
I don’t like that you’ve defined your interface to BinarySearchTree in terms of TreeNodes. By allowing TreeNodes to be passed into and returned from the class, your allow clients to manipulate your tree from the outside. What happens if your supplied root node has the left and right branches supplied the wrong way round? What happens if the caller nulls out the parent pointer in the node returned from insert? If you want to provide a method for clients to iterate over the tree, provide an iterator, this question and its feedback might be a good starting point.
You tree doesn’t supply a default constructor. Given the interface, I’d assume that if I pass in NULL as the root, the class would sort itself out. It doesn’t, it sets the root to NULL and from that point it silently ignores anything I try to insert in the tree. It would be better to throw an exception to indicate that it isn’t supported functionality.
Bug deleting root
When you delete a node you update links, via the parent pointer. If you’re deleting the root node, the parent pointer is null. For example, if you delete the root node of a tree that only has children on the right, you run this code:
boolean isLeftChild = (toDelete.parent.left == toDelete);This crashes, since toDelete(root).parent is null.
First, what is a tree data structure and what is it used for? A tree is, in layman’s terms, a collection of nodes (items) that are connected to each other in such a way that no cycles (circular relationships) are allowed. Examples abound in organization charts, family trees, biological taxonomies, and so forth. Trees are incredibly useful structures because they allow us to represent hierarchies and to compose complex structures out of basic parts and simple relationships. In the world of programming specifically, this provides a mechanism for extensibility across many domains, and a container to assist us in searching, sorting, compressing, and otherwise processing data in efficient and sophisticated ways. Trees are also a natural fit for use in the composite design pattern, where a group of objects can be treated (or processed) like a single object.
Just as it’s possible to implement recursive algorithms non-recursively, it’s also possible to create non-hierarchical data structures to store data that would more logically be stored in a tree. In these cases, your code is typically much more clear when organized in a tree, leading to greater maintainability and refactorability. Recursion itself, while not exceptionally common in every day programming tasks, plays a more important role in some interesting ways with trees and traversal patterns. Traversal is the term used to describe how nodes in a tree are visited. Later I’ll demonstrate some tree traversal techniques that you can use.
I am reading Binary Trees. while practicing coding problems I came across some solutions where it is asked to find Min Depth of Binary Tree.
Now as per my understanding depth is no of edges from root to node (leaf node in case of leaf nodes / binary tree)
As per my solution it should be 1.
asked Jun 17, 2014 at 7:11

My tested solution
public int minDepth(TreeNode root) { if(root == null){ return 0; } int ldepth = minDepth(root.left); int rdepth = minDepth(root.right); if(ldepth == 0){ return 1+rdepth; }else if(rdepth == 0){ return 1+ldepth; } return (1 + Math.min(rdepth, ldepth));
}Here, we calculate ldepth (minimum left subtree depth) and rdepth (minimum right subtree depth) for a node. Then, if ldepth is zero but rdepth is not, that means current node is not a leaf node, so return 1 + rdepth. If both rdepth and ldepth are zeros then still ‘if’ condition works as we return 1+0 for current leaf node.
Similar logic for ‘else if’ branch. In ‘return’ statement as both ‘if’ conditions has been failed we return 1 (current node) + minimum value of recursive calls to both left and right branch.
answered Feb 5, 2016 at 3:51

Rajesh Surana
1 gold badge10 silver badges15 bronze badges
Remember a leaf node has neither left nor right child.
1 / /
2so here 2 is the leaf node but 1 is not. so minimum depth for this case is 2 assuming depth of root node is 1.
#include<vector>
#include<iostream>
#include<climits>
using namespace std; struct TreeNode { int val; TreeNode *left; TreeNode *right; TreeNode(int x) : val(x), left(NULL), right(NULL) {} };
class Solution {
public: int minDepth(TreeNode *root) { if(root == NULL) return 0; return getDepth(root); } int getDepth(TreeNode *r ){ if(r == NULL) return INT_MAX; if(r->left == NULL && r->right == NULL) return 1; return 1+ min(getDepth(r->left), getDepth(r->right)); }
};answered Sep 16, 2014 at 15:22

1 gold badge21 silver badges20 bronze badges
A root node will have a depth of 0, so here depth of the given tree will be 1, refer below recursion and iterative solution to find min dept of binary tree.
Recursive solution :
public static int findMinDepth(BTNode root) { if (root == null || (root.getLeft() == null && root.getRight() == null)) { return 0; } int ldepth = findMinDepth(root.getLeft()); int rdepth = findMinDepth(root.getRight()); return (Math.min(rdepth + 1, ldepth + 1));
}Iterative solution :
public static int minDepth(BTNode root) { int minDepth = Integer.MAX_VALUE; Stack<BTNode> nodes = new Stack<>(); Stack<BTNode> path = new Stack<>(); if (root == null) { return -1; } nodes.push(root); while (!nodes.empty()) { BTNode node = nodes.peek(); if (!path.empty() && node == path.peek()) { if (node.getLeft() == null && node.getRight() == null && path.size() <= minDepth) { minDepth = path.size() - 1; } path.pop(); nodes.pop(); } else { path.push(node); if (node.getRight() != null) { nodes.push(node.getRight()); } if (node.getLeft() != null) { nodes.push(node.getLeft()); } } } return minDepth;
}answered Jan 4, 2018 at 16:12

The depth o a binary tree is the length of the longest route from the root to the leaf. In my opinion the depth should be 2.
answered Sep 16, 2014 at 15:34

3 silver badges13 bronze badges
public int minDepth(TreeNode root){ if(root==null) return 0; else if(root.left==null && root.right==null) return 1; else if(root.left==null) return 1+minDepth(root.right); else if(root.right==null) return 1+minDepth(root.left); else return 1+Math.min(minDepth(root.right), minDepth(root.left)); }answered Feb 20, 2016 at 9:23

Here’s an iterative answer (in C#) (Rajesh Surana answer is a good Recusive answer):
public static int FindMinDepth<T>(BinarySearchTree<T> tree) where T : IComparable<T>
{ var current = tree._root; int level = 0; Queue<BSTNode<T>> q = new Queue<BSTNode<T>>(); if (current != null) q.Enqueue(current); while (q.Count > 0) { level++; Queue<BSTNode<T>> nq = new Queue<BSTNode<T>>(); foreach (var element in q) { if (element.Left == null && element.Right == null) return level; if (element.Left != null) nq.Enqueue(element.Left); if (element.Right != null) nq.Enqueue(element.Right); } q = nq; } return 0; //throw new Exception("Min Depth not found!");
}answered Mar 23, 2018 at 9:28

Maverick Meerkat
3 gold badges46 silver badges65 bronze badges
Here’s a very versatile tree printer. Not the best looking, but it handles a lot of cases. Feel free to add slashes if you can figure that out.

package com.tomac120.NodePrinter;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/** * Created by elijah on 6/28/16. */
public class NodePrinter{ final private List<List<PrintableNodePosition>> nodesByRow; int maxColumnsLeft = 0; int maxColumnsRight = 0; int maxTitleLength = 0; String sep = " "; int depth = 0; public NodePrinter(PrintableNode rootNode, int chars_per_node){ this.setDepth(rootNode,1); nodesByRow = new ArrayList<>(depth); this.addNode(rootNode._getPrintableNodeInfo(),0,0); for (int i = 0;i<chars_per_node;i++){ //sep += " "; } } private void setDepth(PrintableNode info, int depth){ if (depth > this.depth){ this.depth = depth; } if (info._getLeftChild() != null){ this.setDepth(info._getLeftChild(),depth+1); } if (info._getRightChild() != null){ this.setDepth(info._getRightChild(),depth+1); } } private void addNode(PrintableNodeInfo node, int level, int position){ if (position < 0 && -position > maxColumnsLeft){ maxColumnsLeft = -position; } if (position > 0 && position > maxColumnsRight){ maxColumnsRight = position; } if (node.getTitleLength() > maxTitleLength){ maxTitleLength = node.getTitleLength(); } List<PrintableNodePosition> row = this.getRow(level); row.add(new PrintableNodePosition(node, level, position)); level++; int depthToUse = Math.min(depth,6); int levelToUse = Math.min(level,6); int offset = depthToUse - levelToUse-1; offset = (int)(Math.pow(offset,Math.log(depthToUse)*1.4)); offset = Math.max(offset,3); PrintableNodeInfo leftChild = node.getLeftChildInfo(); PrintableNodeInfo rightChild = node.getRightChildInfo(); if (leftChild != null){ this.addNode(leftChild,level,position-offset); } if (rightChild != null){ this.addNode(rightChild,level,position+offset); } } private List<PrintableNodePosition> getRow(int row){ if (row > nodesByRow.size() - 1){ nodesByRow.add(new LinkedList<>()); } return nodesByRow.get(row); } public void print(){ int max_chars = this.maxColumnsLeft+maxColumnsRight+1; int level = 0; String node_format = "%-"+this.maxTitleLength+"s"; for (List<PrintableNodePosition> pos_arr : this.nodesByRow){ String[] chars = this.getCharactersArray(pos_arr,max_chars); String line = ""; int empty_chars = 0; for (int i=0;i<chars.length+1;i++){ String value_i = i < chars.length ? chars[i]:null; if (chars.length + 1 == i || value_i != null){ if (empty_chars > 0) { System.out.print(String.format("%-" + empty_chars + "s", " ")); } if (value_i != null){ System.out.print(String.format(node_format,value_i)); empty_chars = -1; } else{ empty_chars = 0; } } else { empty_chars++; } } System.out.print("\n"); int depthToUse = Math.min(6,depth); int line_offset = depthToUse - level; line_offset *= 0.5; line_offset = Math.max(0,line_offset); for (int i=0;i<line_offset;i++){ System.out.println(""); } level++; } } private String[] getCharactersArray(List<PrintableNodePosition> nodes, int max_chars){ String[] positions = new String[max_chars+1]; for (PrintableNodePosition a : nodes){ int pos_i = maxColumnsLeft + a.column; String title_i = a.nodeInfo.getTitleFormatted(this.maxTitleLength); positions[pos_i] = title_i; } return positions; }
}package com.tomac120.NodePrinter;
/** * Created by elijah on 6/28/16. */
public class PrintableNodeInfo { public enum CLI_PRINT_COLOR { RESET("\u001B[0m"), BLACK("\u001B[30m"), RED("\u001B[31m"), GREEN("\u001B[32m"), YELLOW("\u001B[33m"), BLUE("\u001B[34m"), PURPLE("\u001B[35m"), CYAN("\u001B[36m"), WHITE("\u001B[37m"); final String value; CLI_PRINT_COLOR(String value){ this.value = value; } @Override public String toString() { return value; } } private final String title; private final PrintableNode leftChild; private final PrintableNode rightChild; private final CLI_PRINT_COLOR textColor; public PrintableNodeInfo(String title, PrintableNode leftChild, PrintableNode rightChild){ this(title,leftChild,rightChild,CLI_PRINT_COLOR.BLACK); } public PrintableNodeInfo(String title, PrintableNode leftChild, PrintableNode righthild, CLI_PRINT_COLOR textColor){ this.title = title; this.leftChild = leftChild; this.rightChild = righthild; this.textColor = textColor; } public String getTitle(){ return title; } public CLI_PRINT_COLOR getTextColor(){ return textColor; } public String getTitleFormatted(int max_chars){ return this.textColor+title+CLI_PRINT_COLOR.RESET; /* String title = this.title.length() > max_chars ? this.title.substring(0,max_chars+1):this.title; boolean left = true; while(title.length() < max_chars){ if (left){ title = " "+title; } else { title = title + " "; } } return this.textColor+title+CLI_PRINT_COLOR.RESET;*/ } public int getTitleLength(){ return title.length(); } public PrintableNodeInfo getLeftChildInfo(){ if (leftChild == null){ return null; } return leftChild._getPrintableNodeInfo(); } public PrintableNodeInfo getRightChildInfo(){ if (rightChild == null){ return null; } return rightChild._getPrintableNodeInfo(); }
}package com.tomac120.NodePrinter;
/** * Created by elijah on 6/28/16. */
public class PrintableNodePosition implements Comparable<PrintableNodePosition> { public final int row; public final int column; public final PrintableNodeInfo nodeInfo; public PrintableNodePosition(PrintableNodeInfo nodeInfo, int row, int column){ this.row = row; this.column = column; this.nodeInfo = nodeInfo; } @Override public int compareTo(PrintableNodePosition o) { return Integer.compare(this.column,o.column); }
}And, finally, Node Interface
package com.tomac120.NodePrinter;
/** * Created by elijah on 6/28/16. */
public interface PrintableNode { PrintableNodeInfo _getPrintableNodeInfo(); PrintableNode _getLeftChild(); PrintableNode _getRightChild();
}This is a question that comes quite often as a preliminary / phone interview question. How do we check if a binary tree is a BST in Java? In other words we need to validate if a binary tree is a binary search tree.
As for our previous topic for checking whether a tree is balanced, the first step is to properly define the problem. So let us define what does it mean for a binary tree to be a BST.
As This Excellent Article defines:
Binary Search tree is a binary tree in which each internal node x stores an element such that the element stored in the left subtree of x are less than or equal to x and elements stored in the right subtree of x are greater than or equal to x.
Given this definition we can try to visualize it. Note that not only the current node needs to be bigger than the its left child. It needs to be bigger than the whole left subtree. The same goes for the right child. After careful evaluation of the definition we should come up with something like this to visualize a binary tree that is a BST.

Hence we completed the first step by having a definition and a visualization for our problem. Now all we have to do is methodically devise a step by step algorithm to validate that a binary tree is indeed a BST.
- Check if a binary tree is a BST in Java – Algorithm Idea
- Check if a binary tree is a BST in Java – Recursive Algorithm – Bottom Up
- Check if a binary tree is a BST in Java – Recursive Implementation – Bottom Up
- Check if a binary tree is a BST in Java – Recursive Algorithm – Top to bottom
- Check if a binary tree is a BST in Java – Recursive Implementation – Top to bottom
- Check if a binary tree is a BST in Java – In-Order-Traversal Algorithm
- Check if a binary tree is a BST in Java – In-Order-Traversal Implementation
- Code implementation
- Problem solving ideas
- The second smallest node in a binary tree
- Builder
- Code implementation
- Proposed Solution
- Simplify get
- Breadth-first search
- Depth-first search
- TreeNode
- Unit testing
- Formatting
- Code implementation
- JavaScript Solution
- Lexicon
- Problem solving ideas
- The Tree Node Payload’s Awareness of its Place in the Tree
- Data Integrity
- Connecting Nodes to Their Parents & Children
- Cleaning Up
- Code implementation
- Binary vs. Non-Binary Trees
- Trees with similar leaves
- Layer average of binary tree
- Drawing analysis
- Problem solving ideas
- The Tree Node
- Drawing analysis
- Drawing analysis
- Review
- The Role of Generics in Representing Payloads
- Including Structure Helper Members
- Merging binary trees
- Defining the Basic Components
- Examples of Non-Binary Trees
- Problem solving ideas
- Navigation
- Begin with the End in Mind
- Conclusion
Check if a binary tree is a BST in Java – Algorithm Idea
- The left sub-tree of a node contains only nodes with values less than the node’s value.
- The right sub-tree of a node contains only nodes with values greater than the node’s value.
Note that by the definition and algorithm idea above, a null pointer would be considered as a BST, since it does not break the validation. Since we are checking each sub-tree in the tree, this can be easily be implemented as a recursive call.
Check if a binary tree is a BST in Java – Recursive Algorithm – Bottom Up
- Check if left sub-tree is a BST. Get the max value of the left subtree.
- Check if right sub-tree is a BST. Get the min value of the right subtree.
- Validate that the current node’s value is bigger than the max value of the left subtree and smaller than the min value of the right subtree.
If you rationalized everything as I did until now, the above algorithm should come naturally. You need to know min and max and validate that our node’s value is in the middle. If all nodes have this property then we have validated that our binary tree is a BST. We will see in a second how putting this to code will not be as trivial as we would think.
Check if a binary tree is a BST in Java – Recursive Implementation – Bottom Up
That was a bit harder to write than expected, was it not? One of the main problems that come up in the heat of the interview is trying to pass 2 or more variables up to a recursive call. This problem can easily be solved by creating a placeholder class specific to your use case. In fact the above example does exactly that to check if a binary tree is a BST. So keep that in mind for the next time you get stuck at trying to bubble up two or more variables in a tree.
The other way to go around the problem and probably devise a cleaner solution, would be modify the algorithm to validate top-to-bottom instead of bottom up. Meaning we pass our constraints from the top node to the bottom and validate that each node does not cross it’s left and right ancestors min and max. Since we can pass as many arguments as we want to a recursive function, this will be a lot easier to do. Note that this is another way you can re-frame recursive problems!
Check if a binary tree is a BST in Java – Recursive Algorithm – Top to bottom
- Check if left sub-tree is a BST. All nodes values must have an upper bound equal to the current node’s value.
- Check if right sub-tree is a BST. All nodes values must be bigger than the current.
Seems easy enough? After we have clearly specified the algorithm all that is left to do is to put it in code. Given that we have already thought out how it would pan out, it should turn out a lot simpler than our previous attempt.
Check if a binary tree is a BST in Java – Recursive Implementation – Top to bottom
Since it passes constraints from the top to the bottom, the solution above is called a top to bottom approach, while our first approach is commonly called a bottom-up approach.
Now what if your interviewer asks you to come up with yet another algorithm? Digging through your knowledge, you will remember that there are different type of traversals for tree. In fact we have already tried to solve for a rather uncommon Zig-Zag Tree Traversal. However some of the most common ones that one should study, are In-Order, Pre-Order and Post-Order Traversal.
Check out this article to see when to use which and get some idea on how you can get help from each of these algorithms. As you will be able to see, doing an In-Order-Traversal mimics you go from the far left to the far right of the tree, touching nodes one by one. In fact you can envision a vertical line going through the tree from left to right. For our current problem, that means that it will also touch nodes progressively with higher value. It turns out we can use this simple fact to check if a binary tree is a BST.
Check if a binary tree is a BST in Java – In-Order-Traversal Algorithm
- Traverse nodes of the tree inorder.
- Keep make sure every next node value is bigger than the previous one.
Since we did most of our explanation before devising the algorithm, it should be fairly straight forward to put it to code.
Check if a binary tree is a BST in Java – In-Order-Traversal Implementation
We just came up with our third solution to this problem in less than 15 minutes! Pretty great isn’t it! I am sure any interviewer would be impressed with all this and would mark this as a pass to his question.
Last but not least, we can quickly observer that for each of our algorithms we touch each node once and we keep no auxiliary data structures. Hence our Time Complexity is going to be O(n) and our Space Complexity is going to be O(1). If this was obvious to you than you are well on the path to become an algorithm guru!
As always feel free to ask questions or post any feedback!
Hope you guys enjoyed it! And I’ll see you guys next time ;D.

I am solving the problem https://leetcode.com/problems/path-sum-iii/
I’ll also briefly mention it here:
Find the number of paths in a Binary tree whose sum = sum. The path does not necessarily have to begin (end) at the root (leaf). As long as the path goes downward it should be considered as a valid path.
Here is my solution:
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */
public class Solution { public int pathSum(TreeNode root, int sum) { int path = 0; if(root.val == sum) return 1; else if(root.left == null && root.right == null) return 0; if(root.left != null){ path += pathSum(root.left, sum - root.val); path += pathSum(root.left, sum); } if(root.right != null){ path += pathSum(root.right, sum - root.val); path += pathSum(root.right, sum); } return path; }
}root = [10,5,-3,3,2,null,11,3,-2,null,1], sum = 8 10 / \ 5 -3 / \ \ 3 2 11 / \ \
3 -2 1
Return 3. The paths that sum to 8 are:
1. 5 -> 3
2. 5 -> 2 -> 1
3. -3 -> 11I have spent hours trying to reason why my code wold not work, but I cannot figure out the problem.
Sorry for a naive question 🙁 But this is killing me!
asked Dec 23, 2016 at 1:50

I’m not sure what’s wrong in your solution, but I don’t think it’s correct. For one thing, if your root was 8 you would immediately return and count only the root as solution. This is how I would do it:
import java.util.ArrayList;
public class Solution { public static int pathSum(TreeNode root, int sum) { return pathSum(root, sum, 0, new ArrayList<Integer>()); } public static int pathSum(TreeNode root, int sum, int count, ArrayList<Integer> arr) { arr.add(root.val); int acc = 0; for (int i=arr.size()-1; i>=0; i--) { acc += arr.get(i); if (acc == sum) count++; } if(root.left != null) count = pathSum(root.left, sum, count, arr); if(root.right != null) count = pathSum(root.right, sum, count, arr); arr.remove(arr.size()-1); return count; } static class TreeNode { int val; TreeNode left; TreeNode right; public TreeNode(int v) { this.val = v; } } public static void main(String[] args) { TreeNode root = new TreeNode(10); root.left = new TreeNode(5); root.right = new TreeNode(-3); root.left.left = new TreeNode(3); root.left.right = new TreeNode(2); root.right.right = new TreeNode(11); root.left.left.left = new TreeNode(3); root.left.left.right = new TreeNode(-2); root.left.right.right = new TreeNode(1); System.out.println(pathSum(root, 8)); }
}The idea is to populate an aarray with the value along the path as you traverse the tree recursively, making sure you remove elements as you return. When you visit a node, you have to consider all the sums from that node to any node on the path to the root. Any of them can add up to your reference value. This implementation is O(nlogn), as you traverse n nodes, and for each you traverse an array of len up to log(n).
answered Dec 23, 2016 at 2:25
Roberto Attias
1 gold badge11 silver badges21 bronze badges
your code cant satisfy this constraint:
these nodes should be continuous.e.g the root(value 10) of this tree and the leaf(value -2) of this tree, the sum of them is equals 8. but it dont satisfy continous, so It cant count.
Unfortunately, your code cant filter this case.
an alternative Solution:
public class Solution {
public int pathSum(TreeNode root, int sum) { int path = traverse(root,sum); return path;
}
public int traverse(TreeNode root, int sum){ int path = 0; if(root==null){ return 0; } else{ path += calcu(root,sum); path += traverse(root.left,sum); path += traverse(root.right,sum); return path; }
}
private int calcu(TreeNode root, int sum) { if(root==null){ return 0; } else if(root.val==sum){ return 1 + calcu(root.left,sum-root.val)+calcu(root.right,sum-root.val); } else{ return calcu(root.left,sum-root.val)+calcu(root.right,sum-root.val); }
}
}explanation: traverse this tree and make every treeNode as root node, find target path under the premise continous.
answered Dec 23, 2016 at 2:25

nail fei
3 gold badges16 silver badges36 bronze badges
the problem with your solution is that you do not start from an initial sum, if you are in a new inner path.
so you should keep track of both the accomulated sum and the original sum as well when you move inner path.
find below a modified copy of your algorithm.
public static class TreeNode { int val; TreeNode left; TreeNode right; boolean visitedAsRoot = false; TreeNode(int x) { val = x; }
}
public static int pathSum(TreeNode root, int accomulate, int sum) { int path = 0; if (root.val == accomulate) return 1; else if (root.left == null && root.right == null) return 0; if (root.left != null) { path += pathSum(root.left, accomulate - root.val, sum); if (!root.left.visitedAsRoot) { root.left.visitedAsRoot = true; path += pathSum(root.left, sum, sum); } } if (root.right != null) { path += pathSum(root.right, accomulate - root.val, sum); if (!root.right.visitedAsRoot) { root.right.visitedAsRoot = true; path += pathSum(root.right, sum, sum); } } return path;
}
public static void main(String args[]) { TreeNode t1 = new TreeNode(3); TreeNode t2 = new TreeNode(-2); TreeNode t3 = new TreeNode(1); TreeNode t4 = new TreeNode(3); TreeNode t5 = new TreeNode(2); TreeNode t6 = new TreeNode(11); TreeNode t7 = new TreeNode(5); TreeNode t8 = new TreeNode(-3); TreeNode t9 = new TreeNode(10); t4.left = t1; t4.right = t2; t5.right = t3; t7.left = t4; t7.right = t5; t8.right = t6; t9.left = t7; t9.right = t8; System.out.println(pathSum(t9, 8, 8));
}answered Dec 23, 2016 at 2:43

The problem with your solution is that it is also counting 10 — 2 = 8. where 10 is the topmost root node and -2 is a bottom leaf. It ignores all the path in between.
I managed to solve it with a tamperedSum boolean.
public static int pathSum(TreeNode root, int sum, boolean tamperedSum)
{ int path = 0; if(root.val == sum) path = 1; if(root.left == null && root.right == null) return path; if(root.left != null){ path += pathSum(root.left, sum - root.val, true); if (!tamperedSum) path += pathSum(root.left, sum, false); } if(root.right != null){ path += pathSum(root.right, sum - root.val, true); if (!tamperedSum) path += pathSum(root.right, sum, false); } return path;
} The tamperedSum boolean is set to true when we have deducted values (of nodes) from the original sum which in this case is 8.
We would invoke it as:
pathSum(root, sum, false)The idea is that if the sum has been tampered i.e a node value on the path has already been deducted, we are no longer allowed to pass it as-is to the branch below the node.
So, we set tamperedSum to true whenever we deduct the node value from the sum as: sum - root.value. After that, all nodes below it are not allowed to pass through the sum without deducting their node value from it.
answered Dec 23, 2016 at 2:29

Bijay Gurung
8 silver badges12 bronze badges
Code implementation
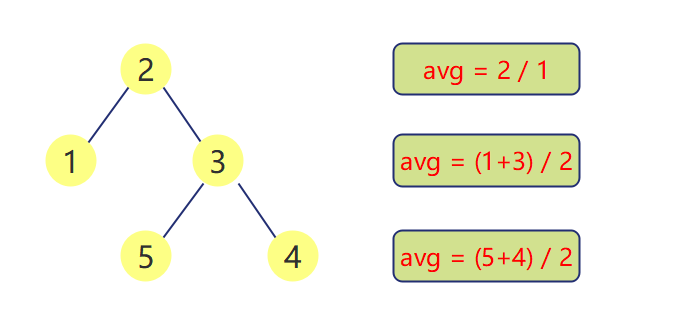
class Solution { public List<Double> averageOfLevels(TreeNode root) { List<Double> list = new ArrayList<>(); if(root == null) return list;//Return directly if it is empty Queue<TreeNode> queue = new LinkedList<>(); queue.offer(root); while (!queue.isEmpty()){ long sum = 0;//Sum is used to represent the sum of each layer int size = queue.size(); int count = size;//count is used to represent the number of elements in each layer while(size != 0){ //When size is empty, it means that this layer has been recorded TreeNode top =queue.poll(); sum += top.val;//Add data to sum every time you leave the team if(top.left != null){ queue.offer(top.left); } if(top.right != null){ queue.offer(top.right); } size--; } //Going out of the loop means the end of each layer, so put the obtained average value into the list list.add(sum / (count*1.0)); } return list; }
}Problem solving ideas
- Using the preorder traversal method, each recursion is stored in the list when the left and right subtrees of root are empty
- The recursion ends, and the list is the leaf node of the tree
- Comparing the list s of two trees, the same is true
The second smallest node in a binary tree
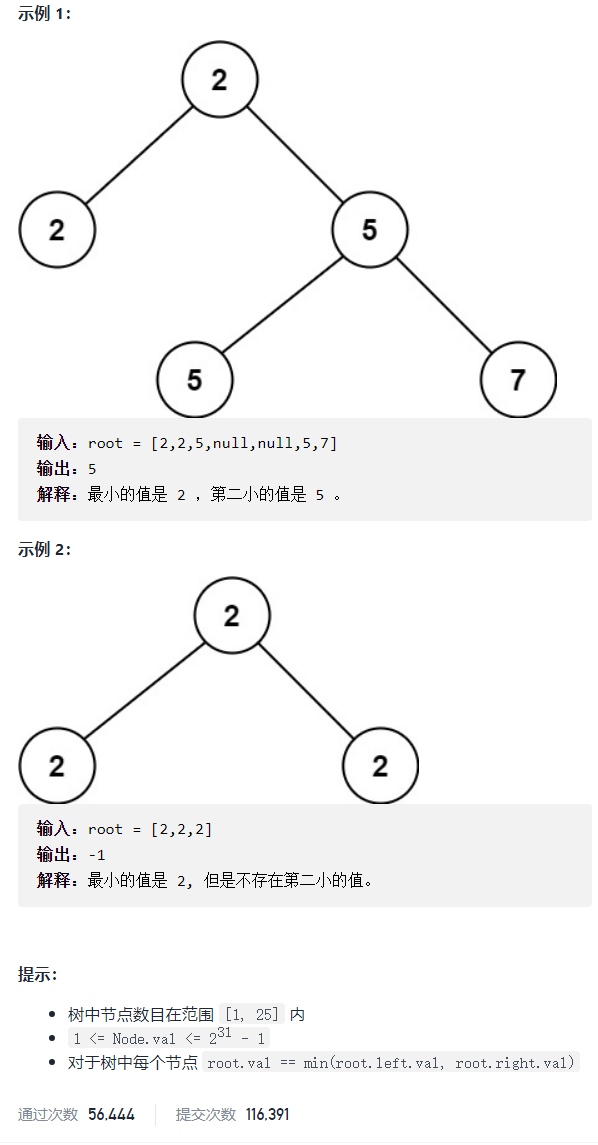
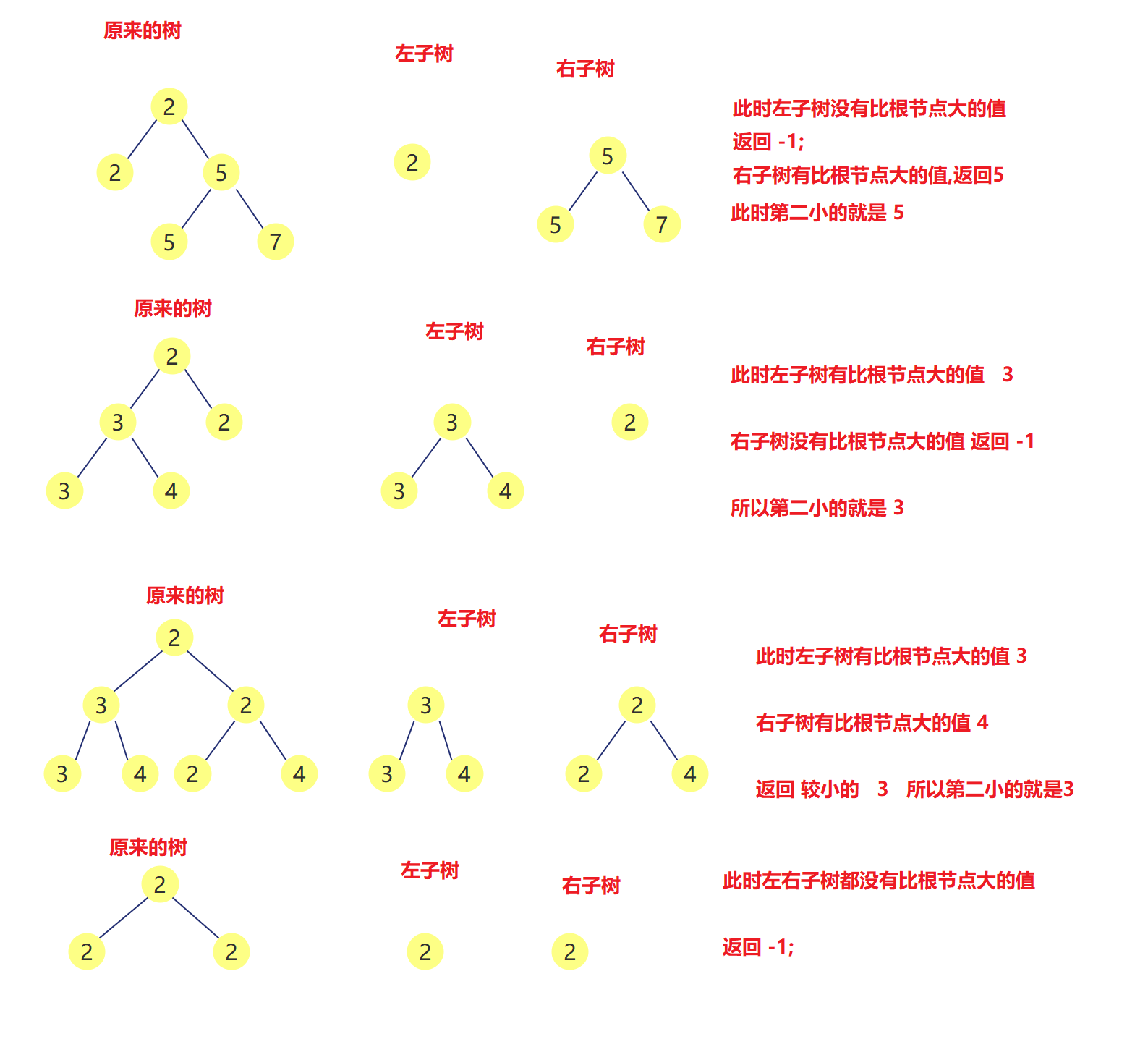
LeetCode 671 : The second smallest node in a binary tree
Description:
Given a non empty special binary tree, each node is a positive number, and the number of child nodes of each node can only be 2 or 0. If a node has two child nodes, the value of the node is equal to the smaller of the two child nodes.
More formally, root Val = min (root.left.val, root. Right. VAL) is always established.
Given such a binary tree, you need to output the second smallest value of all nodes. If the second smallest value does not exist, output — 1.
Builder
I am not convinced an extension method is the way to go for this method. I would rather make a Builder class for it, but that’s probably a matter of taste.
public static Tree BuildTree(this List<TreeNode> nodes) { // method impl .. }
Determining the root node is not optimized. In one of your examples, there is a root in the input nodes. In another example, there is no root. If the former case, we could use that root as tree. In the latter, we could create the null-root.
// Create a NULL-root tree Tree root = new Tree();
private static Tree FindTreeRoot(IList<TreeNode> nodes) { var rootNodes = nodes.Where(node => node.parent == null); if (rootNodes.Count() != 1) return new Tree(); var rootNode = rootNodes.Single(); nodes.Remove(rootNode); return Map(rootNode);
}
private static Tree Map(TreeNode node) { return new Tree { Id = node.id, Text = node.text, };
}Building the tree could then become a recursive action. I am using a list, in order to remove the visited nodes from the ones that still need to be visited.
public static Tree BuildTree(IEnumerable<TreeNode> nodes) { if (nodes == null) return new Tree(); var nodeList = nodes.ToList(); var tree = FindTreeRoot(nodeList); BuildTree(tree, nodeList); return tree;
}
private static void BuildTree(Tree tree, IList<TreeNode> descendants) { // Note: could be optimized further for performance var children = descendants.Where(node => node.parent == tree.Id).ToArray(); foreach (var child in children) { var branch = Map(child); tree.Add(branch); descendants.Remove(child); } foreach (var branch in tree.Children) { BuildTree(branch, descendants); }
}Code implementation
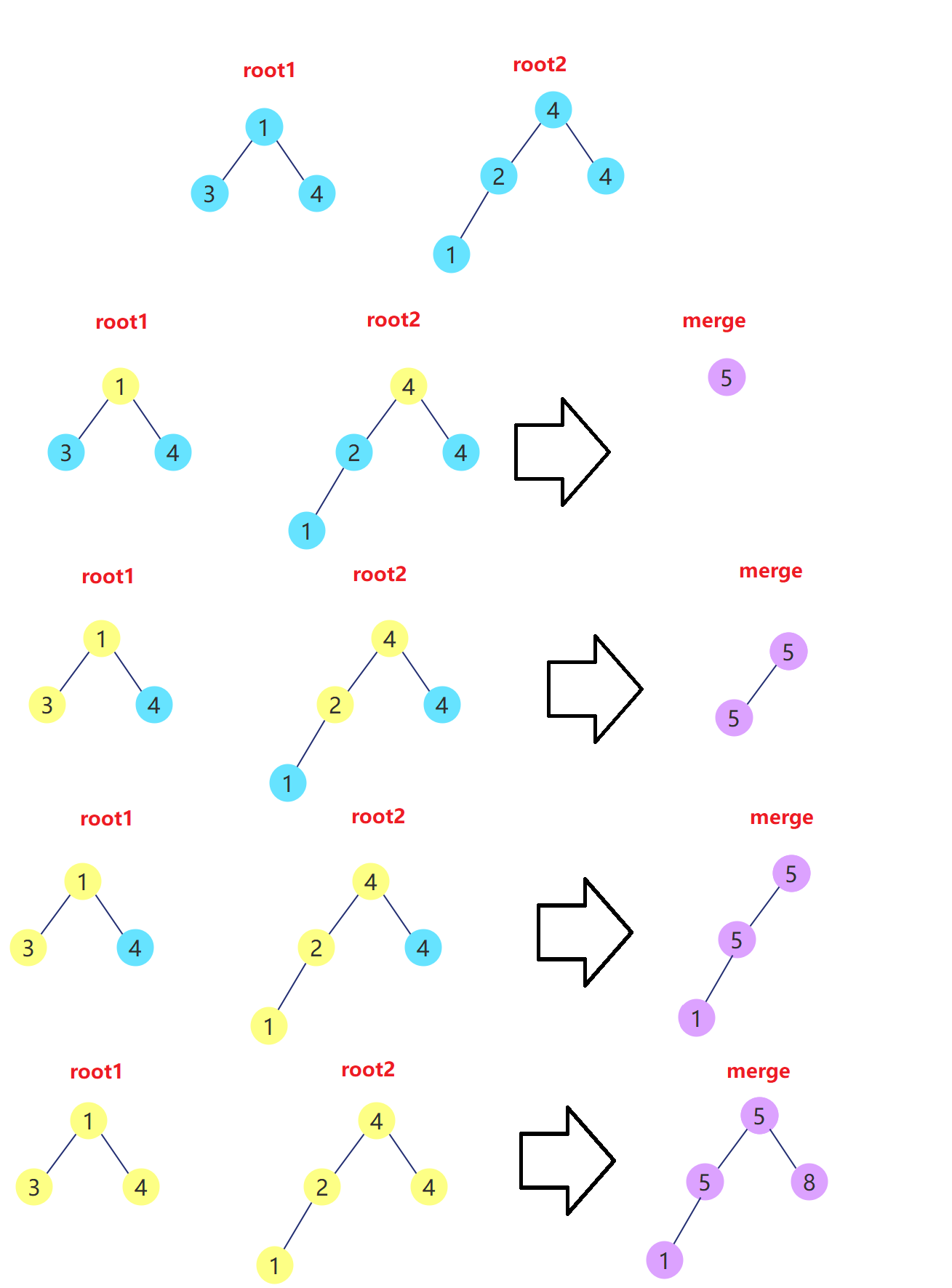
class Solution { public TreeNode mergeTrees(TreeNode root1, TreeNode root2) { if(root1 == null){ return root2;//root1 is null, and root2 is returned } if(root2 == null){ return root1;//root2 is null, and root1 is returned } //Create a new node TreeNode merge = new TreeNode(root1.val + root2.val); //Left subtree of this node merge.left = mergeTrees(root1.left,root2.left); //Right subtree of this node merge.right = mergeTrees(root1.right,root2.right); return merge;//Return to this node }
}Proposed Solution
This is an appendix of the classes used as an alternative/edited flow, with an example included.
public class Program
{ public static void Main() { //0 0 NULL //1 1 0 //11 11 1 //2 2 0 //21 21 2 //211 211 21 //22 22 2 //3 3 0 var nodes = new List<TreeNode> { new TreeNode { id = 0, text = "0", parent = null }, new TreeNode { id = 1, text = "1", parent = 0 }, new TreeNode { id = 11, text = "11", parent = 1 }, new TreeNode { id = 2, text = "2", parent = 0 }, new TreeNode { id = 21, text = "21", parent = 2 }, new TreeNode { id = 211, text = "211", parent = 21 }, new TreeNode { id = 22, text = "22", parent = 2 }, new TreeNode { id = 3, text = "3", parent = 0 } }; var tree = TreeBuilder.BuildTree(nodes); Console.ReadKey(); }
}
public class TreeNode
{ public int id { get; set; } public string text { get; set; } public int? parent { get; set; }
}
public static class TreeBuilder
{ public static Tree BuildTree(IEnumerable<TreeNode> nodes) { if (nodes == null) return new Tree(); var nodeList = nodes.ToList(); var tree = FindTreeRoot(nodeList); BuildTree(tree, nodeList); return tree; } private static void BuildTree(Tree tree, IList<TreeNode> descendants) { var children = descendants.Where(node => node.parent == tree.Id).ToArray(); foreach (var child in children) { var branch = Map(child); tree.Add(branch); descendants.Remove(child); } foreach (var branch in tree.Children) { BuildTree(branch, descendants); } } private static Tree FindTreeRoot(IList<TreeNode> nodes) { var rootNodes = nodes.Where(node => node.parent == null); if (rootNodes.Count() != 1) return new Tree(); var rootNode = rootNodes.Single(); nodes.Remove(rootNode); return Map(rootNode); } private static Tree Map(TreeNode node) { return new Tree { Id = node.id, Text = node.text, }; }
}
public static class TreeExtensions
{ public static IEnumerable<Tree> Descendants(this Tree value) { // a descendant is the node self and any descendant of the children if (value == null) yield break; yield return value; // depth-first pre-order tree walker foreach (var child in value.Children) foreach (var descendantOfChild in child.Descendants()) { yield return descendantOfChild; } } public static IEnumerable<Tree> Ancestors(this Tree value) { // an ancestor is the node self and any ancestor of the parent var ancestor = value; // post-order tree walker while (ancestor != null) { yield return ancestor; ancestor = ancestor.Parent; } }
}
public class Tree
{ public int? Id { get; set; } public string Text { get; set; } protected List<Tree> _children; protected Tree _parent; public Tree() { Text = string.Empty; } public Tree Parent { get { return _parent; } } public Tree Root { get { return _parent == null ? this : _parent.Root; } } public int Depth { get { return this.Ancestors().Count() - 1; } } public IEnumerable<Tree> Children { get { return _children == null ? Enumerable.Empty<Tree>() : _children.ToArray(); } } public override string ToString() { return Text; } public void Add(Tree child) { if (child == null) throw new ArgumentNullException(); if (child._parent != null) throw new InvalidOperationException("A tree node must be removed from its parent before adding as child."); if (this.Ancestors().Contains(child)) throw new InvalidOperationException("A tree cannot be a cyclic graph."); if (_children == null) { _children = new List<Tree>(); } Debug.Assert(!_children.Contains(child), "At this point, the node is definately not a child"); child._parent = this; _children.Add(child); } public bool Remove(Tree child) { if (child == null) throw new ArgumentNullException(); if (child._parent != this) return false; Debug.Assert(_children.Contains(child), "At this point, the node is definately a child"); child._parent = null; _children.Remove(child); if (!_children.Any()) _children = null; return true; }Simplify get
You can simplify the get method like this:
public TreeNode get(int element) { TreeNode runner = root; while (runner != null) { if (runner.data > element) { runner = runner.leftNode; } else if (runner.data < element) { runner = runner.rightNode; } else { return runner; } } return null;
}Breadth-first search
It’s called breadth-first, not «breath-first».
Also, this initialization is pointless, as you overwrite the value of runner immediately in the loop:
Queue<TreeNode> queue = new LinkedList<TreeNode>(); queue.add(root); TreeNode runner = root; while (!queue.isEmpty()) { runner = (TreeNode) queue.remove();
And, the cast is also pointless, because the Queue is correctly declared with TreeNode type.
Depth-first search
The depthFirstSearch method will set all node.visited = true, so you won’t be able to call it twice. Actually it’s really bad to have side effects like this. It would be better if TreeNode didn’t have the visited field at all. It’s polluting the class with data only used by one specific purpose, the depth-first search. It doesn’t belong there. You could track what was visited using a Set, used only in depthFirstSearch.
TreeNode
I would rename leftNode to left and rightNode to right. It’s simpler and everybody understands what they are.
Since you never need to change data, it can be final.
The current implementation is limited to int values. It would be better if the BST could store anything comparable.
Change the class declaration to this:
public class BST<T extends Comparable<T>> {Likewise for
TreeNodeReplace all comparison operations like
x.data < valuewithx.compareTo(value) < 0, likewise for>
Unit testing
Your basic test could easily become more useful (and less basic) if you do a get not only for one random element, but for all elements you inserted, since you have the array of values ready anyway:
@Test
public void basicTest() { BST tree = new BST(); int[] data = {9, 5, 3, 1, 4, 8, 15, 11, 21, 20, 29}; for (int i : data) { tree.insert(i); } for (int i : data) { assertEquals(i, tree.get(i).data); }
}A single test case named basicTest is not going to make this class «properly tested». At the very least you could add a few more test cases that are obviously necessary when talking about a binary search tree.
For example, what happens if you try to get non-existent elements?
@Test
public void testNoSuchElement() { BST tree = new BST(); assertNull(tree.get(3)); assertNull(tree.get(31));
}The BST should not allow duplicate values:
@Test
public void testNoDuplicateVaues() { BST tree = new BST(); int val = 3; tree.insert(val); tree.insert(val); tree.insert(val); assertEquals(1, tree.size());
}Of course this requires a .size method, so implement one, and a test case with it too:
public int size() { int count = 0; Queue<TreeNode> queue = new LinkedList<TreeNode>(); queue.add(root); TreeNode runner; while (!queue.isEmpty()) { runner = queue.remove(); if (runner != null) { ++count; queue.add(runner.leftNode); queue.add(runner.rightNode); } } return count;
}
@Test
public void testSize() { assertEquals(0, new BST().size()); BST tree = new BST(); int[] data = {9, 5, 3, 1, 4, 8, 15, 11, 21, 20, 29}; for (int i : data) { tree.insert(i); } assertEquals(data.length, tree.size());
}Formatting
The formatting is messy:
- the indentation is broken in
breathFirstSearchand inbasicTest - you should put a space before and after parentheses, for example:
while(!stack.empty()){should be formatted aswhile (!stack.empty()) {if(root == null){should be formatted asif (root == null) {
Basically, use your IDE to format code correctly. It also makes it easier to review. (For yourself too!)
Code implementation
class Solution { public int findSecondMinimumValue(TreeNode root) { return getMinValue(root,root.val); } public int getMinValue(TreeNode root,int val){ if(root==null) return -1; // Return - 1 larger than the root node is not found; if(root.val > val) return root.val;//If you find a node larger than the root node, return int left = getMinValue(root.left,val);//Left is the value of the left subtree int right = getMinValue(root.right,val);//Right is the value of the right subtree // If there is a value larger than the root node, the smaller one is returned if(left >=0 && right >= 0){ return Math.min(left,right); } // If left has right, it does not return to left // If left has no right, return to right // If left is not right, no one is returned // The combination of the three cases is to return the largest one return Math.max(left,right); }
}JavaScript Solution
function BT(value, left = null, right = null) { this.value = value; this.left = left; this.right = right;
}A method to find the minimum depth can be something like so:
BT.prototype.getMinDepth = function() { if (!this.value) { return 0; } if (!this.left && !this.right) { return 1; } if (this.left && this.right) { return Math.min(this.left.getMinDepth(), this.right.getMinDepth()) + 1; } if (this.left) { return this.left.getMinDepth() + 1; } if (this.right) { return this.right.getMinDepth() + 1; }
}The time complexity of the above solution is O(n) as it traverses all the tree nodes.
A better runtime solution will be to use a breadth traversal method that ends when reaching the first leaf node:
BT.prototype.getMinDepth = function(depth = 0) { if (!this.value) { return depth; } depth++; if (!this.left || !this.right) { return depth; } return Math.min(this.left.getMinDepth(depth), this.right.getMinDepth(depth));
}answered Jan 4, 2020 at 17:16

Lior Elrom
16 gold badges80 silver badges92 bronze badges
Given the depth of a path is the number of nodes from the root to the leaf node along this path. The minimum is the path with minimum number of nodes from the root to the LEAF node. In this case, the only leaf node is 2. (A leaf node is defined as a node with no children) Therefore, the only depth and also min depth is 2.
A sample code in Java:
public class Solution { public int minDepth(TreeNode root) { if (root==null) return 0; if ((root.left==null) || (root.right==null)) { return 1+Math.max(minDepth(root.left),minDepth(root.right)); } return 1+Math.min(minDepth(root.left),minDepth(root.right)); }
}answered Apr 30, 2015 at 3:05

C. Zeng
1 gold badge8 silver badges10 bronze badges
Minimum depth is the minimum of the depth of leftsubtree and rightsubtree.
public static int maxDepth(TreeNode root) { if(root == null) { return 0; } return getDepth(root);
}
private static int getDepth(TreeNode a) { if(a.left == null & a.right == null) { return 1; } int leftDepth = 0; int rightDepth = 0; if(a.left != null) { leftDepth = getDepth(a.left); } if(a.right != null) { rightDepth = getDepth(a.right); } return (Math.min(leftDepth, rightDepth)+1);
}answered Jun 14, 2019 at 5:11

5 gold badges31 silver badges37 bronze badges
int minDepth(TreeNode root) { if (root == null) { return 0;} return 1 + Math.min(minDepth(root.left), minDepth(root.right));
}answered Jun 18, 2014 at 9:47

1 gold badge11 silver badges23 bronze badges
Lexicon
In computer science, many API’s use the terminology below.
descendant: any child, grandchild, ..descendantOrSelf: any descendant or the specified node itselfancestor: any parent, grandparent, ..ancestorOrSelf: any ancestor or the specified node itself
However, I tend to use family tree terminology.
successor: any child, grandchild, ..descendant: any successor or the specified node itselfpredecessor: any parent, grandparent, ..ancestor: any predecessor or the specified node itself
Problem solving ideas
- Recursive two trees by preorder traversal
- Each recursion determines whether it is empty
① root1 is null, just return root2
② root2 is empty, just return root1 - Define a new tree merge. When recursive, add the values of the nodes of the two trees into the merge Val medium
- Recursively merge left and right subtrees;
- Finally, return to merge
The Tree Node Payload’s Awareness of its Place in the Tree
You probably noticed in the last section that the Value object is checked to see if it implements the ITreeNodeAware interface. This is an optional extensibility mechanism for custom classes that need to be aware of the tree so that payload objects can read or manipulate it in some way. In developing a data binding framework for Windows Forms that allows you to bind control properties to paths (“PurchaseOrder.Customer.Name”) instead of specific objects (PurchaseOrder.Customer, “Name”), as ASP.NET and WPF data binding works, I needed this ability and came to the conclusion that this would be a useful feature in general. Later in the article, I will magically transform the TreeNode and TreeNodeList classes in such a way that both this interface and the Value property become unnecessary.
Until then, here’s how the interface looks with an example class that uses it.
public
public : <>
Complete = ;
<> _Node;
<> Node
_Node = ;
// do something when the Node changes
// if non-null, maybe we can do some setup
MarkComplete()
// mark all children, and their children, etc., complete
(<> ChildTreeNode Node.Children)
// now that all decendents are complete, mark this task complete
Complete = ;
Using the ITreeNodeAware interface means we have another step to make in our implementation, and adds some complexity to its use in terms of discoverability and implementation of the interface by consumers of the Tree structure in creating custom payload classes. By doing this, however, our Task objects will get injected with a Node property value when added to a Tree of Tasks. So the payload object will point to the node via the Node property, and the Node will point to payload object via its Value property. This is a lot of logic for such a simple relationship, but as we’ll see later, there is an elegant way around all of this.
Data Integrity
Encapsulating the family members _parent, _children provides us with the capability of preserving the tree’s integrity.
public class Tree { public int? id { get; set; } public string text { get; set; } public List<Tree> children { get; set; } }
public class Tree
{ public int? Id { get; set; } public string Text { get; set; } protected List<Tree> _children; protected Tree _parent; public Tree Parent { get { return _parent; } } public Tree Root { get { return _parent == null ? this : _parent.Root; } } public IEnumerable<Tree> Children { get { return _children == null ? Enumerable.Empty<Tree>() : _children.ToArray(); } }
}We could then have Add and Remove support with sufficient validation support to maintain integrity.
public void Add(Tree child) { if (child == null) throw new ArgumentNullException(); if (child._parent != null) throw new InvalidOperationException( "A tree node must be removed from its parent before adding as child."); if (this.Ancestors().Contains(child)) throw new InvalidOperationException("A tree cannot be a cyclic graph."); if (_children == null) { _children = new List<Tree>(); } Debug.Assert(!_children.Contains(child), "At this point, the node is definately not a child"); child._parent = this; _children.Add(child);
}
public bool Remove(Tree child) { if (child == null) throw new ArgumentNullException(); if (child._parent != this) return false; Debug.Assert(_children.Contains(child), "At this point, the node is definately a child"); child._parent = null; _children.Remove(child); if (!_children.Any()) _children = null; return true;
}Connecting Nodes to Their Parents & Children
The intelligence needed to make a Tree work resides in two classes: TreeNode and TreeNodeList. I could have used a standard collection type for TreeNodeList, but each TreeNode links to both Parent and Children nodes, which are two fundamentally different relationships; and I wanted parent and child nodes to connect and disconnect automatically behind-the-scenes—if you add a child to X, that child’s Parent property should automatically be set to X, and vice versa. That requires hooking into the Add method in a custom collection class to manage those relationships. TreeNodeList therefore looks like this:
public : <>
Parent;
TreeNodeList( Parent)
.Parent = Parent;
Add( Node)
Node.Parent = Parent;
Add(T Value)
Add( (Value));
ToString()
+ Count.ToString();
The ToString override is very important for making your debugging sessions more manageable. Without this kind of assistance, especially when troubleshooting recursive, hierarchical algorithms, you may go crazy digging through the debugger’s own tree view control to find what you’re looking for.
Cleaning Up
Now that the basic functionality is in place, I decided to split the Tree class into two. SimpleTree represents a simple tree data structure that can contain as its Value any object; and ComplexTree, which uses the generic constraint described above and supports more complex hierarchical algorithms and tree-aware nodes. I really like the simplicity of the Tree name, but along with the need to support both simple and complex scenarios, there are two more reasons for this name-change decision.
First, in the System.Windows.Forms namespace, there is already a TreeNode class that corresponds to the TreeView control. If I had designed that control, I probably would have named it VisualTree and its node VisualTreeNode to distinguish it from a logical node, but as it is, dealing with two different TreeNode classes, even in different namespaces, could be confusing and messy. Second, the new Task Parallel Library (TPL) contains an implementation of a binary tree called Tree, which is a rather short-sighted name considering that all useful trees are not binary trees, as I’ve demonstrated in this article; BinaryTree would have been a much more appropriate name. Hopefully by the time TPL is released, this identifier will be updated to reflect this.
Code implementation
class Solution { public boolean leafSimilar(TreeNode root1, TreeNode root2) { // false if the list s of the two trees are different; otherwise, true; return getNode(root1).equals(getNode(root2)); } public List<Integer> getNode(TreeNode root){ List<Integer> list = new ArrayList<>(); if(root == null) { return list; } // The left and right subtrees do not exist, that is, leaf nodes if(root.left == null && root.right == null){ list.add(root.val); } list.addAll(getNode(root.left)); list.addAll(getNode(root.right)); return list; }
}Binary vs. Non-Binary Trees

Figure 1. A generic binary tree.
Trees with similar leaves
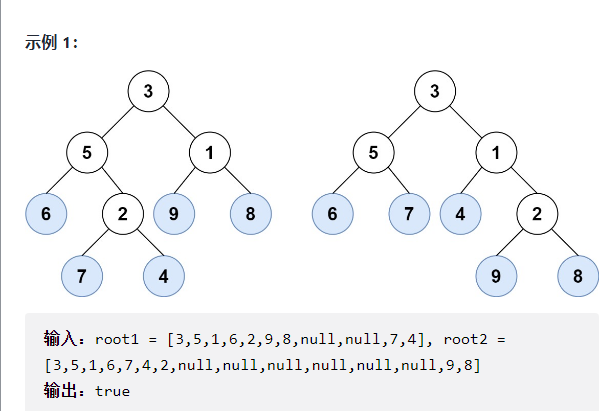
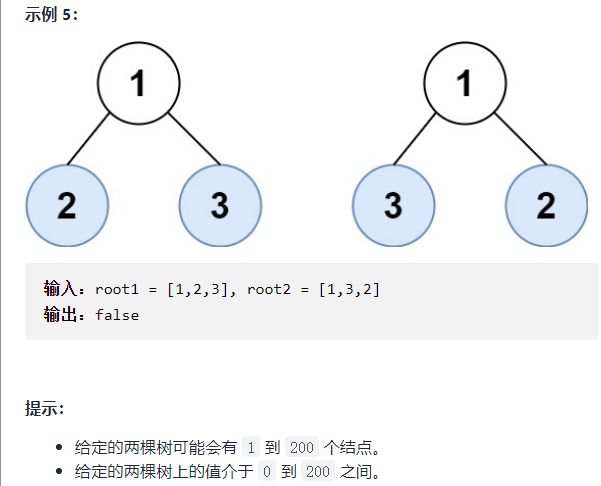
LeetCode 872 : Trees with similar leaves
Description:
Consider all the leaves in a binary tree. The values of these leaves are arranged from left to right to form a leaf value sequence.
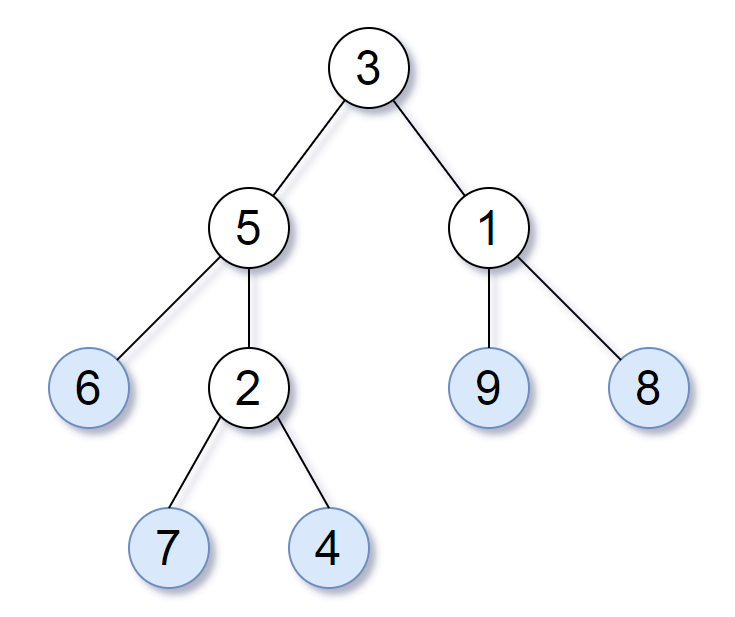
For example, as shown in the figure above, a tree with leaf value sequence of (6, 7, 4, 9, 8) is given.
If the leaf value sequences of two binary trees are the same, we think they are leaf similar.
If the leaves of a given tree with two root nodes root1 and root2 are similar, return true; Otherwise, false is returned.
Layer average of binary tree
LeetCode 637 : Layer average of binary tree
Description:
Given a non empty binary tree, return an array composed of the average value of nodes in each layer.

Drawing analysis
Problem solving ideas
- You can know that the root node must be the minimum
- Therefore, the method of preorder traversal is used to recurse the left subtree and the right subtree respectively
- Recursion returns directly as long as it finds a value larger than the root node. When the node is empty (not found), it returns — 1;
- If both the left and right subtrees have a value larger than the root node, the smaller value is returned
- If not on the left, return to the right
- If not on the right, return to the left
- If there are no on both sides, return — 1;
The Tree Node
The TreeNode itself gets a little tricky. If you update the Parent property because a node is going to be moved to another part of the tree, for example, you want to make sure that it gets removed from the Parent’s list of Children, and you also want to add it as a child to the new Parent. If the Parent was null, or is being set to null, then only one of those operations (remove or add) is necessary.
Here are the primary structural and payload-containing portions of this early version of the TreeNode class:
public :
_Parent;
Parent
( == _Parent)
(_Parent != )
( != && !.Children.Contains())
_Parent = ;
Root
//return (Parent == null) ? this : Parent.Root;
node = ;
(node.Parent != )
node = node.Parent;
_Children;
Children
T _Value;
T Value
_Value = ;
(_Value != && _Value )
(_Value ).Node = ;
A tree structure isn’t very useful, however, unless it can carry some kind of payload. You want to build a tree something, and it’s handy that we can use generics to tell the compiler that we want a Tree of strings (Tree), for example. That’s what the Value property is for, and why its type is the generic type parameter T.
To instantiate and initialize TreeNodes, you’ll need some constructors. Here are two of them I defined:
public
.Value = Value;
Parent = ;
Children = ();
public TreeNode(T Value, Parent)
.Value = Value;
.Parent = Parent;
Children = ();
Drawing analysis
Drawing analysis
Review
Keep in mind I am using an older version of .NET so my semantics can be somehow verbose.
The Role of Generics in Representing Payloads
I have already supplied enough logic and sample code for a fully functioning tree data structure for use in the .NET Framework, which incidentally was developed in a Compact Framework project and will therefore work in any .NET environment. That being said, there are some syntactical inconveniences with the approach mentioned so far. Consider the Tree example above in a scenario where we want to access a parent node’s payload from a current node:
TreeNode> CurrentTaskNode = /* get current task node */
bool IsComplete = CurrentTaskNode.Parent.Value.Complete;
Note that Parent doesn’t return our object of type T, but instead gives us a TreeNode; and our CurrentTaskNode object is also a node object and not a task object. When we think about trees in theory, especially visually in the form of diagrams, the parent of a node is another node, meaning that parent and child are the same type of thing. In our simple implementation so far, however, the parent of a task is not another task, but rather a task-tree-node, which is not the same thing.
If we start from a Task object instead of a TreeNode, the syntax is worse:
Task CurrentTask = /* get current task */;
bool IsComplete = CurrentTask.Node.Parent.Value.Complete;
Notice how each time we access Node or Value, we’re weaving in and out between types. So we must manipulate this data structure and its payload all the while with explicit deference to the type disparity and dualism, and a careful naming of variables is important to avoid confusion between types (CurrentTaskNode vs. CurrentTask). When I first had this realization, it occurred to me why a Tree data type may have been missing from the original .NET Framework. I doubt very much that all the brilliant developers working on the base class libraries didn’t think to include such a useful structure, but perhaps the obvious implementations that came to mind seemed confusing and problematic for real-world use.
Fortunately, we now have capabilities in the CLR as of 2.0—and corresponding language features—that enable us to solve this problem elegantly. I’m referring to generics, and more specifically, to generic constraints.
The simplifying idea is that by creating a payload class that inherits from TreeNode, and applying a simple generic constraint to get around some casting problems that would normally prevent us from compiling, we can make our final syntax look like this:
Task MakeDinner = ();
Task PrepareIngredients = MakeDinner.Children.Add( ());
Task CookMeal = MakeDinner.Children.Add( ());
Task PreheatOven = CookMeal.Children.Add( ());
Task BakeAt350 = CookMeal.Children.Add( ());
Task Cleanup = MakeDinner.Children.Add( ());
bool IsAllDone = BakeAt350.Parent.Parent.Complete;
Notice that in the final statement, we don’t have to navigate from BakeAt350 to some different type object through a Node property, and that we can go directly from Parent to the Complete property. This is because our Task class is defined like this now:
public
// mark all children, and their children, etc., complete
// now that all decendents are complete, mark this task complete
It’s been compressed! The Node property is no longer necessary (since the task is-a node, instead of being contained-by a node), and therefore the ITreeNodeAware interface can also be dispensed with. The MarkComplete method is different, too: we simply write Child.MarkComplete instead of Child.Value.MarkComplete, and we can loop through a collection of Task objects with the Children property directly, instead of going through a set of TreeNode objects in some external Node object.
In our consuming code above, we didn’t even have to mention the Tree or TreeNode type, but if we did declare a variable that way (for the sake of clarity), it would simply be a synonym of Task. It would look like this:
Tree<> MakeDinner = <>();
We could use TreeNode as well; it makes no difference. Task = Tree = TreeNode.
To make all of this magic happen, we need to define TreeNode with a generics constraint.
public : T :
This tells the compiler that T must inherit from TreeNode, and therefore variables of type T are safe to manipulate as tree nodes. TreeNodeList requires the same constraint:
public : <> T :
This breaks us out of a restrictive pattern where normally a custom collection class is unable to richly manipulate the objects within it (unless the collection is instantiated directly from consumer code, which is not the case in this pattern). But because the collection class knows that all of its items will derive from TreeNode, it can manipulate them as tree nodes with no problem.
There is a price to pay for this convenience, however, which is that the tree is restricted to types that inherit from TreeNode. This means that a Tree is no longer possible. You will have to decide how you will likely use trees in your development to determine whether to design something like this into it. If you want this cleaner syntax but still need trees of primitive and other non-TreeNode-derived types, you can create a distinct SimpleTree for this purpose. It may even be possible for Tree to inherit from SimpleTree, hiding the Value property (with a private shadow method shown below) and adding the generic constraint.
Including Structure Helper Members
There are some common measurements of aspects of the tree’s nodes, as well as operations that you will typically want to perform on a tree or subtree, such as initialization, systematic traversal, pruning and grafting, disposal, and determination of depth, some of which I will discuss here.
Here is a property to determine your current nesting depth, which can be useful while debugging:
public Depth
//return (Parent == null ? -1 : Parent.Depth) + 1;
depth = 0;
node = ;
(node.Parent != )
node = node.Parent;
Because the payload objects (referenced by the Value property) may require disposing, the tree nodes (and therefore the tree as a whole) is IDisposable. Different trees of objects may require being disposed in different orders, so I’ve created a TreeTraversalType, a DisposeTraversal property of this type to specify the order, and have implemented the Dispose method that takes this into consideration.
public
private _DisposeTraversal = .BottomUp;
public DisposeTraversal
Here is one way to implement IDisposable that includes a property indicating whether a node has been disposed, invokes a Disposing event, and traverses the tree according to the value of DisposeTraversal.
private _IsDisposed;
public IsDisposed
public Dispose()
// clean up contained objects (in Value property)
(Value )
(DisposeTraversal == .BottomUp)
( node Children)
(Value ).Dispose();
(DisposeTraversal == .TopDown)
( node Children)
_IsDisposed = ;
public Disposing;
protected OnDisposing()
(Disposing != )
public CheckDisposed()
(GetType().Name);
I overrode ToString in the TreeNodeList class above to display the count of children. I do the same thing for TreeNode, which as I mentioned earlier aids a great deal in debugging.
public ToString()
Description = .Empty;
(Value != )
Description + + Depth.ToString() +
Notice how the Value property, if it’s set, gets included in the ToString value. If you’re looking at a TreeNode in the watch window, you’ll appreciate that your Value object can be represented without having to drill into anything. You can see at a glance what the payload is, how deep it is in the tree, and how many child nodes it has.
Merging binary trees
LeetCode 617 : Merge binary tree
Description:
Given two binary trees, imagine that when you overlay one of them on the other, some nodes of the two binary trees will overlap.
You need to merge them into a new binary tree. The merging rule is that if two nodes overlap, their values are added as the new value after node merging. Otherwise, the node that is not NULL will be directly used as the node of the new binary tree.

Defining the Basic Components
There is a lot of formal terminology in graph theory to contend with, but for our purposes, we only really need to be concerned with a few basic terms.
- Tree – This refers to a collection of nodes connected by parent-child relationships in a hierarchical structure.
- Parent – A node one level up from the current node.
- Child – A node one level down from the current node.
- Node – One item in a tree with an optional parent and zero or more children.
- Root Node – A special node with no parent. A tree can have only one root node.
- Subtree – A section of a larger tree including the non-root node of a larger tree, plus all of its children.
That’s not so bad, is it? In designing a reusable tree data structure, it’s important to establish a consistent and sensible pattern for semantics. In fact, coming up with good names for the components of our data structure may be the most difficult part. With poor identifiers, even simple structures can be confusing to those using it.
Examples of Non-Binary Trees
A simple example of a non-binary tree is the file system in any modern operating system. The diagram below (figure 2) illustrates a small part of the structure of the Windows file system. Folders can be nested inside other folders as deeply as needed, providing the ability to compose a complex organizational structure for storing files. The traversal path—from the root to some other node—can be represented by a canonical resource descriptor such as C:\Windows\system32.

Figure 2. The file system is a tree structure of folders containing other folders.

Figure 3. A tree view control in Windows Explorer provides access to a hierarchy of nested folders.
Another example is the organization of controls in a form (for Windows Forms) or in a window (for WPF). The next diagram (figure 4) depicts the relationship of controls containing child controls, which may in turn contain their own children, and so on.

Figure 5. The document outline window in Visual Studio for a Windows Forms screen.
Problem solving ideas
- Using the sequence traversal method, the values of each layer are added together
- Record the number of data in each layer
- The total of each layer ÷ the number of each layer is the average value of each layer
- Note the range of nodes here. The sum of each layer may exceed int, so long is used here
Navigation
You are lacking a reference back to the parent, which makes bottom-up navigation much harder. A tree that knows its parent allows for much more flexibility in navigation.
root.children.Add(new Tree() { id = node.id, text = node.text, children = null // <- no parent reference ;-( });
public class Tree
{ public int? Id { get; set; } public string Text { get; set; } protected List<Tree> _children; protected Tree _parent; // <- added reference to parent :-)
}Now, we can use TreeExtensions to nagivate a tree. The most basic tree traversal walkers are available. More could be added if required.
public static class TreeExtensions
{ public static IEnumerable<Tree> Descendants(this Tree value) { // a descendant is the node self and any descendant of the children if (value == null) yield break; yield return value; // depth-first pre-order tree walker foreach (var child in value.Children) foreach (var descendantOfChild in child.Descendants()) { yield return descendantOfChild; } } public static IEnumerable<Tree> Ancestors(this Tree value) { // an ancestor is the node self and any ancestor of the parent var ancestor = value; // post-order tree walker while (ancestor != null) { yield return ancestor; ancestor = ancestor.Parent; } }
}Begin with the End in Mind
I began with a quasi-test-driven development approach. I asked myself how I’d like the end result to look when consuming the new data structure. I knew from the start that a tree data structure that didn’t use generics wasn’t going to be very useful. Imagine this code:
What is the type of each node in the tree? If I’m going to use this in different scenarios, the only answer is to make it an object, so that I could store whatever I liked in my tree, but this would require a lot of casting and a lack of type checking at compile type. So instead, using generics, I could define something like this:
This is much better, and leads to two more steps that we’ll need to take conceptually. The first one is that I will definitely want a tree of nodes for custom types in my software’s problem domain, perhaps Customer or MobileDevice objects. Like strings, these objects are (for our purposes here) simply dumb containers of data in the sense that they are unaware of the tree structure in which they reside. If we take this one level further, and consider custom types that are aware of their place within the tree (and can therefore particpate in much richer ways to compose hierarchical algorithms), we’ll need to consider how to make that awareness happen. I will explain this in more detail later in this article.
public :
Tree(T RootValue)
Value = RootValue;
This definition of Tree is really a matter of semantics and syntax preference. I’m creating an alias for the TreeNode type, claiming that a Tree is a node itself—the root node in a Tree, by convention. I call this a synonym type. Here’s a very simple example of its use:
Tree> root =
int d0 = zero.Depth;
TreeNode> one = zero.Children.Add(
int d1 = one.Depth;
TreeNode> twoa = one.Children.Add(
TreeNode> twob = one.Children.Add(
TreeNode> twoc = one.Children.Add(
twocstr = twoc.Value;
d2 = two.Depth;
You can tell a few things by looking at this code:
- The root node is defined as a Tree, but is manipulated like the other TreeNodes because it inherits from TreeNode.
- Each node’s value is stored in a property called Value, which has a type of T (using generics).
- A Depth property indicates how deeply in the tree the node is nested (the root has a depth of 0).
- The Add method in the Children TreeNode collection returns a TreeNode object, making it easier to create a new node and get a handle to it in the same statement.
Conclusion
Elegant implementations of tree data structures in .NET Framework, though problematic in the past, are finally possible with the introduction of generics and generic constraints. With some careful syntax planning for consuming code, as well as experimentation with different language constructs, I hope I have shed some light on how these kinds of problems can be approached and solved.
In future articles, I will be exploring some techniques and specific uses for hierarchical algorithms. Some of the very problems that appear too difficult to solve without a background in mathmatics can be much more easily understood and mastered by using tree data structures and associated visualization techniques.
")




")