

- Example
- Syntax
- Example
- XML – Процессоры
- XML – Обзор
- DOM — NamedNodeMap Object
- Является ли XML языком программирования?
- XML — Attributes
- DOM — ProcessingInstruction Object
- Empty Element
- XML — Tree Structure
- Содержимое как строка XML
- Element Attribute Rules
- Syntax
- Example
- DOM — DOMException Object
- Create New CDATA Section Node
- Syntax
- Example
- Execution
- Создать новый текстовый узел
- Пройдя через узлы
- Namespace Declaration
- Content as XML file
- node.xml
- Execution
- Ошибки в XML-документе
- XML – разделы CDATA
- Text Editors
- XML — Namespaces
- DOM — DocumentType Object
- XML DOM — Loading
- DOM — Attribute Object
- DOM – объект XMLHttpRequest
- Теги и элементы
- Синтаксические правила для тегов и элементов
- Получить значение узла
- Syntax
- Content as XML string
- Execution
- XML DOM — Navigation
- XML — Character Entities
- XML — Editors
- DOM – DocumentType Object
- XML DOM – навигация
- XML Usage
- Open Source XML Editors
- GetElementsByTagName ()
- Syntax
- Example
- XML — Viewers
- XML – DOM
- ReplaceChild()
- Syntax
- Example
- Execution
- DOM Parser API
- 1.1. Import dom Parser Packages
- 1.2. Create DocumentBuilder
- 1.3. Create Document object from XML file
- 1.4. Validate Document Structure
- 1.5. Extract the Root Element
- 1.6. Examine Attributes
- 1.7. Examine Child-Elements
- Syntax
- Example
- Types
- System Identifiers
- Public Identifiers
- XML — DTDs
- Examples
- Retrieve specific information of a resource file
- Execution
- Retrieve header infomation of a resource file
- Execution
- XML Document Example
- XML DOM — Add Node
- XML-редакторы с открытым исходным кодом
- XML DOM – Создать узел
- CloneNode()
- Syntax
- Example
- Execution
- Navigating Through Nodes
- DOM – Entity Object
- Errors in XML Document
- XML – Зрители
- XML DOM — Remove Node
- XML – обработка
- DOM – Node Object
- DOM – Атрибут Объект
- DOM – нотация объекта
- Is XML a Programming Language?
- Change Value of Text Node
- Example
- Execution
- XML — Syntax
- Change Value of Attribute Node
- Example
- Execution
- DOM — XMLHttpRequest Object
- DOM – объект ProcessingInstruction
- Rules
- XML Declaration Examples
- Setup
- Syntax
- XML DOM — Get Node
- XML – база данных включена
- Собственная база данных XML
- DOM — CDATASection Object
- XML DOM – Доступ
- XML – документы
- DOM — Notation Object
- Advantages of XML DOM
- First Child
- Example
- Execution
- DOM — DOMImplementation Object
- Типы баз данных XML
- DOM – родительский узел
- XML – древовидная структура
- Syntax
- Example
- Создать новый узел комментариев
- XML — Enabled Database
- Native XML Database
- Example
- XML DOM — Accessing
- XML – декларация
- ДОМ – Элемент Объект
- Node Types
- Internal DTD
- Syntax
- Example
- Rules
- Accessing Nodes
- XML – Кодировка
- Encoding Types
- XML DOM – узел клонирования
- What is Markup?
- XML – WhiteSpaces
- Syntax
- Example
- DOM – объект NamedNodeMap
- XML DOM — Model
- Example
- XML – Базы данных
- Правильно оформленный XML-документ
- InsertData()
- Syntax
- Example
- Execution
- XML — Processors
- Example
- Parser
- DOM – Объект DOMImplementation
- Firefox Browser
- XML DOM – обход
- Well-formed XML Document
- Example
- RemoveAttribute()
- Syntax
- Example
- Execution
- XML Comments Rules
- XML Database Types
- External DTD
- Syntax
- Example
- XML – пространства имен
- XML – парсеры
- Изменить значение узла атрибута
- XML – редакторы
- XML — Elements
- Types of Character Entities
- Predefined Character Entities
- Numeric Character Entities
- Named Character Entity
Example
<?xml version = "1.0"?> <Company> <Employee> <FirstName>Tanmay</FirstName> <LastName>Patil</LastName> <ContactNo>1234567890</ContactNo> <Email>tanmaypatil@xyz.com</Email> <Address> <City>Bangalore</City> <State>Karnataka</State> <Zip>560212</Zip> </Address> </Employee> </Company>
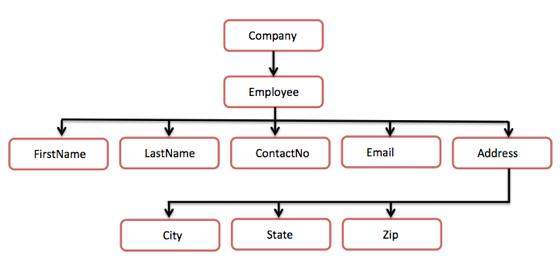
In the above diagram, there is a root element named as <company>. Inside that, there is one more element <Employee>. Inside the employee element, there are five branches named <FirstName>, <LastName>, <ContactNo>, <Email>, and <Address>. Inside the <Address> element, there are three sub-branches, named <City> <State> and <Zip>.
Syntax
<![CDATA[ characters with markup ]]>
The above syntax is composed of three sections −
CData section − Characters between these two enclosures are interpreted as characters, and not as markup. This section may contain markup characters (<, >, and &), but they are ignored by the XML processor.
Example
<script> <![CDATA[ <message> Welcome to TutorialsPoint </message> ]] > </script >
In the above syntax, everything between <message> and </message> is treated as character data and not as markup.
XML – Процессоры
Когда программа читает XML-документ и предпринимает соответствующие действия, это называется обработкой XML. Любая программа, которая может читать и обрабатывать документы XML, называется процессором XML . Процессор XML считывает файл XML и превращает его в структуры в памяти, к которым имеет доступ остальная часть программы.
Самый фундаментальный процессор XML читает документ XML и преобразует его во внутреннее представление для использования другими программами или подпрограммами. Это называется синтаксическим анализатором , и это важный компонент каждой программы обработки XML.
Процессор включает в себя обработку инструкций, которые можно изучить в главе Обработка инструкций .
XML – Обзор
XML расшифровывается как расширяемый язык. Это текстовый язык разметки, основанный на стандартном обобщенном языке разметки (SGML).
XML-теги идентифицируют данные и используются для хранения и организации данных, а не указывают, как их отображать как HTML-теги, которые используются для отображения данных. XML не собирается заменять HTML в ближайшем будущем, но он открывает новые возможности, применяя многие успешные функции HTML.
Есть три важных характеристики XML, которые делают его полезным в различных системах и решениях:
XML расширяем – XML позволяет вам создавать свои собственные описательные теги или язык, который подходит вашему приложению.
XML переносит данные, не представляет их – XML позволяет хранить данные независимо от того, как они будут представлены.
XML является общедоступным стандартом – XML был разработан организацией под названием World Wide Web Consortium (W3C) и доступен в качестве открытого стандарта.
XML расширяем – XML позволяет вам создавать свои собственные описательные теги или язык, который подходит вашему приложению.
XML переносит данные, не представляет их – XML позволяет хранить данные независимо от того, как они будут представлены.
XML является общедоступным стандартом – XML был разработан организацией под названием World Wide Web Consortium (W3C) и доступен в качестве открытого стандарта.
DOM — NamedNodeMap Object
The NamedNodeMap object is used to represent collections of nodes that can be accessed by name.
Является ли XML языком программирования?
Язык программирования состоит из грамматических правил и собственного словарного запаса, который используется для создания компьютерных программ. Эти программы инструктируют компьютер для выполнения определенных задач. XML не может считаться языком программирования, поскольку он не выполняет никаких вычислений или алгоритмов. Обычно он хранится в простом текстовом файле и обрабатывается специальным программным обеспечением, способным интерпретировать XML.
XML — Attributes
This chapter describes the XML attributes. Attributes are part of XML elements. An element can have multiple unique attributes. Attribute gives more information about XML elements. To be more precise, they define properties of elements. An XML attribute is always a name-value pair.
DOM — ProcessingInstruction Object
ProcessingInstruction gives that application-specific information which is generally included in the prolog section of the XML document.
Processing instructions (PIs) can be used to pass information to applications. PIs can appear anywhere in the document outside the markup. They can appear in the prolog, including the document type definition (DTD), in textual content, or after the document.
A PI starts with a special tag <? and ends with ?>. Processing of the contents ends immediately after the string ?> is encountered.
Empty Element
<name attribute1 attribute2.../>
<?xml version = "1.0"?> <contact-info> <address category = "residence"> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address> </contact-info>
XML — Tree Structure
An XML document is always descriptive. The tree structure is often referred to as XML Tree and plays an important role to describe any XML document easily.
The tree structure contains root (parent) elements, child elements and so on. By using tree structure, you can get to know all succeeding branches and sub-branches starting from the root. The parsing starts at the root, then moves down the first branch to an element, take the first branch from there, and so on to the leaf nodes.
Содержимое как строка XML
В следующем примере показано, как загружать данные XML с помощью Ajax и Javascript, когда содержимое XML принимается в виде файла XML. Здесь функция Ajax получает содержимое XML-файла и сохраняет его в XML DOM. Как только объект DOM создан, он затем анализируется.
<!DOCTYPE html>
<html> <head> <script> // loads the xml string in a dom object function loadXMLString(t) { // for non IE browsers if (window.DOMParser) { // create an instance for xml dom object parser = new DOMParser(); xmlDoc = parser.parseFromString(t,"text/xml"); } // code for IE else { // create an instance for xml dom object xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); xmlDoc.async = false; xmlDoc.loadXML(t); } return xmlDoc; } </script> </head> <body> <script> // a variable with the string var text = "<Employee>"; text = text+"<FirstName>Tanmay</FirstName>"; text = text+"<LastName>Patil</LastName>"; text = text+"<ContactNo>1234567890</ContactNo>"; text = text+"<Email>tanmaypatil@xyz.com</Email>"; text = text+"</Employee>"; // calls the loadXMLString() with "text" function and store the xml dom in a variable var xmlDoc = loadXMLString(text); //parsing the DOM object y = xmlDoc.documentElement.childNodes; for (i = 0;i<y.length;i++) { document.write(y[i].childNodes[0].nodeValue); document.write("<br>"); } </script> </body>
</html>Большинство деталей кода находится в коде скрипта.
Internet Explorer использует ActiveXObject («Microsoft.XMLDOM») для загрузки данных XML в объект DOM, другие браузеры используют функцию DOMParser () и метод parseFromString (text, ‘text / xml’) .
Переменная text должна содержать строку с содержимым XML.
Как только содержимое XML преобразуется в JavaScript XML DOM, вы можете получить доступ к любому элементу XML с помощью методов и свойств JS DOM. Мы использовали свойства DOM, такие как childNodes , nodeValue .
Internet Explorer использует ActiveXObject («Microsoft.XMLDOM») для загрузки данных XML в объект DOM, другие браузеры используют функцию DOMParser () и метод parseFromString (text, ‘text / xml’) .
Переменная text должна содержать строку с содержимым XML.
Как только содержимое XML преобразуется в JavaScript XML DOM, вы можете получить доступ к любому элементу XML с помощью методов и свойств JS DOM. Мы использовали свойства DOM, такие как childNodes , nodeValue .
Сохраните этот файл как loadingexample.html и откройте его в своем браузере. Вы увидите следующий вывод –
Теперь, когда мы увидели, как содержимое XML преобразуется в JavaScript XML DOM, теперь вы можете получить доступ к любому элементу XML с помощью методов XML DOM.
Element Attribute Rules
An attribute name must not appear more than once in the same start-tag or empty-element tag.
An attribute must be declared in the Document Type Definition (DTD) using an Attribute-List Declaration.
Attribute values must not contain direct or indirect entity references to external entities.
The replacement text of any entity referred to directly or indirectly in an attribute value must not contain a less than sign (<)
Syntax
Example
<?xml version = "1.0" encoding = "UTF-8"?> <xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema"> <xs:element name = "contact"> <xs:complexType> <xs:sequence> <xs:element name = "name" type = "xs:string" /> <xs:element name = "company" type = "xs:string" /> <xs:element name = "phone" type = "xs:int" /> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
The basic idea behind XML Schemas is that they describe the legitimate format that an XML document can take.
DOM — DOMException Object
The DOMException represents an abnormal event happening when a method or a property is used.
Create New CDATA Section Node
The method createCDATASection() creates a new CDATA section node. If the newly created CDATA section node exists in the element object, it is replaced by the new one.
Syntax
var_name = xmldoc.createCDATASection("tagname");(«tagname») − is the name of new CDATA section node to be created.
Example
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); create_CDATA = xmlDoc.createCDATASection("Create CDATA Example"); x = xmlDoc.getElementsByTagName("Employee")[0]; x.appendChild(create_CDATA); document.write(x.lastChild.nodeValue); </script> </body>
</html>In the above example −
create_CDATA = xmlDoc.createCDATASection(«Create CDATA Example») creates a new CDATA section node, «Create CDATA Example»
x.appendChild(create_CDATA) here, x holds the specified element <Employee> indexed at 0 to which the CDATA node value is appended.
Execution
Save this file as createcdatanode_example.htm on the server path (this file and node.xml should be on the same path in your server). In the output, we get the attribute value as Create CDATA Example.
Создать новый текстовый узел
Метод createTextNode () создает новый текстовый узел.
Синтаксис для использования createTextNode () выглядит следующим образом –
var_name = xmldoc.createTextNode("tagname");var_name – это имя пользовательской переменной, которая содержит имя нового текстового узла.
(«tagname») – в скобках указано имя нового текстового узла, который будет создан.
var_name – это имя пользовательской переменной, которая содержит имя нового текстового узла.
(«tagname») – в скобках указано имя нового текстового узла, который будет создан.
В следующем примере (createtextnode_example.htm) анализируется XML-документ ( node.xml ) в объект XML DOM и создается новый текстовый узел Im new text node в XML-документе.
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); create_e = xmlDoc.createElement("PhoneNo"); create_t = xmlDoc.createTextNode("Im new text node"); create_e.appendChild(create_t); x = xmlDoc.getElementsByTagName("Employee")[0]; x.appendChild(create_e); document.write(" PhoneNO: "); document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue); </script> </body>
</html>Подробности вышеупомянутого кода как ниже –
create_e = xmlDoc.createElement (“PhoneNo”); создает новый элемент < PhoneNo >.
create_t = xmlDoc.createTextNode («Я новый текстовый узел»); создает новый текстовый узел “Im new text node” .
текстовый узел «Новый текстовый узел» добавляется к элементу < PhoneNo >.
create_e = xmlDoc.createElement (“PhoneNo”); создает новый элемент < PhoneNo >.
create_t = xmlDoc.createTextNode («Я новый текстовый узел»); создает новый текстовый узел “Im new text node” .
текстовый узел «Новый текстовый узел» добавляется к элементу < PhoneNo >.
Сохраните этот файл как createtextnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В выводе мы получаем значение атрибута как, например, PhoneNO: Im новый текстовый узел .
Пройдя через узлы
Это описано в главе DOM Traversing с примерами.
Namespace Declaration
A Namespace is declared using reserved attributes. Such an attribute name must either be xmlns or begin with xmlns: shown as below −
<element xmlns:name = "URL">
Content as XML file
<!DOCTYPE html>
<html> <body> <div> <b>FirstName:</b> <span id = "FirstName"></span><br> <b>LastName:</b> <span id = "LastName"></span><br> <b>ContactNo:</b> <span id = "ContactNo"></span><br> <b>Email:</b> <span id = "Email"></span> </div> <script> //if browser supports XMLHttpRequest if (window.XMLHttpRequest) { // Create an instance of XMLHttpRequest object. code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest(); } else { // code for IE6, IE5 xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } // sets and sends the request for calling "node.xml" xmlhttp.open("GET","/dom/node.xml",false); xmlhttp.send(); // sets and returns the content as XML DOM xmlDoc = xmlhttp.responseXML; //parsing the DOM object document.getElementById("FirstName").innerHTML = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue; document.getElementById("LastName").innerHTML = xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue; document.getElementById("ContactNo").innerHTML = xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0].nodeValue; document.getElementById("Email").innerHTML = xmlDoc.getElementsByTagName("Email")[0].childNodes[0].nodeValue; </script> </body>
</html>node.xml
<Company> <Employee category = "Technical" id = "firstelement"> <FirstName>Tanmay</FirstName> <LastName>Patil</LastName> <ContactNo>1234567890</ContactNo> <Email>tanmaypatil@xyz.com</Email> </Employee> <Employee category = "Non-Technical"> <FirstName>Taniya</FirstName> <LastName>Mishra</LastName> <ContactNo>1234667898</ContactNo> <Email>taniyamishra@xyz.com</Email> </Employee> <Employee category = "Management"> <FirstName>Tanisha</FirstName> <LastName>Sharma</LastName> <ContactNo>1234562350</ContactNo> <Email>tanishasharma@xyz.com</Email> </Employee> </Company>
Most of the details of the code are in the script code.
Internet Explorer uses the ActiveXObject(«Microsoft.XMLHTTP») to create an instance of XMLHttpRequest object, other browsers use the XMLHttpRequest() method.
the responseXML transforms the XML content directly in XML DOM.
Once the XML content is transformed into JavaScript XML DOM, you can access any XML element by using the JS DOM methods and properties. We have used the DOM properties such as childNodes, nodeValue and DOM methods such as getElementsById(ID), getElementsByTagName(tags_name).
Execution

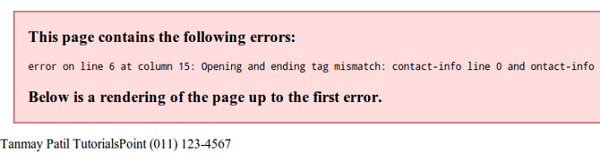
Ошибки в XML-документе
Если в вашем XML-коде отсутствуют какие-либо теги, в браузере отображается сообщение. Давайте попробуем открыть следующий файл XML в Chrome –
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
В приведенном выше коде начальный и конечный теги не совпадают (см. Тег contact_info), поэтому браузер отображает сообщение об ошибке, как показано ниже:

XML – разделы CDATA
В этой главе мы обсудим раздел XML CDATA . Термин CDATA означает «Персональные данные». CDATA определяется как блоки текста, которые не анализируются синтаксическим анализатором, но в противном случае распознаются как разметка.
Предопределенные объекты, такие как & lt ;, & gt; и & amp; требуют ввода и, как правило, их трудно прочитать в разметке. В таких случаях может использоваться раздел CDATA. Используя раздел CDATA, вы даете команду синтаксическому анализатору на то, что конкретный раздел документа не содержит разметки и должен рассматриваться как обычный текст.
Text Editors
Any simple text editor such as Notepad, TextPad, or TextEdit can be used to create or view an XML document as shown below −
XML — Namespaces
A Namespace is a set of unique names. Namespace is a mechanisms by which element and attribute name can be assigned to a group. The Namespace is identified by URI(Uniform Resource Identifiers).
DOM — DocumentType Object
The DocumentType objects are the key to access the document’s data and in the document, the doctype attribute can have either the null value or the DocumentType Object value. These DocumentType objects act as an interface to the entities described for an XML document.
XML DOM — Loading
In this chapter, we will study about XML Loading and Parsing.
In order to describe the interfaces provided by the API, the W3C uses an abstract language called the Interface Definition Language (IDL). The advantage of using IDL is that the developer learns how to use the DOM with his or her favorite language and can switch easily to a different language.
The disadvantage is that, since it is abstract, the IDL cannot be used directly by Web developers. Due to the differences between programming languages, they need to have mapping — or binding — between the abstract interfaces and their concrete languages. DOM has been mapped to programming languages such as Javascript, JScript, Java, C, C++, PLSQL, Python, and Perl.
In the following sections and chapters, we will be using Javascript as our programming language to load XML file.
DOM — Attribute Object
Attr interface represents an attribute in an Element object. Typically, the allowable values for the attribute are defined in a schema associated with the document. Attr objects are not considered as part of the document tree since they are not actually child nodes of the element they describe. Thus for the child nodes parentNode, previousSibling and nextSibling the attribute value is null.
DOM – объект XMLHttpRequest
Объект XMLHttpRequest устанавливает посредник между клиентской и серверной сторонами веб-страницы, который может использоваться многими языками сценариев, такими как JavaScript, JScript, VBScript и другими веб-браузерами, для передачи и манипулирования данными XML.
С помощью объекта XMLHttpRequest можно обновлять часть веб-страницы без перезагрузки всей страницы, запрашивать и получать данные с сервера после загрузки страницы и отправлять данные на сервер.
Теги и элементы
Файл XML структурирован несколькими XML-элементами, также называемыми XML-узлами или XML-тегами. Имена XML-элементов заключены в треугольные скобки <>, как показано ниже –
<element>
Синтаксические правила для тегов и элементов
Синтаксис элемента – каждый XML-элемент должен быть закрыт либо начальным, либо конечным элементом, как показано ниже –
<element>....</element>
или в простых случаях, просто так –
<element/>
Вложенность элементов – XML-элемент может содержать несколько XML-элементов в качестве своих дочерних элементов, но дочерние элементы не должны перекрываться. т. е. конечный тег элемента должен иметь то же имя, что и у самого последнего непревзойденного начального тега.
В следующем примере показаны неверные вложенные теги.
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint <contact-info> </company>
В следующем примере показаны правильные вложенные теги –
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint</company> <contact-info>
Корневой элемент – XML-документ может иметь только один корневой элемент. Например, следующее не является правильным XML-документом, поскольку элементы x и y находятся на верхнем уровне без корневого элемента –
<x>...</x> <y>...</y>
В следующем примере показан правильно сформированный документ XML:
<root> <x>...</x> <y>...</y> </root>
Чувствительность к регистру – Имена XML-элементов чувствительны к регистру. Это означает, что имя начального и конечного элементов должно быть точно в одном и том же случае.
Например, <контактная информация> отличается от <контактная информация>
Получить значение узла
Метод getElementsByTagName () возвращает NodeList всех элементов в порядке документа с заданным именем тега.
В следующем примере (getnode_example.htm) анализируется XML-документ ( node.xml ) в объект XML DOM и извлекается значение узла дочернего узла Firstname (индекс в 0) –
<!DOCTYPE html>
<html> <body> <script> if (window.XMLHttpRequest) { xmlhttp = new XMLHttpRequest(); } else{ xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xmlhttp.open("GET","/dom/node.xml",false); xmlhttp.send(); xmlDoc = xmlhttp.responseXML; x = xmlDoc.getElementsByTagName('FirstName')[0] y = x.childNodes[0]; document.write(y.nodeValue); </script> </body>
</html>Сохраните этот файл как getnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение узла как Tanmay .
Syntax
<element-name attribute1 attribute2 > ....content.. < /element-name>
name = "value"
value has to be in double (» «) or single (‘ ‘) quotes. Here, attribute1 and attribute2 are unique attribute labels.
<?xml version = "1.0" encoding = "UTF-8"?> <!DOCTYPE garden [ <!ELEMENT garden (plants)*> <!ELEMENT plants (#PCDATA)> <!ATTLIST plants category CDATA #REQUIRED> ]> <garden> <plants category = "flowers" /> <plants category = "shrubs"> </plants> </garden>
Attributes are used to distinguish among elements of the same name, when you do not want to create a new element for every situation. Hence, the use of an attribute can add a little more detail in differentiating two or more similar elements.
In the above example, we have categorized the plants by including attribute category and assigning different values to each of the elements. Hence, we have two categories of plants, one flowers and other shrubs. Thus, we have two plant elements with different attributes.
You can also observe that we have declared this attribute at the beginning of XML.
Content as XML string
<!DOCTYPE html>
<html> <head> <script> // loads the xml string in a dom object function loadXMLString(t) { // for non IE browsers if (window.DOMParser) { // create an instance for xml dom object parser = new DOMParser(); xmlDoc = parser.parseFromString(t,"text/xml"); } // code for IE else { // create an instance for xml dom object xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); xmlDoc.async = false; xmlDoc.loadXML(t); } return xmlDoc; } </script> </head> <body> <script> // a variable with the string var text = "<Employee>"; text = text+"<FirstName>Tanmay</FirstName>"; text = text+"<LastName>Patil</LastName>"; text = text+"<ContactNo>1234567890</ContactNo>"; text = text+"<Email>tanmaypatil@xyz.com</Email>"; text = text+"</Employee>"; // calls the loadXMLString() with "text" function and store the xml dom in a variable var xmlDoc = loadXMLString(text); //parsing the DOM object y = xmlDoc.documentElement.childNodes; for (i = 0;i<y.length;i++) { document.write(y[i].childNodes[0].nodeValue); document.write("<br>"); } </script> </body>
</html>Most of the details of the code are in the script code.
Internet Explorer uses the ActiveXObject(«Microsoft.XMLDOM») to load XML data into a DOM object, other browsers use the DOMParser() function and parseFromString(text, ‘text/xml’) method.
The variable text shall contain a string with XML content.
Once the XML content is transformed into JavaScript XML DOM, you can access any XML element by using JS DOM methods and properties. We have used DOM properties such as childNodes, nodeValue.
Execution

Now that we saw how the XML content transforms into JavaScript XML DOM, you can now access any XML element by using the XML DOM methods.
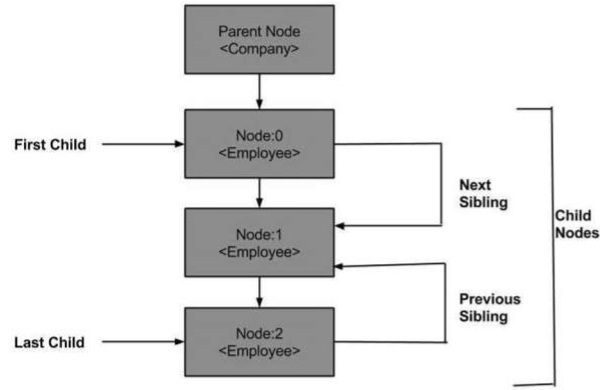
XML DOM — Navigation
Until now we studied DOM structure, how to load and parse XML DOM object and traverse through the DOM objects. Here we will see how we can navigate between nodes in a DOM object. The XML DOM consist of various properties of the nodes which help us navigate through the nodes, such as −
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
XML — Character Entities
This chapter describes the XML Character Entities. Before we understand the Character Entities, let us first understand what an XML entity is.
«The document entity serves as the root of the entity tree and a starting-point for an XML processor».
This means, entities are the placeholders in XML. These can be declared in the document prolog or in a DTD. There are different types of entities and in this chapter we will discuss Character Entity.
Both, HTML and XML, have some symbols reserved for their use, which cannot be used as content in XML code. For example, < and > signs are used for opening and closing XML tags. To display these special characters, the character entities are used.
There are few special characters or symbols which are not available to be typed directly from the keyboard. Character Entities can also be used to display those symbols/special characters.
XML — Editors
XML Editor is a markup language editor. The XML documents can be edited or created using existing editors such as Notepad, WordPad, or any similar text editor. You can also find a professional XML editor online or for downloading, which has more powerful editing features such as −
- It automatically closes the tags that are left open.
- It strictly checks syntax.
- It highlights XML syntax with colour for increased readability.
- It helps you write a valid XML code.
- It provides automatic verification of XML documents against DTDs and Schemas.
DOM – DocumentType Object
Объекты DocumentType являются ключом для доступа к данным документа, и в документе атрибут doctype может иметь либо нулевое значение, либо значение объекта DocumentType. Эти объекты DocumentType действуют как интерфейс для сущностей, описанных для документа XML.
XML DOM – навигация
До сих пор мы изучали структуру DOM, как загружать и анализировать XML-объект DOM и проходить через объекты DOM. Здесь мы увидим, как мы можем перемещаться между узлами в DOM-объекте. XML DOM состоит из различных свойств узлов, которые помогают нам перемещаться по узлам, таких как –
Ниже приведена схема дерева узлов, показывающая его связь с другими узлами.

XML Usage
A short list of XML usage says it all −
XML can work behind the scene to simplify the creation of HTML documents for large web sites.
XML can be used to exchange the information between organizations and systems.
XML can be used for offloading and reloading of databases.
XML can be used to store and arrange the data, which can customize your data handling needs.
XML can easily be merged with style sheets to create almost any desired output.
Virtually, any type of data can be expressed as an XML document.
Open Source XML Editors
Online XML Editor − This is a light weight XML editor which you can use online.
Xerlin − Xerlin is an open source XML editor for Java 2 platform released under an Apache license. It is a Java based XML modelling application, for creating and editing XML files easily.
CAM — Content Assembly Mechanism − CAM XML Editor tool comes with XML+JSON+SQL Open-XDX sponsored by Oracle.
GetElementsByTagName ()
This method allows accessing the information of a node by specifying the node name. It also allows accessing the information of the Node List and Node List Length.
Syntax
node.getElementByTagName("tagname");node − is the document node.
tagname − holds the name of the node whose value you want to get.
Example
<!DOCTYPE html>
<html> <body> <div> <b>FirstName:</b> <span id = "FirstName"></span><br> <b>LastName:</b> <span id = "LastName"></span><br> <b>Category:</b> <span id = "Employee"></span><br> </div> <script> if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest(); } else {// code for IE6, IE5 xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xmlhttp.open("GET","/dom/node.xml",false); xmlhttp.send(); xmlDoc = xmlhttp.responseXML; document.getElementById("FirstName").innerHTML = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue; document.getElementById("LastName").innerHTML = xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue; document.getElementById("Employee").innerHTML = xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue; </script> </body>
</html>In the above example, we are accessing the information of the nodes FirstName,
LastName and Employee.
XML — Viewers
This chapter describes THE various methods to view an XML document. An XML document can be viewed using a simple text editor or any browser. Most of the major browsers supports XML. XML files can be opened in the browser by just double-clicking the XML document (if it is a local file) or by typing the URL path in the address bar (if the file is located on the server), in the same way as we open other files in the browser. XML files are saved with a «.xml» extension.
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
XML – DOM
Объектная модель документа (DOM) является основой XML. XML-документы имеют иерархию информационных единиц, называемых узлами ; DOM – это способ описания этих узлов и отношений между ними.
Документ DOM – это набор узлов или фрагментов информации, организованных в иерархию. Эта иерархия позволяет разработчику перемещаться по дереву в поисках конкретной информации. Поскольку он основан на иерархии информации, DOM называется древовидным .
XML DOM, с другой стороны, также предоставляет API, который позволяет разработчику добавлять, редактировать, перемещать или удалять узлы в дереве в любой точке для создания приложения.
ReplaceChild()
The method replaceChild() replaces the specified node with the new node.
Syntax
Node replaceChild(Node newChild, Node oldChild) throws DOMException
newChild − is the new node to put in the child list.
oldChild − is the node being replaced in the list.
This method returns the node replaced.
Example
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); x = xmlDoc.documentElement; z = xmlDoc.getElementsByTagName("FirstName"); document.write("<b>Content of FirstName element before replace operation</b><br>"); for (i=0;i<z.length;i++) { document.write(z[i].childNodes[0].nodeValue); document.write("<br>"); } //create a Employee element, FirstName element and a text node newNode = xmlDoc.createElement("Employee"); newTitle = xmlDoc.createElement("Name"); newText = xmlDoc.createTextNode("MS Dhoni"); //add the text node to the title node, newTitle.appendChild(newText); //add the title node to the book node newNode.appendChild(newTitle); y = xmlDoc.getElementsByTagName("Employee")[0] //replace the first book node with the new node x.replaceChild(newNode,y); z = xmlDoc.getElementsByTagName("FirstName"); document.write("<b>Content of FirstName element after replace operation</b><br>"); for (i = 0;i<z.length;i++) { document.write(z[i].childNodes[0].nodeValue); document.write("<br>"); } </script> </body>
</html>Execution
Save this file as replacenode_example.htm on the server path (this file and node.xml should be on the same path in your server). We will get the output as shown below −
Content of FirstName element before replace operation Tanmay Taniya Tanisha Content of FirstName element after replace operation Taniya Tanisha
DOM Parser API
Let’s note down some broad steps to create and use a DOM parser to parse an XML file in java.
1.1. Import dom Parser Packages
We will need to import dom parser packages first in our application.
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;1.2. Create DocumentBuilder
The next step is to create the DocumentBuilder object.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();1.3. Create Document object from XML file
Read the XML file to Document object.
Document document = builder.parse(new File( file ));1.4. Validate Document Structure
XML validation is optional but good to have it before starting parsing.
Schema schema = null;
try { String language = XMLConstants.W3C_XML_SCHEMA_NS_URI; SchemaFactory factory = SchemaFactory.newInstance(language); schema = factory.newSchema(new File(name));
} catch (Exception e) { e.printStackStrace();
}
Validator validator = schema.newValidator();
validator.validate(new DOMSource(document));1.5. Extract the Root Element
We can get the root element from the XML document using the below code.
Element root = document.getDocumentElement();1.6. Examine Attributes
We can examine the XML element attributes using the below methods.
element.getAttribute("attributeName") ; //returns specific attribute
element.getAttributes(); //returns a Map (table) of names/values1.7. Examine Child-Elements
Child elements for a specified Node can be inquired about in the below manner.
node.getElementsByTagName("subElementName"); //returns a list of sub-elements of specified name
node.getChildNodes(); //returns a list of all child nodespublic static Document readXMLDocumentFromFile(String fileNameWithPath) throws Exception { //Get Document Builder DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); //Build Document Document document = builder.parse(new File(fileNameWithPath)); //Normalize the XML Structure; It's just too important !! document.getDocumentElement().normalize(); return document;
}Now we can use this method to parse the XML file and verify the content.
public static void main(String[] args) throws Exception { Document document = readXMLDocumentFromFile("c:/temp/employees.xml"); //Verify XML Content //Here comes the root node Element root = document.getDocumentElement(); System.out.println(root.getNodeName()); //Get all employees NodeList nList = document.getElementsByTagName("employee"); System.out.println("============================"); for (int temp = 0; temp < nList.getLength(); temp++) { Node node = nList.item(temp); if (node.getNodeType() == Node.ELEMENT_NODE) { //Print each employee's detail Element eElement = (Element) node; System.out.println("\nEmployee id : " + eElement.getAttribute("id")); System.out.println("First Name : " + eElement.getElementsByTagName("firstName").item(0).getTextContent()); System.out.println("Last Name : " + eElement.getElementsByTagName("lastName").item(0).getTextContent()); System.out.println("Location : " + eElement.getElementsByTagName("location").item(0).getTextContent()); } }
}employees
============================
Employee id : 111
First Name : Lokesh
Last Name : Gupta
Location : India
Employee id : 222
First Name : Alex
Last Name : Gussin
Location : Russia
Employee id : 333
First Name : David
Last Name : Feezor
Location : USASyntax
<?target instructions?>
target − Identifies the application to which the instruction is directed.
instruction − A character that describes the information for the application to process.
A PI starts with a special tag <? and ends with ?>. Processing of the contents ends immediately after the string ?> is encountered.
Example
<?xml-stylesheet href = "tutorialspointstyle.css" type = "text/css"?>
Here, the target is xml-stylesheet. data-hren=»tutorialspointstyle.css» and type=»text/css» are data or instructions the target application will use at the time of processing the given XML document.
In this case, a browser recognizes the target by indicating that the XML should be transformed before being shown; the first attribute states that the type of the transform is XSL and the second attribute points to its location.
Types
You can refer to an external DTD by using either system identifiers or public identifiers.
System Identifiers
<!DOCTYPE name SYSTEM "address.dtd" [...]>
As you can see, it contains keyword SYSTEM and a URI reference pointing to the location of the document.
Public Identifiers
<!DOCTYPE name PUBLIC "-//Beginning XML//DTD Address Example//EN">
XML — DTDs
The XML Document Type Declaration, commonly known as DTD, is a way to describe XML language precisely. DTDs check vocabulary and validity of the structure of XML documents against grammatical rules of appropriate XML language.
An XML DTD can be either specified inside the document, or it can be kept in a separate document and then liked separately.
Examples
node.xml contents are as below −
<?xml version = "1.0"?> <Company> <Employee category = "Technical"> <FirstName>Tanmay</FirstName> <LastName>Patil</LastName> <ContactNo>1234567890</ContactNo> <Email>tanmaypatil@xyz.com</Email> </Employee> <Employee category = "Non-Technical"> <FirstName>Taniya</FirstName> <LastName>Mishra</LastName> <ContactNo>1234667898</ContactNo> <Email>taniyamishra@xyz.com</Email> </Employee> <Employee category = "Management"> <FirstName>Tanisha</FirstName> <LastName>Sharma</LastName> <ContactNo>1234562350</ContactNo> <Email>tanishasharma@xyz.com</Email> </Employee> </Company>
Retrieve specific information of a resource file
<!DOCTYPE html>
<html> <head> <meta http-equiv = "content-type" content = "text/html; charset = iso-8859-2" /> <script> function loadXMLDoc() { var xmlHttp = null; if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... { xmlHttp = new XMLHttpRequest(); } else if(window.ActiveXObject) // for Internet Explorer 5 or 6 { xmlHttp = new ActiveXObject("Microsoft.XMLHTTP"); } return xmlHttp; } function makerequest(serverPage, myDiv) { var request = loadXMLDoc(); request.open("GET", serverPage); request.send(null); request.onreadystatechange = function() { if (request.readyState == 4) { document.getElementById(myDiv).innerHTML = request.getResponseHeader("Content-length"); } } } </script> </head> <body> <button type = "button" onclick="makerequest('/dom/node.xml', 'ID')">Click me to get the specific ResponseHeader</button> <div id = "ID">Specific header information is returned.</div> </body>
</html>Execution
Save this file as elementattribute_removeAttributeNS.htm on the server path (this file and node_ns.xml should be on the same path in your server). We will get the output as shown below −
Before removing the attributeNS: en After removing the attributeNS: null
Retrieve header infomation of a resource file
<!DOCTYPE html>
<html> <head> <meta http-equiv="content-type" content="text/html; charset=iso-8859-2" /> <script> function loadXMLDoc() { var xmlHttp = null; if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... { xmlHttp = new XMLHttpRequest(); } else if(window.ActiveXObject) // for Internet Explorer 5 or 6 { xmlHttp = new ActiveXObject("Microsoft.XMLHTTP"); } return xmlHttp; } function makerequest(serverPage, myDiv) { var request = loadXMLDoc(); request.open("GET", serverPage); request.send(null); request.onreadystatechange = function() { if (request.readyState == 4) { document.getElementById(myDiv).innerHTML = request.getAllResponseHeaders(); } } } </script> </head> <body> <button type = "button" onclick = "makerequest('/dom/node.xml', 'ID')"> Click me to load the AllResponseHeaders</button> <div id = "ID"></div> </body>
</html>Execution
Save this file as http_allheader.html on the server path (this file and node.xml should be on the same path in your server). We will get the output as shown below (depends on the browser) −
Date: Sat, 27 Sep 2014 07:48:07 GMT Server: Apache Last-Modified: Wed, 03 Sep 2014 06:35:30 GMT Etag: "464bf9-2af-50223713b8a60" Accept-Ranges: bytes Vary: Accept-Encoding,User-Agent Content-Encoding: gzip Content-Length: 256 Content-Type: text/xml
XML Document Example
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>

XML DOM — Add Node
In this chapter, we will discuss the nodes to the existing element. It provides a means to −
append new child nodes before or after the existing child nodes
insert data within the text node
add attribute node
- appendChild()
- insertBefore()
- insertData()
XML-редакторы с открытым исходным кодом
Ниже приведены некоторые XML-редакторы с открытым исходным кодом.
Онлайн XML Editor – это легкий XML редактор, который вы можете использовать онлайн.
Xerlin – Xerlin – это редактор XML с открытым исходным кодом для платформы Java 2, выпущенный по лицензии Apache. Это приложение для моделирования XML на основе Java, предназначенное для простого создания и редактирования файлов XML.
CAM – механизм сборки контента – CAM XML Editor поставляется с XML + JSON + SQL Open-XDX, спонсируемым Oracle.
Онлайн XML Editor – это легкий XML редактор, который вы можете использовать онлайн.
Xerlin – Xerlin – это редактор XML с открытым исходным кодом для платформы Java 2, выпущенный по лицензии Apache. Это приложение для моделирования XML на основе Java, предназначенное для простого создания и редактирования файлов XML.
CAM – механизм сборки контента – CAM XML Editor поставляется с XML + JSON + SQL Open-XDX, спонсируемым Oracle.
XML DOM – Создать узел
В этой главе мы обсудим, как создавать новые узлы, используя несколько методов объекта документа. Эти методы обеспечивают область для создания нового узла элемента, текстового узла, узла комментария, узла раздела CDATA и узла атрибута . Если вновь созданный узел уже существует в объекте элемента, он заменяется новым. Следующие разделы демонстрируют это на примерах.
CloneNode()
Syntax
Node cloneNode(boolean deep)
deep − If true, recursively clones the subtree under the specified node; if false, clone only the node itself (and its attributes, if it is an Element).
This method returns the duplicate node.
Example
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); x = xmlDoc.getElementsByTagName('Employee')[0]; clone_node = x.cloneNode(true); xmlDoc.documentElement.appendChild(clone_node); firstname = xmlDoc.getElementsByTagName("FirstName"); lastname = xmlDoc.getElementsByTagName("LastName"); contact = xmlDoc.getElementsByTagName("ContactNo"); email = xmlDoc.getElementsByTagName("Email"); for (i = 0;i < firstname.length;i++) { document.write(firstname[i].childNodes[0].nodeValue+' '+lastname[i].childNodes[0].nodeValue+', '+contact[i].childNodes[0].nodeValue+', '+email[i].childNodes[0].nodeValue); document.write("<br>"); } </script> </body>
</html>As you can see in the above example, we have set the cloneNode() param to true. Hence each of the child element under the Employee element is copied or cloned.
Execution
Save this file as clonenode_example.htm on the server path (this file and node.xml should be on the same path in your server). We will get the output as shown below −
Tanmay Patil, 1234567890, tanmaypatil@xyz.com Taniya Mishra, 1234667898, taniyamishra@xyz.com Tanisha Sharma, 1234562350, tanishasharma@xyz.com Tanmay Patil, 1234567890, tanmaypatil@xyz.com
You will notice that the first Employee element is cloned completely.
Navigating Through Nodes
This is covered in the chapter DOM Navigation with examples.
DOM – Entity Object
Интерфейс сущности представляет известную сущность, анализируемую или не разбираемую, в документе XML. Атрибут nodeName , унаследованный от Node, содержит имя объекта.
Объект Entity не имеет родительского узла, и все его последующие узлы доступны только для чтения.
Errors in XML Document
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
In the above code, the start and end tags are not matching (refer the contact_info tag), hence an error message is displayed by the browser as shown below −
XML – Зрители
В этой главе описываются различные методы просмотра XML-документа . Документ XML можно просмотреть с помощью простого текстового редактора или любого браузера. Большинство основных браузеров поддерживают XML. Файлы XML можно открыть в браузере, просто дважды щелкнув документ XML (если это локальный файл) или введя URL-адрес в адресной строке (если файл расположен на сервере), так же, как мы открываем другие файлы в браузере. Файлы XML сохраняются с расширением «.xml» .
Давайте рассмотрим различные методы, с помощью которых мы можем просматривать XML-файл. Следующий пример (sample.xml) используется для просмотра всех разделов этой главы.
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
XML DOM — Remove Node
In this chapter, we will study about the XML DOM Remove Node operation. The remove node operation removes the specified node from the document. This operation can be implemented to remove the nodes like text node, element node or an attribute node.
XML – обработка
В этой главе описываются инструкции по обработке (PI) . Как определено Рекомендацией XML 1.0,
«Инструкции обработки (PI) позволяют документам содержать инструкции для приложений. PI не являются частью символьных данных документа, но ДОЛЖНЫ передаваться приложению.
Инструкции по обработке (PI) могут использоваться для передачи информации приложениям. PI могут появляться в любом месте документа вне разметки. Они могут появляться в прологе, включая определение типа документа (DTD), в текстовом содержимом или после документа.
DOM – Node Object
Интерфейс узла является основным типом данных для всей объектной модели документа. Узел используется для представления одного элемента XML во всем дереве документа.
Узел может быть любого типа, который является узлом атрибута, текстовым узлом или любым другим узлом. Атрибуты nodeName, nodeValue и атрибуты включены в качестве механизма для получения информации об узле, не обращаясь к конкретному производному интерфейсу.
DOM – Атрибут Объект
Интерфейс Attr представляет атрибут в объекте Element. Как правило, допустимые значения для атрибута определяются в схеме, связанной с документом. Объекты Attr не рассматриваются как часть дерева документа, поскольку они на самом деле не являются дочерними узлами элемента, который они описывают. Таким образом, для дочерних узлов parentNode , previousSibling и nextSibling значение атрибута равно нулю .
DOM – нотация объекта
В этой главе мы рассмотрим объект нотации XML DOM. Свойство объекта нотации обеспечивает область для распознавания формата элементов с атрибутом нотации, конкретной инструкцией обработки или данными, не относящимися к XML. Свойства объекта Node и методы могут быть выполнены на Объекте Обозначения, так как это также рассматривают как Узел.
Этот объект наследует методы и свойства от Node . Его nodeName – это имя нотации. Не имеет родителя.
Is XML a Programming Language?
A programming language consists of grammar rules and its own vocabulary which is used
to create computer programs. These programs instruct the computer to perform specific tasks. XML does not qualify to be a programming language as it does not perform any computation or algorithms. It is usually stored in a simple text file and is processed by special software that is capable of interpreting XML.
Change Value of Text Node
Example
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); x = xmlDoc.getElementsByTagName("Email"); for(i = 0;i<x.length;i++) { x[i].childNodes[0].nodeValue = "support@xyz.com"; document.write(i+'); document.write(x[i].childNodes[0].nodeValue); document.write('<br>'); } </script> </body>
</html>Execution
0) support@xyz.com 1) support@xyz.com 2) support@xyz.com
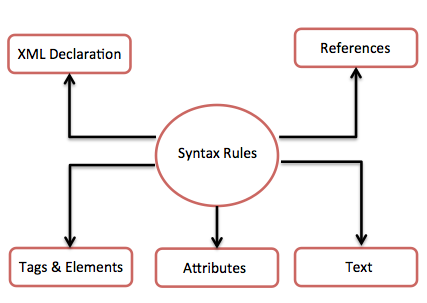
XML — Syntax
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
You can notice there are two kinds of information in the above example −
Markup, like <contact-info>
The text, or the character data, Tutorials Point and (040) 123-4567.
Let us see each component of the above diagram in detail.
Change Value of Attribute Node
Example
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); x = xmlDoc.getElementsByTagName("Employee"); for(i = 0 ;i<x.length;i++){ newcategory = x[i].getAttributeNode('category'); newcategory.nodeValue = "admin-"+i; document.write(i+'); document.write(x[i].getAttributeNode('category').nodeValue); document.write('<br>'); } </script> </body>
</html>Execution
Save this file as set_node_attribute_example.htm on the server path (this file and node.xml should be on the same path in your server). The result would be as below −
0) admin-0 1) admin-1 2) admin-2
DOM — XMLHttpRequest Object
XMLHttpRequest object establishes a medium between a web page’s client-side and server-side that can be used by the many scripting languages like JavaScript, JScript, VBScript and other web browser to transfer and manipulate the XML data.
With the XMLHttpRequest object it is possible to update the part of a web page without reloading the whole page, request and receive the data from a server after the page has been loaded and send the data to the server.
DOM – объект ProcessingInstruction
ProcessingInstruction предоставляет ту специфическую для приложения информацию, которая обычно включена в раздел пролога XML-документа.
Инструкции по обработке (PI) могут использоваться для передачи информации приложениям. PI могут появляться в любом месте документа вне разметки. Они могут появляться в прологе, включая определение типа документа (DTD), в текстовом содержимом или после документа.
PI начинается со специального тега <? и заканчивается ?> . Обработка содержимого заканчивается сразу после появления строки ?> .
Rules
If the XML declaration is present in the XML, it must be placed as the first line in the XML document.
If the XML declaration is included, it must contain version number attribute.
The Parameter names and values are case-sensitive.
The names are always in lower case.
The order of placing the parameters is important. The correct order is: version, encoding and standalone.
Either single or double quotes may be used.
The XML declaration has no closing tag i.e. </?xml>
XML Declaration Examples
XML declaration with no parameters −
<?xml >
XML declaration with version definition −
<?xml version = "1.0">
XML declaration with all parameters defined −
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
XML declaration with all parameters defined in single quotes −
<?xml version = '1.0' encoding = 'iso-8859-1' standalone = 'no' ?>
Setup
For demo purposes, we will be parsing the below XML file in all code examples.
<employees> <employee id="111"> <firstName>Lokesh</firstName> <lastName>Gupta</lastName> <location>India</location> </employee> <employee id="222"> <firstName>Alex</firstName> <lastName>Gussin</lastName> <location>Russia</location> </employee> <employee id="333"> <firstName>David</firstName> <lastName>Feezor</lastName> <location>USA</location> </employee>
</employees>Syntax
The Namespace starts with the keyword xmlns.
The word name is the Namespace prefix.
The URL is the Namespace identifier.
XML DOM — Get Node
In this chapter, we will study about how to get the node value of a XML DOM object. XML documents have a hierarchy of informational units called nodes. Node object has a property nodeValue, which returns the value of the element.
Getting node value of an element
Getting attribute value of a node
<Company> <Employee category = "Technical"> <FirstName>Tanmay</FirstName> <LastName>Patil</LastName> <ContactNo>1234567890</ContactNo> <Email>tanmaypatil@xyz.com</Email> </Employee> <Employee category = "Non-Technical"> <FirstName>Taniya</FirstName> <LastName>Mishra</LastName> <ContactNo>1234667898</ContactNo> <Email>taniyamishra@xyz.com</Email> </Employee> <Employee category = "Management"> <FirstName>Tanisha</FirstName> <LastName>Sharma</LastName> <ContactNo>1234562350</ContactNo> <Email>tanishasharma@xyz.com</Email> </Employee> </Company>
XML – база данных включена
База данных с поддержкой XML – это не что иное, как расширение, предоставляемое для преобразования документа XML. Это реляционная база данных, где данные хранятся в таблицах, состоящих из строк и столбцов. Таблицы содержат набор записей, которые в свою очередь состоят из полей.
Собственная база данных XML
Собственная база данных XML основана на контейнере, а не на табличном формате. Он может хранить большое количество XML-документа и данных. Собственная база данных XML запрашивается выражениями XPath .
Собственная база данных XML имеет преимущество перед базой данных с поддержкой XML. Он обладает высокой способностью хранить, запрашивать и поддерживать документ XML, чем база данных с поддержкой XML.
Следующий пример демонстрирует базу данных XML –
<?xml version = "1.0"?> <contact-info> <contact1> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact1> <contact2> <name>Manisha Patil</name> <company>TutorialsPoint</company> <phone>(011) 789-4567</phone> </contact2> </contact-info>
Здесь создается таблица контактов, которая содержит записи контактов (contact1 и contact2), которая в свою очередь состоит из трех объектов – имени, компании и телефона .
DOM — CDATASection Object
In this chapter, we will study about the XML DOM CDATASection Object. The text present within an XML document is parsed or unparsed depending on what it is declared. If the text is declared as Parse Character Data (PCDATA), it is parsed by the parser to convert an XML document into an XML DOM Object. On the other hand, if the text is declared as the unparsed Character Data (CDATA) the text within is not parsed by the XML parser. These are not considered as the markup and will not expand the entities.
The CharacterData.data attribute holds the text that is contained by the CDATA section. This interface inherits the CharatcterData interface through the Text interface.
There are no methods and attributes defined for the CDATASection object. It only directly implements the Text interface.
XML DOM – Доступ
В этой главе мы изучим, как получить доступ к узлам XML DOM, которые рассматриваются как информационные единицы документа XML. Структура узла XML DOM позволяет разработчику перемещаться по дереву в поисках конкретной информации и одновременно получать к ней доступ.
XML – документы
XML- документ – это базовая единица XML-информации, состоящая из элементов и другой разметки в упорядоченном пакете. XML- документ может содержать самые разные данные. Например, база данных чисел, чисел, представляющих молекулярную структуру или математическое уравнение.
DOM — Notation Object
In this chapter, we will study about the XML DOM Notation object. The notation object property provides a scope to recognize the format of elements with a notation attribute, a particular processing instruction or a non-XML data. The Node Object properties and methods can be performed on the Notation Object since that is also considered as a Node.
This object inherits methods and properties from Node. Its nodeName is the notation name. Has no parent.
Advantages of XML DOM
XML DOM is language and platform independent.
XML DOM is traversable — Information in XML DOM is organized in a hierarchy which allows developer to navigate around the hierarchy looking for specific information.
XML DOM is modifiable — It is dynamic in nature providing the developer a scope to add, edit, move or remove nodes at any point on the tree.
First Child
This property is of type Node and represents the first child name present in the NodeList.
Example
<!DOCTYPE html>
<html> <body> <script> if (window.XMLHttpRequest) { xmlhttp = new XMLHttpRequest(); } else { xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xmlhttp.open("GET","/dom/node.xml",false); xmlhttp.send(); xmlDoc = xmlhttp.responseXML; function get_firstChild(p) { a = p.firstChild; while (a.nodeType != 1) { a = a.nextSibling; } return a; } var firstchild = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]); document.write(firstchild.nodeName); </script> </body>
</html>Function get_firstChild(p) is used to avoid the empty nodes. It helps to get the firstChild element from the node list.
Execution
Save this file as first_node_example.htm on the server path (this file and node.xml should be on the same path in your server). In the output, we get the first child node of Employee i.e. FirstName.
DOM — DOMImplementation Object
The DOMImplementation object provides a number of methods for performing operations that are independent of any particular instance of the document object model.
Типы баз данных XML
Существует два основных типа баз данных XML:
- Собственный XML (NXD)
DOM – родительский узел
Это свойство определяет родительский узел как объект узла.
В следующем примере (navigate_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM. Затем объект DOM перемещается к родительскому узлу через дочерний узел –
<!DOCTYPE html>
<html> <body> <script> if (window.XMLHttpRequest) { xmlhttp = new XMLHttpRequest(); } else { xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xmlhttp.open("GET","/dom/node.xml",false); xmlhttp.send(); xmlDoc = xmlhttp.responseXML; var y = xmlDoc.getElementsByTagName("Employee")[0]; document.write(y.parentNode.nodeName); </script> </body>
</html>Как видно из приведенного выше примера, дочерний узел Employee переходит к своему родительскому узлу.
Сохраните этот файл как navigate_example.html на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем родительский узел Employee , т. Е. Company .
XML – древовидная структура
XML-документ всегда носит описательный характер. Древовидная структура часто называется XML-деревом и играет важную роль для простого описания любого XML-документа.
Древовидная структура содержит корневые (родительские) элементы, дочерние элементы и так далее. Используя древовидную структуру, вы можете узнать все последующие ветви и дочерние ветви, начиная с корня. Разбор начинается с корня, затем перемещается вниз по первой ветви к элементу, оттуда берется первая ветвь и так далее до конечных узлов.
Syntax
<!DOCTYPE element DTD identifier [ declaration1 declaration2 ........ ]>
In the above syntax,
The DTD starts with <!DOCTYPE delimiter.
An element tells the parser to parse the document from the specified root element.
DTD identifier is an identifier for the document type definition, which may be the path to a file on the system or URL to a file on the internet. If the DTD is pointing to external path, it is called External Subset.
Example
<?xml version = "1.0"?> <Company> <Employee category = "technical"> <FirstName>Tanmay</FirstName> <LastName>Patil</LastName> <ContactNo>1234567890</ContactNo> </Employee> <Employee category = "non-technical"> <FirstName>Taniya</FirstName> <LastName>Mishra</LastName> <ContactNo>1234667898</ContactNo> </Employee> </Company>
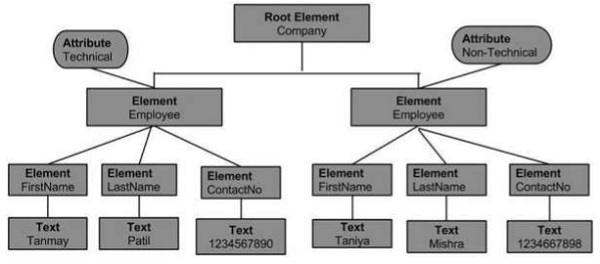
From the above flowchart, we can infer −
Node object can have only one parent node object. This occupies the position above all the nodes. Here it is Company.
The parent node can have multiple nodes called the child nodes. These child nodes can have additional nodes called the attribute nodes. In the above example, we have two attribute nodes Technical and Non-technical. The attribute node is not actually a child of the element node, but is still associated with it.
These child nodes in turn can have multiple child nodes. The text within the nodes is called the text node.
The node objects at the same level are called as siblings.
The DOM identifies −
the objects to represent the interface and manipulate the document.
the relationship among the objects and interfaces.
Создать новый узел комментариев
Метод createComment () создает новый узел комментария. Узел комментариев включен в программу для легкого понимания функциональности кода.
Синтаксис для использования createComment () выглядит следующим образом –
var_name = xmldoc.createComment("tagname");var_name – это имя пользовательской переменной, которая содержит имя нового узла комментария.
(«tagname») – это имя нового узла комментария, который будет создан.
var_name – это имя пользовательской переменной, которая содержит имя нового узла комментария.
(«tagname») – это имя нового узла комментария, который будет создан.
В следующем примере (createcommentnode_example.htm) анализируется документ XML ( node.xml ) в объект DOM XML и создается новый узел комментария «Компания является родительским узлом» в документе XML.
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); create_comment = xmlDoc.createComment("Company is the parent node"); x = xmlDoc.getElementsByTagName("Company")[0]; x.appendChild(create_comment); document.write(x.lastChild.nodeValue); </script> </body>
</html>В приведенном выше примере –
create_comment = xmlDoc.createComment («Компания является родительским узлом») создает указанную строку комментария .
x.appendChild (create_comment) В этой строке ‘x’ содержит имя элемента <Company>, к которому добавляется строка комментария.
create_comment = xmlDoc.createComment («Компания является родительским узлом») создает указанную строку комментария .
x.appendChild (create_comment) В этой строке ‘x’ содержит имя элемента <Company>, к которому добавляется строка комментария.
Сохраните этот файл как createcommentnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение атрибута, так как Company является родительским узлом .
XML — Enabled Database
XML enabled database is nothing but the extension provided for the conversion of XML document. This is a relational database, where data is stored in tables consisting of rows and columns. The tables contain set of records, which in turn consist of fields.
Native XML Database
Native XML database is based on the container rather than table format. It can store large amount of XML document and data. Native XML database is queried by the XPath-expressions.
Native XML database has an advantage over the XML-enabled database. It is highly capable to store, query and maintain the XML document than XML-enabled database.
Example
<?xml version = "1.0"?> <contact-info> <contact1> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact1> <contact2> <name>Manisha Patil</name> <company>TutorialsPoint</company> <phone>(011) 789-4567</phone> </contact2> </contact-info>
Here, a table of contacts is created that holds the records of contacts (contact1 and contact2), which in turn consists of three entities − name, company and phone.
XML DOM — Accessing
In this chapter, we will study about how to access the XML DOM nodes which are considered as the informational units of the XML document. The node structure of the XML DOM allows the developer to navigate around the tree looking for specific information and simultaneously access the information.
XML – декларация
Эта глава подробно описывает декларацию XML. Объявление XML содержит детали, которые подготавливают процессор XML к анализу документа XML. Это необязательно, но при использовании он должен отображаться в первой строке документа XML.
ДОМ – Элемент Объект
Элементы XML могут быть определены как строительные блоки XML. Элементы могут вести себя как контейнеры для хранения текста, элементов, атрибутов, объектов мультимедиа или всего этого. Всякий раз, когда синтаксический анализатор анализирует документ XML на предмет корректности, анализатор перемещается по узлу элемента. Узел элемента содержит текст внутри него, который называется текстовым узлом.
Объект элемента наследует свойства и методы объекта Node, так как объект элемента также рассматривается как Node. Помимо свойств и методов объекта узла, он имеет следующие свойства и методы.
Node Types
We have listed the node types as below −
- ELEMENT_NODE
- ATTRIBUTE_NODE
- ENTITY_NODE
- ENTITY_REFERENCE_NODE
- DOCUMENT_FRAGMENT_NODE
- TEXT_NODE
- CDATA_SECTION_NODE
- COMMENT_NODE
- PROCESSING_INSTRUCTION_NODE
- DOCUMENT_NODE
- DOCUMENT_TYPE_NODE
- NOTATION_NODE
Internal DTD
A DTD is referred to as an internal DTD if elements are declared within the XML files. To refer it as internal DTD, standalone attribute in XML declaration must be set to yes. This means, the declaration works independent of an external source.
Syntax
<!DOCTYPE root-element [element-declarations]>
where root-element is the name of root element and element-declarations is where you declare the elements.
Example
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
Let us go through the above code −
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
<!DOCTYPE address [
The DOCTYPE declaration has an exclamation mark (!) at the start of the element name. The DOCTYPE informs the parser that a DTD is associated with this XML document.
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone_no (#PCDATA)>
Several elements are declared here that make up the vocabulary of the <name> document. <!ELEMENT name (#PCDATA)> defines the element name to be of type «#PCDATA». Here #PCDATA means parse-able text data.
Rules
The document type declaration must appear at the start of the document (preceded only by the XML header) − it is not permitted anywhere else within the document.
Similar to the DOCTYPE declaration, the element declarations must start with an exclamation mark.
The Name in the document type declaration must match the element type of the root element.
Accessing Nodes
By using the getElementsByTagName () method
By looping through or traversing through nodes tree
By navigating the node tree, using the node relationships
XML – Кодировка
Кодирование – это процесс преобразования символов Юникода в их эквивалентное двоичное представление. Когда процессор XML читает документ XML, он кодирует документ в зависимости от типа кодировки. Следовательно, нам нужно указать тип кодировки в декларации XML.
Encoding Types
There are mainly two types of encoding −
- UTF-8
- UTF-16
UTF stands for UCS Transformation Format, and UCS itself means Universal Character Set. The number 8 or 16 refers to the number of bits used to represent a character. They are either 8(1 to 4 bytes) or 16(2 or 4 bytes). For the documents without encoding information, UTF-8 is set by default.
XML DOM – узел клонирования
В этой главе мы обсудим операцию узла клонирования на объекте XML DOM. Операция клонирования узла используется для создания дубликата копии указанного узла. cloneNode () используется для этой операции.
What is Markup?
XML is a markup language that defines set of rules for encoding documents in a format that is both human-readable and machine-readable. So what exactly is a markup language? Markup is information added to a document that enhances its meaning in certain ways, in that it identifies the parts and how they relate to each other. More specifically, a markup language is a set of symbols that can be placed in the text of a document to demarcate and label the parts of that document.
<message> <text>Hello, world!</text> </message>
XML – WhiteSpaces
В этой главе мы обсудим обработку пробелов в документах XML. Пробелы – это набор пробелов, вкладок и новых строк. Они обычно используются, чтобы сделать документ более читабельным.
XML-документ содержит два типа пробелов – значимые пробелы и незначимые пробелы. Оба объяснены ниже с примерами.
Syntax
<!--Your comment-->
A comment starts with <!— and ends with —>. You can add textual notes as comments between the characters. You must not nest one comment inside the other.
Example
<?xml version = "1.0" encoding = "UTF-8" ?> <!--Students grades are uploaded by months--> <class_list> <student> <name>Tanmay</name> <grade>A</grade> </student> </class_list>
Any text between <!— and —> characters is considered as a comment.
DOM – объект NamedNodeMap
Объект NamedNodeMap используется для представления коллекций узлов, к которым можно получить доступ по имени.
XML DOM — Model
Document − Element (maximum of one), ProcessingInstruction, Comment, DocumentType (maximum of one)
DocumentFragment − Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
EntityReference − Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
Element − Element, Text, Comment, ProcessingInstruction, CDATASection, EntityReference
Attr − Text, EntityReference
ProcessingInstruction − No children
Comment − No children
Text − No children
CDATASection − No children
Entity − Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
Notation − No children
Example
error.xml contents are as below −
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <Company id = "companyid"> <Employee category = "Technical" id = "firstelement" type = "text/html"> <FirstName>Tanmay</first> <LastName>Patil</LastName> <ContactNo>1234567890</ContactNo> <Email>tanmaypatil@xyz.com</Email> </Employee> </Company>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> try { xmlDoc = loadXMLDoc("/dom/error.xml"); var node = xmlDoc.getElementsByTagName("to").item(0); var refnode = node.nextSibling; var newnode = xmlDoc.createTextNode('That is why you fail.'); node.insertBefore(newnode, refnode); } catch(err) { document.write(err.name); } </script> </body>
</html>XML – Базы данных
База данных XML используется для хранения огромного количества информации в формате XML. Поскольку использование XML увеличивается во всех областях, требуется безопасное место для хранения документов XML. Данные, хранящиеся в базе данных, можно запросить с помощью XQuery , сериализовать и экспортировать в желаемый формат.
Правильно оформленный XML-документ
Говорят, что документ XML правильно сформирован, если он придерживается следующих правил:
XML-файлы без DTD должны использовать предопределенные символьные объекты для amp (&) , apos (одинарная кавычка) , gt (>) , lt (<) , quot (двойная кавычка) .
Он должен следовать порядку тега. т.е. внутренний тег должен быть закрыт до закрытия внешнего тега.
Он должен иметь только один атрибут в стартовом теге, который должен быть заключен в кавычки.
Объекты amp (&) , apos (одинарные кавычки) , gt (>) , lt (<) , quot (двойные кавычки) должны быть объявлены.
XML-файлы без DTD должны использовать предопределенные символьные объекты для amp (&) , apos (одинарная кавычка) , gt (>) , lt (<) , quot (двойная кавычка) .
Он должен следовать порядку тега. т.е. внутренний тег должен быть закрыт до закрытия внешнего тега.
Он должен иметь только один атрибут в стартовом теге, который должен быть заключен в кавычки.
Объекты amp (&) , apos (одинарные кавычки) , gt (>) , lt (<) , quot (двойные кавычки) должны быть объявлены.
Ниже приведен пример правильно сформированного документа XML:
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
Говорят, что приведенный выше пример хорошо сформирован как –
Он определяет тип документа. Здесь тип документа – тип элемента .
Он включает в себя корневой элемент с именем как адрес .
Каждый из дочерних элементов, таких как имя, компания и телефон, заключен в понятный тег.
Порядок тегов поддерживается.
Он определяет тип документа. Здесь тип документа – тип элемента .
Он включает в себя корневой элемент с именем как адрес .
Каждый из дочерних элементов, таких как имя, компания и телефон, заключен в понятный тег.
Порядок тегов поддерживается.
InsertData()
The method insertData(), inserts a string at the specified 16-bit unit offset.
Syntax
void insertData(int offset, java.lang.String arg) throws DOMException
offset − is the character offset at which to insert.
arg − is the key word to insert the data. It encloses the two parameters offset and string within the parenthesis separated by comma.
Example
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); x = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0]; document.write(x.nodeValue); x.insertData(6,"MiddleName"); document.write("<br>"); document.write(x.nodeValue); </script> </body>
</html>x.insertData(6,»MiddleName»); − Here, x holds the name of the specified child name, i.e, <FirstName>. We then insert to this text node the data «MiddleName» starting from position 6.
Execution
Tanmay TanmayMiddleName
XML — Processors
When a software program reads an XML document and takes actions accordingly, this is called processing the XML. Any program that can read and process XML documents is known as an XML processor. An XML processor reads the XML file and turns it into in-memory structures that the rest of the program can access.
The most fundamental XML processor reads an XML document and converts it into an internal representation for other programs or subroutines to use. This is called a parser, and it is an important component of every XML processing program.
Processor involves processing the instructions, that can be studied in the chapter Processing Instruction.
Example
<!DOCTYPE html>
<html> <style> table,th,td { border:1px solid black; border-collapse:collapse } </style> <body> <div id = "ajax_xml"></div> <script> //if browser supports XMLHttpRequest if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object. code for IE7+, Firefox, Chrome, Opera, Safari var xmlhttp = new XMLHttpRequest(); } else {// code for IE6, IE5 var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } // sets and sends the request for calling "node.xml" xmlhttp.open("GET","/dom/node.xml",false); xmlhttp.send(); // sets and returns the content as XML DOM var xml_dom = xmlhttp.responseXML; // this variable stores the code of the html table var html_tab = '<table id = "id_tabel" align = "center"> <tr> <th>Employee Category</th> <th>FirstName</th> <th>LastName</th> <th>ContactNo</th> <th>Email</th> </tr>'; var arr_employees = xml_dom.getElementsByTagName("Employee"); // traverses the "arr_employees" array for(var i = 0; i<arr_employees.length; i++) { var employee_cat = arr_employees[i].getAttribute('category'); // gets the value of 'category' element of current "Element" tag // gets the value of first child-node of 'FirstName' // element of current "Employee" tag var employee_firstName = arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue; // gets the value of first child-node of 'LastName' // element of current "Employee" tag var employee_lastName = arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue; // gets the value of first child-node of 'ContactNo' // element of current "Employee" tag var employee_contactno = arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue; // gets the value of first child-node of 'Email' // element of current "Employee" tag var employee_email = arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue; // adds the values in the html table html_tab += '<tr> <td>'+ employee_cat+ '</td> <td>'+ employee_firstName+ '</td> <td>'+ employee_lastName+ '</td> <td>'+ employee_contactno+ '</td> <td>'+ employee_email+ '</td> </tr>'; } html_tab += '</table>'; // adds the html table in a html tag, with id = "ajax_xml" document.getElementById('ajax_xml').innerHTML = html_tab; </script> </body>
</html>This code loads node.xml.
The XML content is transformed into JavaScript XML DOM object.
The array of elements (with tag Element) using the method getElementsByTagName() is obtained.
Next, we traverse through this array and display the child node values in a table.
Parser
In a tree-based API like DOM, the parser traverses the XML file and creates the corresponding DOM objects. Then you can traverse the DOM structure back and forth.
DOM – Объект DOMImplementation
Объект DOMImplementation предоставляет ряд методов для выполнения операций, которые не зависят от какого-либо конкретного экземпляра объектной модели документа.
Firefox Browser
Open the above XML code in Chrome by double-clicking the file. The XML code displays
coding with color, which makes the code readable. It shows plus(+) or minus (-) sign at
the left side in the XML element. When we click the minus sign (-), the code hides. When
we click the plus (+) sign, the code lines get expanded. The output in Firefox is as shown below −

XML DOM – обход
В этой главе мы обсудим XML DOM Traversing. В предыдущей главе мы изучали, как загружать XML-документ и анализировать полученный таким образом объект DOM. Этот проанализированный объект DOM может быть пройден. Обход – это процесс, в котором зацикливание выполняется систематическим образом, проходя каждый элемент поэтапно в дереве узлов.
Well-formed XML Document
Non DTD XML files must use the predefined character entities for amp(&), apos(single quote), gt(>), lt(<), quot(double quote).
It must have only one attribute in a start tag, which needs to be quoted.
amp(&), apos(single quote), gt(>), lt(<), quot(double quote) entities other than these must be declared.
Example
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
The above example is said to be well-formed as −
It defines the type of document. Here, the document type is element type.
It includes a root element named as address.
Each of the child elements among name, company and phone is enclosed in its self explanatory tag.
Order of the tags is maintained.
RemoveAttribute()
The method removeAttribute() removes an attribute of an element by name.
Syntax
void removeAttribute(java.lang.String name) throws DOMException
name − is the name of the attribute to remove.
Example
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); x = xmlDoc.getElementsByTagName('Employee'); document.write(x[1].getAttribute('category')); document.write("<br>"); x[1].removeAttribute('category'); document.write(x[1].getAttribute('category')); </script> </body>
</html>In the above example −
Execution
Non-Technical null
XML Comments Rules
- Comments cannot appear before XML declaration.
- Comments may appear anywhere in a document.
- Comments must not appear within attribute values.
- Comments cannot be nested inside the other comments.
XML Database Types
There are two major types of XML databases −
- XML- enabled
- Native XML (NXD)
External DTD
In external DTD elements are declared outside the XML file. They are accessed by specifying the system attributes which may be either the legal .dtd file or a valid URL. To refer it as external DTD, standalone attribute in the XML declaration must be set as no. This means, declaration includes information from the external source.
Syntax
<!DOCTYPE root-element SYSTEM "file-name">
where file-name is the file with .dtd extension.
Example
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <!DOCTYPE address SYSTEM "address.dtd"> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
The content of the DTD file address.dtd is as shown −
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)>
XML – пространства имен
Пространство имен – это набор уникальных имен. Пространство имен – это механизм, с помощью которого элемент и имя атрибута могут быть назначены группе. Пространство имен идентифицируется URI (унифицированными идентификаторами ресурса).
XML – парсеры
Анализатор XML – это программная библиотека или пакет, который предоставляет интерфейс для клиентских приложений для работы с документами XML. Он проверяет правильный формат документа XML, а также может проверять документы XML. Современные браузеры имеют встроенные парсеры XML.
Следующая диаграмма показывает, как синтаксический анализатор XML взаимодействует с документом XML:

Цель парсера – преобразовать XML в читаемый код.
Чтобы упростить процесс синтаксического анализа, доступны некоторые коммерческие продукты, которые облегчают разбивку XML-документа и дают более надежные результаты.
Некоторые часто используемые парсеры перечислены ниже –
MSXML (Microsoft Core XML Services) – это стандартный набор инструментов XML от Microsoft, который включает в себя анализатор.
System.Xml.XmlDocument – этот класс является частью библиотеки .NET, которая содержит ряд различных классов, связанных с работой с XML.
Встроенный синтаксический анализатор Java – Библиотека Java имеет свой собственный анализатор. Библиотека спроектирована таким образом, что вы можете заменить встроенный парсер на внешнюю реализацию, такую как Xerces от Apache или Saxon.
Saxon – Saxon предлагает инструменты для синтаксического анализа, преобразования и запроса XML.
Xerces – Xerces реализован на Java и разработан известным Apache Software Foundation с открытым исходным кодом.
MSXML (Microsoft Core XML Services) – это стандартный набор инструментов XML от Microsoft, который включает в себя анализатор.
System.Xml.XmlDocument – этот класс является частью библиотеки .NET, которая содержит ряд различных классов, связанных с работой с XML.
Встроенный синтаксический анализатор Java – Библиотека Java имеет свой собственный анализатор. Библиотека спроектирована таким образом, что вы можете заменить встроенный парсер на внешнюю реализацию, такую как Xerces от Apache или Saxon.
Saxon – Saxon предлагает инструменты для синтаксического анализа, преобразования и запроса XML.
Xerces – Xerces реализован на Java и разработан известным Apache Software Foundation с открытым исходным кодом.
Изменить значение узла атрибута
В следующем примере показано, как изменить узел атрибута элемента.
<!DOCTYPE html>
<html> <head> <script> function loadXMLDoc(filename) { if (window.XMLHttpRequest) { xhttp = new XMLHttpRequest(); } else // code for IE5 and IE6 { xhttp = new ActiveXObject("Microsoft.XMLHTTP"); } xhttp.open("GET",filename,false); xhttp.send(); return xhttp.responseXML; } </script> </head> <body> <script> xmlDoc = loadXMLDoc("/dom/node.xml"); x = xmlDoc.getElementsByTagName("Employee"); for(i = 0 ;i<x.length;i++){ newcategory = x[i].getAttributeNode('category'); newcategory.nodeValue = "admin-"+i; document.write(i+'); document.write(x[i].getAttributeNode('category').nodeValue); document.write('<br>'); } </script> </body>
</html>Сохраните этот файл как set_node_attribute_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Результат будет следующим:
0) admin-0 1) admin-1 2) admin-2
XML – редакторы
XML Editor – это редактор языка разметки. Документы XML можно редактировать или создавать с использованием существующих редакторов, таких как Блокнот, WordPad или любой аналогичный текстовый редактор. Вы также можете найти профессиональный XML-редактор онлайн или для скачивания, который имеет более мощные функции редактирования, такие как –
- Он автоматически закрывает оставленные теги открытыми.
- Он строго проверяет синтаксис.
- Он выделяет синтаксис XML цветом для повышения читабельности.
- Это поможет вам написать правильный код XML.
- Он обеспечивает автоматическую проверку документов XML по DTD и схемам.
XML — Elements
Each XML document contains one or more elements, the scope of which are either delimited by start and end tags, or for empty elements, by an empty-element tag.
Types of Character Entities
There are three types of character entities −
- Predefined Character Entities
- Numbered Character Entities
- Named Character Entities
Predefined Character Entities
Ampersand − &
Single quote − '
Less than − <
Double quote − "
Numeric Character Entities
The numeric reference is used to refer to a character entity. Numeric reference can either be in decimal or hexadecimal format. As there are thousands of numeric references available, these are a bit hard to remember. Numeric reference refers to the character by its number in the Unicode character set.
General syntax for decimal numeric reference is −
&# decimal number ;
General syntax for hexadecimal numeric reference is −
&#x Hexadecimal number ;
Named Character Entity
As it is hard to remember the numeric characters, the most preferred type of character
entity is the named character entity. Here, each entity is identified with a name.
For example −
‘Aacute’ represents capital
 character with acute accent.
character with acute accent.‘ugrave’ represents the small
 with grave accent.
with grave accent.
")




")