 7. Derivative Relations
According to the derivative structure all words fall into two big classes: simplexes or simple, non-derived words and complexes or derivatives. Simplexes are words which derivationally cannot’ be segmented into ICs. The morphological stem of simple words, i.e. the part of the word which takes on the system of grammatical inflections is semantically non-motivated l and independent of other words, e.g. hand, come, blue, etc. Morphemically it may be monomorphic in which case its stem coincides with the free root-morpheme as in, e.g., hand, come, blue, etc. or polymorphic in which case it is a sequence of bound morphemes as in, e.g., anxious, theory, public, etc.
The basic elementary units of the derivative structure of words are: derivational bases, derivational affixes and derivational patterns which differ from the units of the morphemic structure of words (different types of morphemes). The relations between words with a common root but of different derivative structure are known as derivative relations. The derivative and derivative relations make the subject of study at the derivational level of analysis; it aims at establishing correlations between different types of words, the structural and semantic patterns
 1 See ‘Semasiology’, § 17, p. 25. 96
1 See ‘Semasiology’, § 17, p. 25. 96
words are built on, the study also enables one to understand how new words appear in the language.
A derivational base as a functional unit is defined as the constituent to which a rule of word-formation is applied. It is the part of the word which establishes connection with the lexical unit that motivates the derivative and determines its individual lexical meaning describing the difference between words in one and the same derivative set, for example the individual lexical meaning of words like singer, rebuilder, whitewasher, etc. which all denote active doers of action, is signalled by the lexical meaning of the derivational bases sing-, rebuild-, whitewash- which establish connection with the motivating source verb.

Мы поможем в написании ваших работ!
")




")