

- A Tree with Simple Variables
- Writing the Tree
- Creating Branches with A single Variable
- Filling the Tree
- Viewing the Tree
- Reading the Tree
- GetEntry
- Why Should You Use a Tree?
- Impact of Compression on I/O
- Simple Analysis Using TTree
- Using Selection with TTree:Draw
- Using TCut Objects in TTree::Draw
- Accessing the Histogram in Batch Mode
- Using Draw Options in TTree::Draw
- Superimposing Two Histograms
- Setting the Range in TTree::Draw
- TTree::Draw Examples
- Explanations:
- Multiple variables visualisation
- Spider (Radar) Plots
- Parallel Coordinates Plots
- Box (Candle) Plots
- Using TTree::Scan
- TEventList and TEntryList
- Main Differences between TEventList and TEntryList
- Using an Event List
- Operations on TEntryLists
- TEntryListFromFile
- Filling a Histogram
- Projecting a Histogram
- Making a Profile Histogram
- Tree Information
- Video Transcription
- How does a tree’s root system form and what is its purpose?
- Absorption
- Conduit
- Storage
- Anchorage
- Tap Roots
- Finding the Nutrients
- Functions of Roots
- Print the Tree Structure with TTree
- A Tree with a C Structure
- Writing the Tree
- Adding a Branch with a Fixed Length Array
- Adding a Branch with a Variable Length Array
- Filling the Tree
- Analysis
- Adding a Branch to Hold a List of Variables
- Orders of Root
- Primary Roots
- Secondary Roots
- Tertiary Roots
- Root Structure
- Root cap
- Region of cell division
- Region of elongation
- Region of maturation
- Chains
- TChain::AddFriend
- Characteristics of Root
- Structure of Roots
- Root Cap
- Region of Meristematic Activity
- Region of Elongation
- Region of Maturation
- Modification of Root
- Modification for Food capacity
- Modification for Support
- Modified for Respiratory
- A Simple TTree
- Differences between Monocot and Dicot roots
- Show an Entry with TTree
A Tree with Simple Variables
This example shows how to write, view, and read a tree with several simple (integers and floating-point) variables.
Writing the Tree
Below is the function that writes the tree (tree1w). First, the variables are defined (px, py, pz, random and ev). Then we add a branch for each of the variables to the tree, by calling the TTree::Branch method for each variable.
tree1w(){ // create a tree file tree1.root - create the file, the Tree and // a few branches TFile f(,); TTree t1(,"a simple Tree with simple variables"); px, py, pz; random; ev; t1.Branch(,&px,); t1.Branch(,&py,); t1.Branch(,&pz,); t1.Branch(,&ev,); // fill the tree ( i=; i<; i++) { gRandom->Rannor(px,py); pz = px*px + py*py; random = gRandom->Rndm(); ev = i; t1.Fill(); } // save the Tree heade; the file will be automatically closed // when going out of the function scope t1.Write();}Creating Branches with A single Variable
This is the signature of TTree::Branch to create a branch with a list of variables:
The first parameter is the branch name. The second parameter is the address from which to read the value. The third parameter is the leaf list with the name and type of each leaf. In this example, each branch has only one leaf. In the box below, the branch is named px and has one floating point type leaf also called px.
Filling the Tree
First we find some random values for the variables. We assign px and py a Gaussian with mean = 0 and sigma = 1 by calling gRandom->Rannor(px,py), and calculatepz. Then we call the TTree::Fill() method. The call t1.Fill() fills all branches in the tree because we have already organized the tree into branches and told each branch where to get the value from. After this script is executed we have a ROOT file called tree1.root with a tree called t1. There is a possibility to fill branches one by one using the method TBranch::Fill(). In this case you do not need to call TTree::Fill() method. The entries can be set by TTree::SetEntries(Double_t n). Calling this method makes sense only if the number of existing entries is null.
Viewing the Tree
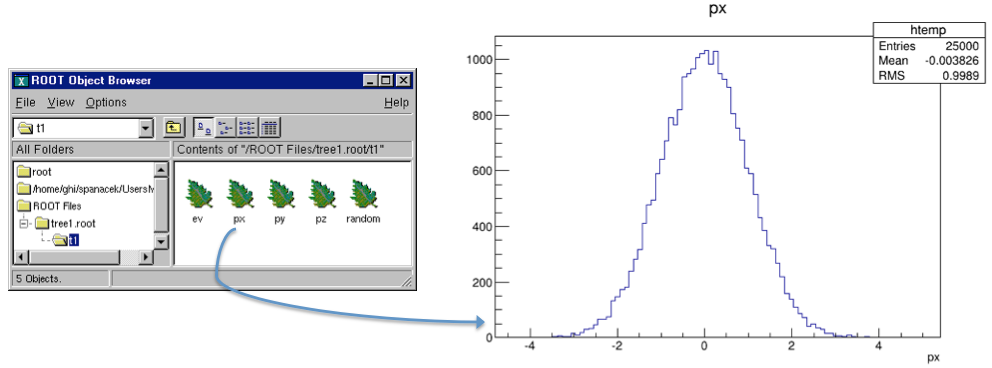
In the right panel of the ROOT object browse are the branches: ev, px, py, pz, and random. Note that these are shown as leaves because they are “end” branches with only one leaf. To histogram a leaf, we can simply double click on it in the browser. This is how the tree t1 looks in the Tree Viewer. Here we can add a cut and add other operations for histogramming the leaves. See “The Tree Viewer”. For example, we can plot a two dimensional histogram.
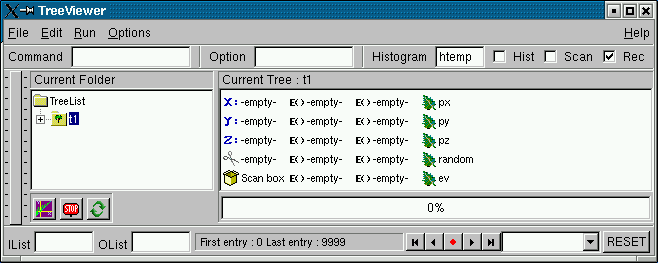
Reading the Tree
The tree1r function shows how to read the tree and access each entry and each leaf. We first define the variables to hold the read values.
Then we tell the tree to populate these variables when reading an entry. We do this with the method TTree::SetBranchAddress. The first parameter is the branch name, and the second is the address of the variable where the branch data is to be placed. In this example, the branch name is px. This name was given when the tree was written (see tree1w). The second parameter is the address of the variable px.
GetEntry
Once the branches have been given the address, a specific entry can be read into the variables with the method TTree::GetEntry(n). It reads all the branches for entry (n) and populates the given address accordingly. By default, GetEntry() reuses the space allocated by the previous object for each branch. You can force the previous object to be automatically deleted if you call mybranch.SetAutoDelete(kTRUE) (default is kFALSE).
Consider the example in $ROOTSYS/test/Event.h. The top-level branch in the tree T is declared with:
When reading the Tree, one can choose one of these 3 options:
This is the default and recommended way to create an object of the class Event.It will be pointed by event.
The pointer member is read via the pointer->Streamer(buf) if “->” is specified. In this case, it is assumed that the pointer is never null (see pointer TClonesArray *fTracks in the $ROOTSYS/test/Event example). If “->” is not specified, the pointer member is read via buf >> pointer. In this case the pointer may be null. Note that the option with “->” is faster to read or write and it also consumes less space in the file.
Option 2 — the option AutoDelete is set:
At any iteration, the GetEntry deletes the object event and a new instance of Event is created and filled.
Option 3 — same as option 1, but you delete the event yourself:
It is strongly recommended to use the default option 1. It has the additional advantage that functions like TTree::Draw (internally calling TTree::GetEntry) will be functional even when the classes in the file are not available. Reading selected branches is quicker than reading an entire entry. If you are interested in only one branch, you can use the TBranch::GetEntry method and only that branch is read. Here is the script tree1r:
tree1r(){ // read the Tree generated by tree1w and fill two histograms // note that we use "new" to create the TFile and TTree objects, // to keep them alive after leaving this function. TFile *f = TFile(); TTree *t1 = (TTree*)f->Get(); px, py, pz; random; ev; t1->SetBranchAddress(,&px); t1->SetBranchAddress(,&py); t1->SetBranchAddress(,&pz); t1->SetBranchAddress(,&random); t1->SetBranchAddress(,&ev); // create two histograms TH1F *hpx = TH1F(,,,-,); TH2F *hpxpy = TH2F(,"py vs px",,-,,,-,); //read all entries and fill the histograms nentries = ()t1->GetEntries(); ( i=; i<nentries; i++) { t1->GetEntry(i); hpx->Fill(px); hpxpy->Fill(px,py); } // We do not close the file. We want to keep the generated // histograms we open a browser and the TreeViewer (gROOT->IsBatch()) ; TBrowser (); t1->StartViewer(); //In the browser, click on "ROOT Files", then on "tree1.root" //You can click on the histogram icons in the right panel to draw }Why Should You Use a Tree?
In the “Input/Output” chapter, we saw how objects can be saved in ROOT files. In case you want to store large quantities of same-class objects, ROOT has designed the TTree and TNtuple classes specifically for that purpose. The TTree class is optimized to reduce disk space and enhance access speed. A TNtuple is a TTree that is limited to only hold floating-point numbers; a TTree on the other hand can hold all kind of data, such as objects or arrays in addition to all the simple types.
When using a TTree, we fill its branch buffers with leaf data and the buffers are written to disk when it is full. Branches, buffers, and leafs, are explained a little later in this chapter, but for now, it is important to realize that each object is not written individually, but rather collected and written a bunch at a time.
This is where the TTree takes advantage of compression and will produce a much smaller file than if the objects were written individually. Since the unit to be compressed is a buffer, and the TTree contains many same-class objects, the header of the objects can be compressed.
The TTree reduces the header of each object, but it still contains the class name. Using compression, the class name of each same-class object has a good chance of being compressed, since the compression algorithm recognizes the bit pattern representing the class name. Using a TTree and compression the header is reduced to about 4 bytes compared to the original 60 bytes. However, if compression is turned off, you will not see these large savings.
The TTree is also used to optimize the data access. A tree uses a hierarchy of branches, and each branch can be read independently from any other branch. Now, assume that Px and Py are data members of the event, and we would like to compute Px2 + Py2 for every event and histogram the result.
If we had saved the million events without a TTree we would have to:
- read each event in its entirety into memory
- extract the
PxandPyfrom the event - compute the sum of the squares
- fill a histogram
We would have to do that a million times! This is very time consuming, and we really do not need to read the entire event, every time. All we need are two little data members (Px and Py). On the other hand, if we use a tree with one branch containing Px and another branch containing Py, we can read all values of Px and Py by only reading the Px and Py branches. This makes the use of the TTree very attractive.
Impact of Compression on I/O
This benchmark illustrates the pros and cons of the compression option. We recommend using compression when the time spent in I/O is small compared to the total processing time. In this case, if the I/O operation is increased by a factor of 5 it is still a small percentage of the total time and it may very well save a factor of 10 on disk space. On the other hand if the time spend on I/O is large, compression may slow down the program’s performance. The standard test program $ROOTSYS/test/Event was used in various configurations with 400 events. The data file contains a TTree. The program was invoked with:
- comp = 0 means: no compression at all.
- comp = 1 means: compress everything if split = 0.
- comp = 1 means: compress only the tree branches with integers if split = 1.
- comp = 2 means: compress everything if split=1.
- split = 0 : the full event is serialized into one single buffer.
- split = 1 : the event is split into branches. One branch for each data member of the Event class. The list of tracks (a
TClonesArray) has the data members of the Track class also split into individual buffers.
These tests were run on Pentium III CPU with 650 MHz.
The Total Time is the real time in seconds to run the program. Effective time is the real time minus the time spent in non I/O operations (essentially the random number generator). The program Event generates in average 600 tracks per event. Each track has 17 data members. The read benchmark runs in the interactive version of ROOT. The ‘Total Time to Read All’ is the real time reported by the execution of the script &ROOTSYS/test/eventa.
We did not correct this time for the overhead coming from the interpreter itself. The Total time to read sample is the execution time of the script $ROOTSYS/test/eventb. This script loops on all events. For each event, the branch containing the number of tracks is read. In case the number of tracks is less than 585, the full event is read in memory. This test is obviously not possible in non-split mode. In non-split mode, the full event must be read in memory. The times reported in the table correspond to complete I/O operations necessary to deal with machine independent binary files. On Linux, this also includes byte-swapping operations. The ROOT file allows for direct access to any event in the file and direct access to any part of an event when split=1.
Note also that the uncompressed file generated with split=0 is 48.7 Mbytes and only 47.17 Mbytes for the option split=1. The difference in size is due to the object identification mechanism overhead when the event is written to a single buffer. This overhead does not exist in split mode because the branch buffers are optimized for homogeneous data types. You can run the test programs on your architecture. The program Event will report the write performance. You can measure the read performance by executing the scripts eventa and eventb. The performance depends not only of the processor type, but also of the disk devices (local, NFS, AFS, etc.).
Simple Analysis Using TTree
We will use the tree in cernstaff.root that was made by the macro in $ROOTSYS/tutorials/tree/staff.C.
First, open the file and lists its contents.
We can see the TTree“T” in the file. We will use it to experiment with the TTree::Draw method, so let’s create a pointer to it:
Cling allows us to get simply the object by using it. Here we define a pointer to a TTree object and assign it the value of “T”, the TTree in the file. Cling looks for an object named “T” in the current ROOT file and returns it (this assumes that “T” has not previously been used to declare a variable or function).
In contrast, in compiled code, you can use:
To show the different Draw options, we create a canvas with four sub-pads. We will use one sub-pad for each Draw command.
We activate the first pad with the TCanvas::cd statement:
We then draw the variable Cost:
In the next segment, we activate the second pad and draw a scatter plot variables:
Using Selection with TTree:Draw
Change the active pad to 3, and add a selection to the list of parameters of the draw command.
This will draw the Costvs. Age for the entries where the nation is equal to “FR”. You can use any C++ operator, and some functions defined in TFormula, in the selection parameter. The value of the selection is used as a weight when filling the histogram. If the expression includes only Boolean operations as in the example above, the result is 0 or 1. If the result is 0, the histogram is not filled. In general, the expression is:
If the Boolean expression evaluates to true, the histogram is filled with a weight. If the weight is not explicitly specified it is assumed to be 1.
For example, this selection will add 1 to the histogram if x is less than y and the square root of z is less than 3.2.
On the other hand, this selection will add x+y to the histogram if the square root of z is larger than 3.2.
The Draw method has its own parser, and it only looks in the current tree for variables. This means that any variable used in the selection must be defined in the tree. You cannot use an arbitrary global variable in the TTree::Draw method.
Using TCut Objects in TTree::Draw
The TTree::Draw method also accepts TCutG objects. A TCut is a specialized string object used for TTree selections. A TCut object has a name and a title. It does not have any data members in addition to what it inherits from TNamed. It only adds a set of operators to do logical string concatenation. For example, assume:
Accessing the Histogram in Batch Mode
The TTree::Draw method creates a histogram called htemp and puts it on the active pad. In a batch program, the histogram htemp created by default, is reachable from the current pad.
If you pipe the result of the TTree::Draw into a histogram, the histogram is also available in the current directory. You can do:
Using Draw Options in TTree::Draw
The next parameter is the draw option for the histogram:
The draw options are the same as for TH1::Draw. See “Draw Options” where they are listed. In addition to the draw options defined in TH1, there are three more. The 'prof' and 'profs' draw a profile histogram (TProfile) rather than a regular 2D histogram (TH2D) from an expression with two variables. If the expression has three variables, a TProfile2D is generated.
The ‘profs’ generates a TProfile with error on the spread. The ‘prof’ option generates a TProfile with error on the mean. The “goff” option suppresses generating the graphics. You can combine the draw options in a list separated by commas. After typing the lines above, you should now have a canvas that looks this.
Superimposing Two Histograms
When superimposing two 2-D histograms inside a script with TTree::Draw and using the “same” option, you will need to update the pad between Draw commands.
{ // superimpose two 2D scatter plots // Create a 2D histogram and fill it with random numbers TH2 *h2 = TH2D (,,,,,,,); ( i = ; i < ; i++) h2->Fill(gRandom->Gaus(,),gRandom->Gaus(,)); // set the color to differentiate it visually h2->SetMarkerColor(kGreen); h2->Draw(); // Open the example file and get the tree TFile f(); TTree *myTree = (TTree*)f.Get(); // the update is needed for the next draw command to work properly gPad->Update(); myTree->Draw(, ,);}In this example, h2->Draw is only adding the object h2 to the pad’s list of primitives. It does not paint the object on the screen. However, TTree::Draw when called with option “same” gets the current pad coordinates to build an intermediate histogram with the right limits. Since nothing has been painted in the pad yet, the pad limits have not been computed. Calling pad->Update() forces the painting of the pad and allows TTree::Draw to compute the right limits for the intermediate histogram.
Setting the Range in TTree::Draw
There are two more optional parameters to the TTree::Draw method: one is the number of entries and the second one is the entry to start with. For example, this command draws 1000 entries starting with entry 100:
TTree::Draw Examples
// Data members and methods tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); // Expressions in the selection parameter tree->Draw(,"fEvtHdr.fEvtNum%10 == 0"); tree->Draw(,"fEvtHdr.fEvtNum%10 == 0"); // Two dimensional arrays defined as: tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw("fMatrix - fVertex"); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); // variable length arrays tree->Draw(); tree->Draw(); // mathematical expressions tree->Draw("sqrt(fPx*fPx + fPy*fPy + fPz*fPz))"); // external function call tree->Draw(); tree->Draw(,type1); tree->Draw(,); // Where fPoints is defined in the track class: // Int_t fNpoint; tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(); tree->Draw(,"(fNvertex>10) && (fNseg<=6000)"); tree->Draw(,); tree->Draw(,"fBx*fBx*(fBx>.4) + fBy*fBy*(fBy<=-.4)"); tree->Draw(,); tree->Draw(); tree->Draw(,); // alphanumeric bin histogram // where Nation is a char* indended to be used as a string tree->Draw(); // where MyByte is a char* intended to be used as a byte tree->Draw("MyByte + 0"); // where fTriggerBits is a data member of TTrack of type TBits tree->Draw(); // using alternate values tree->Draw(); // using meta information about the formula tree->Draw() T->Draw(); T->Scan(,,); tree->Draw(); tree->Draw(); tree->Draw();Explanations:
tree->Draw("fNtrack");
It fills the histogram with the number of tracks for each entry. fNtrack is a member of event.
tree->Draw("event.GetNtrack()");
Same as case 1, but use the method of event to get the number of tracks. When using a method, you can include parameters for the method as long as the parameters are literals.
tree->Draw("GetNtrack()");
Same as case 2, the object of the method is not specified. The command uses the first instance of the GetNtrack method found in the objects stored in the tree. We recommend using this shortcut only if the method name is unique.
tree->Draw("fH.fXaxis.fXmax");
Draw the data member of a data member. In the tree, each entry has a histogram. This command draws the maximum value of the X-axis for each histogram.
tree->Draw("fH.fXaxis.GetXmax()");
Same as case 4, but use the method of a data member.
tree->Draw("fH.GetXaxis().fXmax");
The same as case 4: a data member of a data member retrieved by a method.
tree->Draw("GetHistogram().GetXaxis().GetXmax()");
Same as case 4, but using methods.
tree->Draw("fTracks.fPx","fEvtHdr.fEvtNum%10 == 0");
Use data members in the expression and in the selection parameter to plot fPx or all tracks in every 10th entry. Since fTracks is a TClonesArray of Tracks, there will be d values of fPx for each entry.
tree->Draw("fPx","fEvtHdr.fEvtNum%10 == 0");
Same as case 8, use the name of the data member directly.
tree->Draw("fMatrix");
tree->Draw("fMatrix[ ][ ]");
The same as case 10, all values of fMatrix are drawn for each entry.
tree->Draw("fMatrix[2][2]");
tree->Draw("fMatrix[][0]");
tree->Draw("fMatrix[1][ ]");
tree->Draw("fMatrix - fVertex");
tree->Draw("fMatrix[2][1] - fVertex[5][1]");
This command selects one value per entry.
tree->Draw("fMatrix[ ][1] - fVertex[5][1]");
The first dimension of the array is taken by the fMatrix.
tree->Draw("("fMatrix[2][ ] - fVertex[5][ ]");
The first dimension minimum is 2, and the second dimension minimum is 3 (from fVertex). Three values are selected from each entry:
tree->Draw("fMatrix[ ][2] - fVertex[ ][1]")
This is similar to case 18. Four values are selected from each entry:
tree->Draw("fMatrix[ ][2] - fVertex[ ][ ]")
This is similar to case 19. Twelve values are selected (4×3) from each entry:
tree->Draw("fMatrix[ ][ ] - fVertex[ ][ ]")
This is the same as case 15. The first dimension minimum is 4 (from fMatrix), and the second dimension minimum is 3 (from fVertex). Twelve values are selected from each entry.
tree->Draw("fClosestDistance")
This event data member fClosestDistance is a variable length array:
This command selects all elements, but the number per entry depends on the number of vertices of that entry.
tree->Draw("fClosestDistance[fNvertex/2]")
With this command the element at fNvertex/2 of the fClosestDistancearray is selected. Only one per entry is selected.
tree->Draw("sqrt(fPx*fPx + fPy*fPy + fPz*fPz)")
This command shows the use of a mathematical expression. It draws the square root of the sum of the product.
tree->Draw("TMath::BreitWigner(fPx,3,2)")
The formula can contains call to a function that takes numerical arguments and returns a numerical value. The function needs to be declared to the dictionary and need to be available from the global namespace. In particular, global functions and public static member functions can be called.
tree->Draw("fEvtHdr.fEvtNum","fType=="type1" ")
You can compare strings, using the symbols == and !=, in the first two parameters of the Draw command (TTreeFormula). In this case, the event number for ‘type1’ events is plotted.
tree->Draw("fEvtHdr.fEvtNum","strstr(fType,"1") ")
To compare strings, you can also use strstr. In this case, events having a ‘1’ in fType are selected.
tree->Draw("fTracks.fPoints")
If fPoints is a data member of the Track class declared as:
Int_t fNpoint;
The size of the array fPoints varies with each track of each event. This command draws all the value in the fPoints arrays.
tree->Draw("fTracks.fPoints - fTracks.fPoints[][fAvgPoints]");
When fAvgPoints is a data member of the Event class, this example selects:
tree->Draw("fTracks.fPoints[2][]- fTracks.fPoints[][55]")
For each event, this expression is selected:
tree->Draw("fTracks.fPoints[][] - fTracks.fVertex[][]")
For each event and each track, this expression is selected. It is the difference between fPoints and of fVertex. The number of elements used for each track is the minimum of fNpoint and 3 (the size of the fVertex array).
tree->Draw("fValid&0x1","(fNvertex>10) && (fNseg<=6000)")
tree->Draw("fPx","fBx*fBx*(fBx>.4) + fBy*fBy*(fBy<=-.4)");
The selection argument is used as a weight. The expression returns a multiplier and in case of a Boolean the multiplier is either 0 (for false) or 1 (for true). The first command draws fPx for the range between with conditions on fBx and fBy, the second command draws fPx for the same conditions, but adds a weight using the result of the second expression.
tree->Draw("fVertex","fVertex>10")
When using arrays in the selection and the expression, the selection is applied to each element of the array.
When using a specific element for a variable length array the entries with fewer elements are ignored. Thus these two commands are equivalent.
tree->Draw("Nation")
Nation is a char* branch. When drawing a char* it will plot an alphanumeric histogram, of the different value of the string Nation. The axis will have the Nation values. See “Histograms”.
tree->Draw("MyChar +0")
If you want to plot a char* variable as a byte rather than a string, you can use the syntax above.
tree->Draw("fTracks.fTriggerBits")
fTriggerBits is a data member of TTrack of type TBits. Objects of class TBits can be drawn directly. This command will create a 1D histogram from 0 to nbits which is filled for each non-null bit-number.
tree->Draw("fMatrix-Alt$(fClosestDistance,0)")
tree->Draw("fClosestDistance:Iteration$")
Entry$ : return the current entry number (TTree::GetReadEntry())
Entries$ : return the total number of entries (TTree::GetEntries())
Length$ : return the total number of element of this formula for this entry
Iteration$: return the current iteration over this formula for this entry (i.e. varies from 0 to Length$).
tree->Draw("fLastTrack.GetPx():fLastTrack.fPx");
tree->Scan("((Track*)(fLastTrack@.GetObject())).GetPx()","","");
Will cast the return value of GetObject() (which happens to be TObject* in this case) before requesting the GetPx() member functions.
tree->Draw("This->GetReadEntry()");
tree->Draw("mybr.mystring");
TString and std::string object are plotted directly. The example 45 draws the same results — i.e. an histogram whose labels are the string value of ‘mystring’:
tree->Draw("myTimeStamp");
You can plot plot objects of any class which has either AsDouble or AsString (AsDouble has priority). For such a class (for example TTimeStamp), the line 46 will plot the same as:
AsString can be returning either a char*, or a TString or an std::string.
Multiple variables visualisation
This section presents the visualization technique available in ROOT to represent multiple variables (>4) data sets.
Spider (Radar) Plots
Spider plots (sometimes called “web-plots” or “radar plots”) are used to compare series of data points (events). They use the human ability to spot un-symmetry.

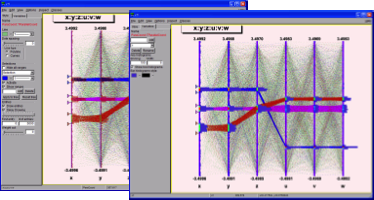
Variables are represented on individual axes displayed along a circle. For each variable the minimum value sits on the circle’s center, and the maximum on the circle’s radius. Spider plots are not suitable for an accurate graph reading since, by their nature, it can be difficult to read out very detailed values, but they give quickly a global view of an event in order to compare it with the others. In ROOT the spider plot facility is accessed from the tree viewer GUI. The variables to be visualized are selected in the tree viewer and can be scanned using the spider plot button.
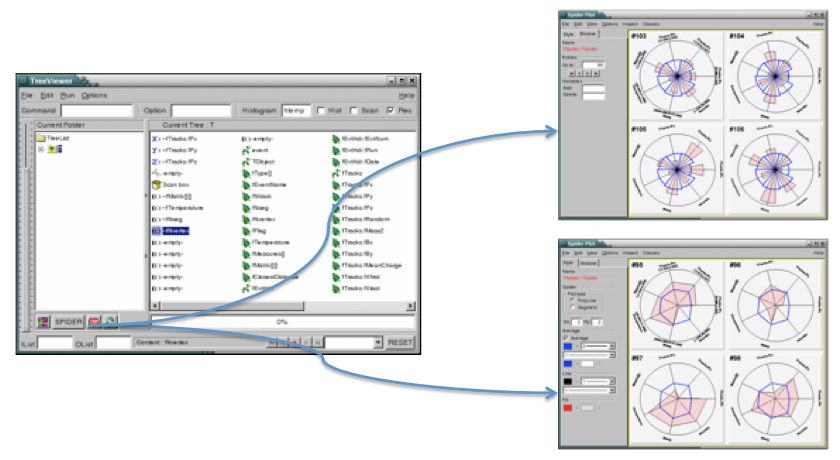
The spider plot graphics editor provides two tabs to interact with the spider plots’ output: the tab “Style” defining the spider layout and the tab “Browse” to navigate in the tree.
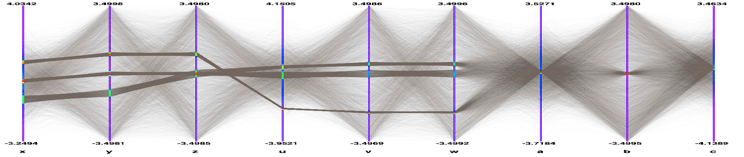
Parallel Coordinates Plots

(-5,3,4,2,0,1).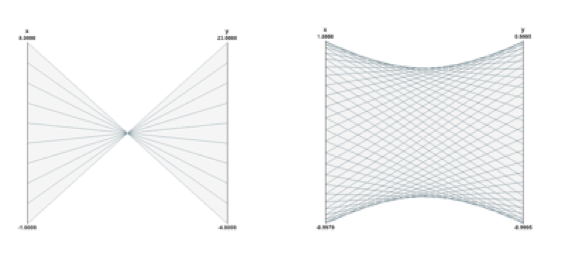
y = -3x+20 and a circle in Parallel Coordinates. parallel_example() { TNtuple *nt = TNtuple(,,); ( i=; i<; i++) { nt->Fill( rnd, rnd, rnd, rnd, rnd, rnd, rnd, rnd, rnd ); nt->Fill( s1x, s1y, s1z, s2x, s2y, s2z, rnd, rnd, rnd ); nt->Fill( rnd, rnd, rnd, rnd, rnd, rnd, rnd, s3y, rnd ); nt->Fill( s2x-, s2y-, s2z, s1x+, s1y+, s1z+, rnd, rnd, rnd ); nt->Fill( rnd, rnd, rnd, rnd, rnd, rnd, rnd, rnd, rnd ); nt->Fill( s1x+, s1y+, s1z+, s3x-, s3y-, s3z-, rnd, rnd, rnd ); nt->Fill( rnd, rnd, rnd, rnd, rnd, rnd, s3x, rnd, s3z ); nt->Fill( rnd, rnd, rnd, rnd, rnd, rnd, rnd, rnd, rnd ); }The data set generated has:
- 9 variables: x, y, z, u, v, w, a, b, c.
- 3000*8 = 24000 events.
- 3 sets of random points distributed on spheres: s1, s2, s3
- Random values (noise): rnd
- The variables a,b,c are almost completely random. The variables a and c are correlated via the 1st and 3rd coordinates of the 3rd “sphere” s3.
The command used to produce the Parallel Coordinates plot is:
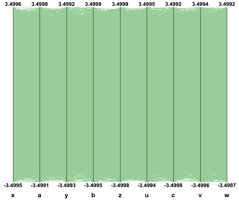
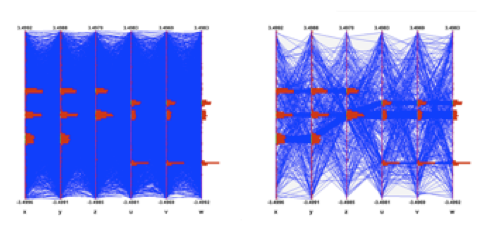
If the 24000 events are plotted as solid lines and no special techniques are used to clarify the picture, the result is the previous picture which is very cluttered and useless. To improve the readability of the Parallel Coordinates output and to explore interactively the data set, many techniques are available. We have implemented a few in ROOT. First of all, in order to show better where the clusters on the various axes are, a 1D histogram is associated to each axis. These histograms (one per axis) are filled according to the number of lines passing through the bins.
These histograms can be represented which colors (get from a palette according to the bin contents) or as bar charts. Both representations can be cumulated on the same plot. This technique allows seeing clearly where the clusters are on an individual axis but it does not give any hints about the correlations between the axes.
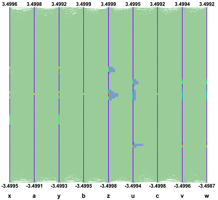
Avery simple technique allows to make the clusters appearing: Instead of painting solid lines we paint dotted lines. The cluttering of each individual line is reduced and the clusters show clearly as we can see on the next figure. The spacing between the dots is a parameter which can be adjusted in order to get the best results.
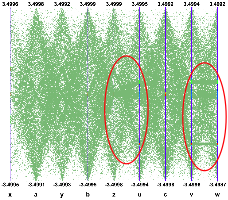
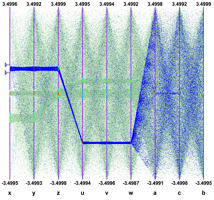
Interactivity is a very important aspect of the Parallel Coordinates plots. To really explore the data set it is essential to act directly with the events and the axes. For instance, changing the axes order may show clusters which were not visible in a different order. On the next figure the axes order has been changed interactively. We can see that many more clusters appear and all the “random spheres” we put in the data set are now clearly visible. Having moved the variables u,v,w after the variables x,y,z the correlation between these two sets of variables is clear also.
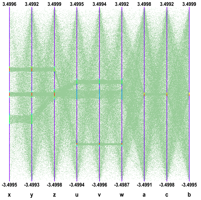
To pursue further data sets exploration we have implemented the possibility to define selections interactively. A selection is a set of ranges combined together. Within a selection, ranges along the same axis are combined with logical OR, and ranges on different axes with logical AND. A selection is displayed on top of the complete data set using its own color. Only the events fulfilling the selection criteria (ranges) are displayed. Ranges are defined interactively using cursors, like on the first axis on the figure. Several selections can be defined at the same time, each selection having its own color.
Several selections can been defined. Each cluster is now clearly visible and the zone with crossing clusters is now understandable whereas, without any selection or with only a single one, it was not easy to understand.
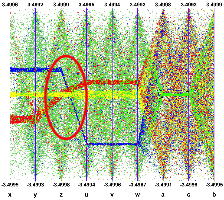
Interactive selections on Parallel Coordinates are a powerful tool because they can be defined graphically on many variables (graphical cuts in ROOT can be defined on two variables only) which allow a very accurate events filtering. Selections allow making precise events choices: a single outlying event is clearly visible when the lines are displayed as “solid” therefore it is easy to make cuts in order to eliminate one single event from a selection. Such selection (to filter one single event) on a scatter plot would be much more difficult.
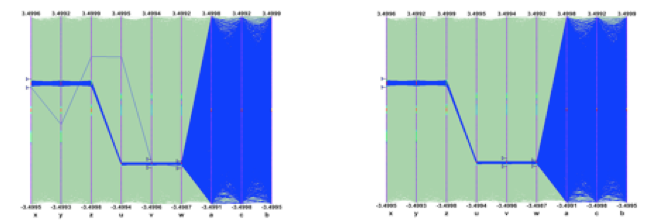
Once a selection has been defined, it is possible to use it to generate a TEntryList which is applied on the tree and used at drawing time. In our example the selection we defined allows to select exactly the two correlated “random spheres”.
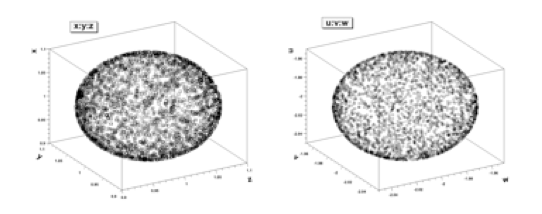 Draw(“x:y:z”) and nt->Draw(“u:v:w”) after applying the selection.»>
Draw(“x:y:z”) and nt->Draw(“u:v:w”) after applying the selection.»>nt->Draw(“x:y:z”) and nt->Draw(“u:v:w”) after applying the selection.- bi is the content of bin crossed by the event on the i-th axis.
- n is the number of axis.
The events having the bigger weights are those belonging to clusters. It is possible to paint only the events having a weight above a given value and the clusters appear. The next example “weight cut” applied on the right plot is 50. Only the events with a weight greater than 50 are displayed.
In case only a few events are displayed, drawing them as smooth curves instead of straight lines helps to differentiate them.
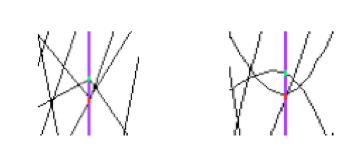
Transparency is very useful with parallel coordinates plots. It allows to show clearly the clusters.
Box (Candle) Plots
A Box Plot (also known as a “box-and whisker” plot or “candle stick” plot) is a convenient way to describe graphically a data distribution (D) with only the five numbers. It was invented in 1977 by John Tukey. The five numbers are:
- The minimum value of the distribution D (Min).
- The lower quartile (Q1): 25% of the data points in D are less than Q1.
- The median (M): 50% of the data points in D are less than M.
- The upper quartile (Q3): 75% of the data points in D are less than Q3.
- The maximum value of the distribution D (Max).
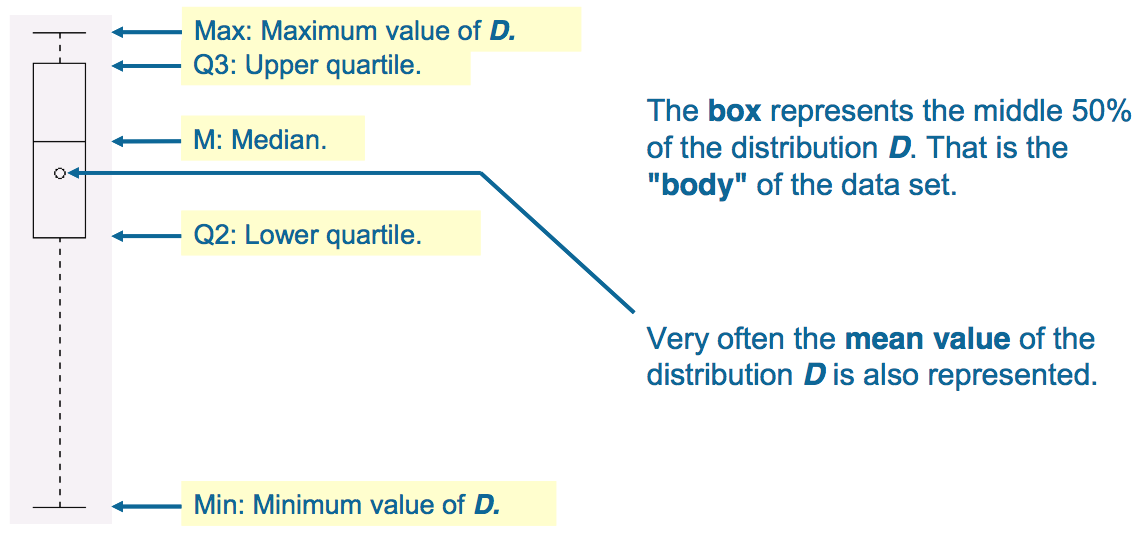
In ROOT Box Plots (Candle Plots) can be produced from a TTree using the “candle” option in TTree::Draw().
Using TTree::Scan
TTree::Scan can be used to print the content of the tree’s entries optional passing a selection.
will print the first 8 variables of the tree.
will print all the variable of the tree.
Specific variables of the tree can be explicit selected by list them in column separated list:
will print the values of var1, var2 and var3. A selection can be applied in the second argument:
will print the values of var1, var2 and var3 for the entries where var1 is exactly 0.
TTree::Scan returns the number of entries passing the selection. By default 50 rows are shown before TTree::Scan pauses and ask you to press the Enter key to see the next 50 rows. You can change the default number of rows to be shown before <CR> via mytree->SetScanfield(maxrows) where maxrows is 50 by default. If maxrows is set to 0 all rows of the Tree are shown. This option is interesting when dumping the contents of a Tree to an ascii file, eg from the command line:
will create a file tree.log.
will results in a printing similar to:
The third parameter of TTree::Scan can be use to specific the layout of the table:
lenmax=dd— where ‘dd’ is the maximum number of elements per array that should be printed. If ‘dd’ is 0, all elements are printed (this is the default).colsize=ss— where ‘ss’ will be used as the default size for all the column. If this options is not specified, the default column size is 9.precision=pp— where ‘pp’ will be used as the default ‘precision’ for the printing format.col=xxx— where ‘xxx’ is colon (:) delimited list of printing format for each column if no format is specified for a column, the default is used.
will print 3 columns, the first 2 columns will be 30 characters long, the third columns will be 20 characters long. The printf format for the columns (assuming they are numbers) will be respectively: %30.3g %30.3g %20.10g.
TEventList and TEntryList
The TTree::Drawmethod can also be used to build a list of the entries. When the first argument is preceded by ">>" ROOT knows that this command is not intended to draw anything, but to save the entries in a list with the name given by the first argument. As a result, a TEventList or a TEntryList object is created in the current directory. For example, to create a TEventList of all entries with more than 600 tracks, do:
To create a TEntryList, use the option “entrylist”.
This list contains the entry number of all entries with more than 600 tracks. To see the entry numbers use the Print("all") command.
When using the “>>” whatever was in the list is overwritten. The list can be grown by using the “>>+” syntax. For example to add the entries, with exactly 600 tracks:
If the Draw command generates duplicate entries, they are not added to the list.
This command does not add any new entries to the list because all entries with more than 610 tracks have already been found by the previous command for entries with more than 600 tracks.
Main Differences between TEventList and TEntryList
and then be used to construct a new TEntryList for a new TChain, or processed independently as normal TEntryList(s) for TTree(s). This modularity makes TEntryList much better suited for PROOF processing than the TEventList.
Using an Event List
A TEventList or a TEntryList can be used to limit the TTree to the events in the list. The methods SetEventList and SetEntryList tell the tree to use the list and hence limit all subsequent calls to Draw, Scan, Process, Query, Principal and CopyTree methods to the entries in the list. In general, it affects the GetEntryNumber method and all functions using it for looping over the tree entries. The GetEntry and GetEntries methods are not affected. Note, that in the SetEventList method, the TEventList argument is internally transformed into a TEntryList, and this operation, in case of a TChain, requires loading of all the tree headers. In this example, we create a list with all entries with more than 600 tracks and then set it so that the tree will use this list. To reset the TTree to use all events use SetEventList(0) or SetEntryList(0).
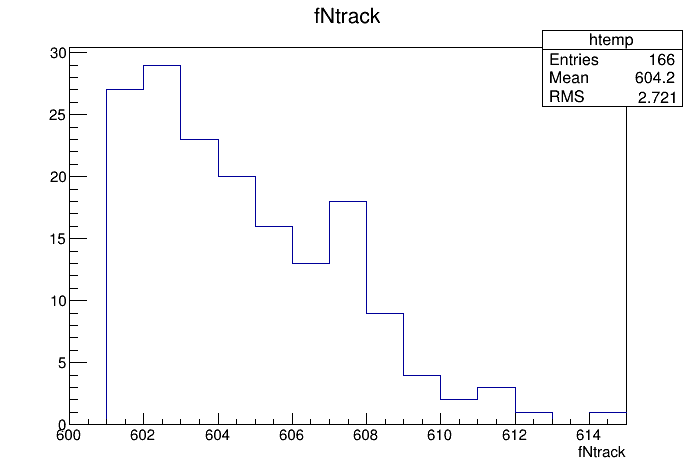
- Let’s look at an example. First, open the file and draw the
fNtrack.
- Now, put the entries with over 600 tracks into a
TEntryListcalledmyList. We get the list from the current directory and assign it to a variable list.
- Instruct the tree
Tto use the new list and draw it again. Note that this is exactly the sameDrawcommand. The list limits the entries.
You should now see a canvas similar to this one.
Operations on TEntryLists
If you have entry lists that were created using different cuts, you can combine the lists to get a new list, with entries passing at least one of the cuts. Example:
list1 now contains entries with more than 600 or less than 590 tracks. Check this by calling:
You can also subtract TEntryList from each other, so that the first list contains only the entries, passing the selection of the first list and not present in the second list.
TEntryListFromFile
This is a special kind of TEntryList, used only when processing TChain objects (see the method TChain::SetEntryListFile()). It is used in the case, when the entry lists, corresponding to the trees of this chain, are stored in separate files. It allows to load the entry lists in memory one by one, keeping only the list for the currently processed tree loaded.
Filling a Histogram
The TTree::Draw method can also be used to fill a specific histogram. The syntax is:
As we can see, this created a TH1, called myHisto. If you want to append more entries to the histogram, you can use this syntax:
If you do not create a histogram ahead of time, ROOT will create one at the time of the Draw command (as is the case above). If you would like to draw the variable into a specific histogram where you, for example, set the range and bin number, you can define the histogram ahead of time and use it in the Draw command. The histogram has to be in the same directory as the tree.
The binning of the newly created histogram can be specified in two ways. You can set a default in the .rootrc and/or you can add the binning information in the TTree::Draw command.
To set number of bins default for the 1-D, 2-D, 3-D histograms can be specified in the .rootrc file via the environment variables, e.g.:
# default binnings Hist.Binning.1D.x: 100
Hist.Binning.2D.x: 40
Hist.Binning.2D.y: 40
Hist.Binning.2D.Prof: 100
Hist.Binning.3D.x: 20
Hist.Binning.3D.y: 20
Hist.Binning.3D.z: 20
Hist.Binning.3D.Profx: 100
Hist.Binning.3D.Profy: 1001 bins in x-direction
2 lower limit in x-direction
3 upper limit in x-direction
4-6 same for y-direction
7-9 same for z-direction
When a bin number is specified, the value becomes the default. Any of the numbers can be skipped. For example:
This works for 1-D, 2-D and 3-D histograms.
Projecting a Histogram
If you would like to fill a histogram, but not draw it you can use the TTree::Project() method.
Making a Profile Histogram
In case of a two dimensional expression, you can generate a TProfile histogram instead of a two dimensional histogram by specifying the 'prof' or ’profs' option. The prof option is automatically selected when the output is redirected into a TProfile. For example y:x>>pf where pfis an existing TProfile histogram.
Tree Information
Once we have drawn a tree, we can get information about the tree. These are the methods used to get information from a drawn tree TTree:
GetSelectedRows: Returns the number of entries accepted by the selection expression. In case where no selection was specified, it returns the number of entries processed.GetV1: Returns a pointer to the float array of the first variable.GetV2: Returns a pointer to the float array of second variableGetV3: Returns a pointer to the float array of third variable.GetW: Returns a pointer to the float array of Weights where the weight equals the result of the selection expression.
Then declare a pointer to a float and use the GetV1 method to retrieve the first dimension of the tree. In this example we only drew one dimension (fNtrack) if we had drawn two, we could use GetV2 to get the second one.
Loop through the first 10 entries and print the values of fNtrack:
By default, TTree::Draw creates these arrays with fEstimate words where fEstimate can be set via TTree::SetEstimate. If you have more entries than fEstimate only the first fEstimate selected entries will be stored in the arrays. The arrays are used as buffers. When fEstimate entries have been processed, ROOT scans the buffers to compute the minimum and maximum of each coordinate and creates the corresponding histograms. You can use these lines to read all entries into these arrays:
Obviously, this will not work if the number of entries is very large. This technique is useful in several cases, for example if you want to draw a graph connecting all the x, y(or z) points. Note that you may have a tree (or chain) with 1 billion entries, but only a few may survive the cuts and will fit without problems in these arrays.
Video Transcription
How does a tree’s root system form and what is its purpose?
DAVE TEUSCHLER, expert:
My name is Dave Teuschler and I’m with BrightView Tree Company. I am the Director of Horticulture and one of the things I do for my work is that I grow small trees and people often ask me why roots are important.
Roots are important because they have four vital functions to the health and vigor of a tree, or any plant for that matter.
Absorption
The root tips, and the root tips only, absorb water and minerals from the surrounding soil.
Conduit
Those roots also conduct water and minerals up into the leaves and up into the trunk of the tree to feed the leaves.
Storage
The roots provide storage. Those big roots are actually carbohydrates stored for use when the tree isn’t actively growing up or isn’t actively in leaf and collecting sunlight and making carbohydrates.
Anchorage
One of the most critical roles roots play is anchorage and a good, healthy, and well-developed root system will anchor a tree for many years.
Tap Roots
A seed’s first job is to produce a tap root, which goes down looking for water. It’s also the initial support for the tree, but as a tree matures, it will focus more on producing lateral roots, or roots out to the side. These roots are absorbing roots and they’re looking for minerals, breaking down organic matter that helps feed the tree.
Finding the Nutrients
I like to say roots are lazy, but that just means they’ll always take the path of least resistance. If there’s water 100 feet that way or water 10 feet that way, they will go get the water that’s 10 feet away. They will not grow through a rock, but will instead grow through the soft, fluffy dirt that you just dug up over here. One of the reasons that you see sidewalks lifted is that there’s a huge water source in that lawn underneath the sidewalk so, again, why grow 100 feet each way down the parkway when 3 feet under the sidewalk, there’s a giant lawn that is nice and moist, full of lots of nutrients from lawn fertilizer and water keeping that lawn green.
Roots are just as important as the top of the tree. The top of the tree is the aesthetic part that we see and we’ve done a lot of work and studying to make sure that the tops of trees are secure and safe for people to live under, but what we often forget is that 50 percent of that tree is underground and in the form of roots and they’re just as important for the health and longevity of a tree. We should always think, «How can I improve the health of my root system if I want to improve the health of my tree?»
Functions of Roots
Roots fill different roles that are essential for the endurance of the plants. They are a vital or incorporated framework that helps the plant in:
- Anchoring: Roots are the explanation plants stay connected to the ground. They support the plant body, guaranteeing that it stands erect.
- Absorption: Primary function of the roots is to assimilate water and break down minerals from the dirt. This is urgent as it helps during the time spent in photosynthesis.
- Storage: Plants get produce food through photosynthesis and save it as starch in the leaves, shoots, and roots. Conspicuous models incorporate carrots, radish, beetroot, and so on.
- Reproduction: Even though roots are not the regenerative piece of plants, they are vegetative parts. In certain plants, the roots are a method for proliferation. For example, new plants emerge from crawling-level stems called sprinters (stolons) in jasmine, grass, and so forth. This kind of multiplication is called the vegetative spread.
- Ecological Function: They actually look at soil disintegration, and give food, and furthermore territory to different organic entities.
Print the Tree Structure with TTree
A helpful command to see the tree structure meaning the number of entries, the branches and the leaves, is TTree::Print.
A Tree with a C Structure
The executable script for this example is $ROOTSYS/tutorials/tree/tree2.C.In this example we show:
- how to build branches from a C structure
- how to make a branch with a fixed length array
- how to make a branch with a variable length array
- how to read selective branches
- how to fill a histogram from a branch
- how to use
TTree::Drawto show a 3D plot
MAXMEC = ;// PARAMETER (MAXMEC=30)// + ,NMEC,LMEC(MAXMEC)// + ,NAMEC(MAXMEC),NSTEP// + ,PID,DESTEP,DESTEL,SAFETY,SLENG// + ,STEP,SNEXT,SFIELD,TOFG,GEKRAT,UPWGHT { vect[]; getot; gekin; vout[]; nmec; lmec[MAXMEC]; namec[MAXMEC]; nstep; pid; destep; destel; safety; sleng; step; snext; sfield; tofg; gekrat; upwght;} ;Writing the Tree
tree2w() { // write tree2 example //create a Tree file tree2.root TFile f(,); //create the file, the Tree TTree t2(,"a Tree with data from a fake Geant3"); // declare a variable of the C structure type gstep; // add the branches for a subset of gstep t2.Branch(,gstep.vect,); t2.Branch(,&gstep.getot,); t2.Branch(,&gstep.gekin,); t2.Branch(,&gstep.nmec,); t2.Branch(,gstep.lmec,); t2.Branch(,&gstep.destep,); t2.Branch(,&gstep.pid,); //Initialize particle parameters at first point px,py,pz,p,charge=; vout[]; mass = ; newParticle = kTRUE; gstep.step = ; gstep.destep = ; gstep.nmec = ; gstep.pid = ; ( i=; i<; i++) { //generate a new particle if necessary (Geant3 emulation) (newParticle) { px = gRandom->Gaus(,); py = gRandom->Gaus(,); pz = gRandom->Gaus(,); p = TMath::Sqrt(px*px+py*py+pz*pz); charge = ; (gRandom->Rndm() < ) charge = -; gstep.pid += ; gstep.vect[] = ; gstep.vect[] = ; gstep.vect[] = ; gstep.vect[] = px/p; gstep.vect[] = py/p; gstep.vect[] = pz/p; gstep.vect[] = p*charge; gstep.getot = TMath::Sqrt(p*p + mass*mass); gstep.gekin = gstep.getot - mass; newParticle = kFALSE; } // fill the Tree with current step parameters t2.Fill(); //transport particle in magnetic field (Geant3 emulation) helixStep(gstep.step, gstep.vect, vout); //make one step //apply energy loss gstep.destep = gstep.step*gRandom->Gaus(,); gstep.gekin -= gstep.destep; gstep.getot = gstep.gekin + mass; gstep.vect[]= charge*TMath::Sqrt(gstep.getot*gstep.getot - mass*mass); gstep.vect[] = vout[]; gstep.vect[] = vout[]; gstep.vect[] = vout[]; gstep.vect[] = vout[]; gstep.vect[] = vout[]; gstep.vect[] = vout[]; gstep.nmec = ()(*gRandom->Rndm()); ( l=; l<gstep.nmec; l++) gstep.lmec[l] = l; (gstep.gekin < ) newParticle = kTRUE; (TMath::Abs(gstep.vect[]) > ) newParticle = kTRUE; } //save the Tree header. The file will be automatically // closed when going out of the function scope t2.Write();}Adding a Branch with a Fixed Length Array
At first, we create a tree and create branches for a subset of variables in the C structureGctrak_t. Then we add several types of branches. The first branch reads seven floating-point values beginning at the address of 'gstep.vect'. You do not need to specify &gstep.vect, because in C and C++ the array variable holds the address of the first element.
Adding a Branch with a Variable Length Array
The next two branches are dependent on each other. The first holds the length of the variable length array and the second holds the variable length array. The lmec branch reads nmec number of integers beginning at the address gstep.lmec.
The variable nmec is a random number and is reset for each entry.
Filling the Tree
In this emulation of Geant3, we generate and transport particles in a magnetic field and store the particle parameters at each tracking step in a ROOT tree.
Analysis
In this analysis, we do not read the entire entry we only read one branch. First, we set the address for the branch to the file dstep, and then we use the TBranch::GetEntry method. Then we fill a histogram with the dstep branch entries, draw it and fit it with a Gaussian. In addition, we draw the particle’s path using the three values in the vector. Here we use the TTree::Draw method. It automatically creates a histogram and plots the 3 expressions (see Trees in Analysis).
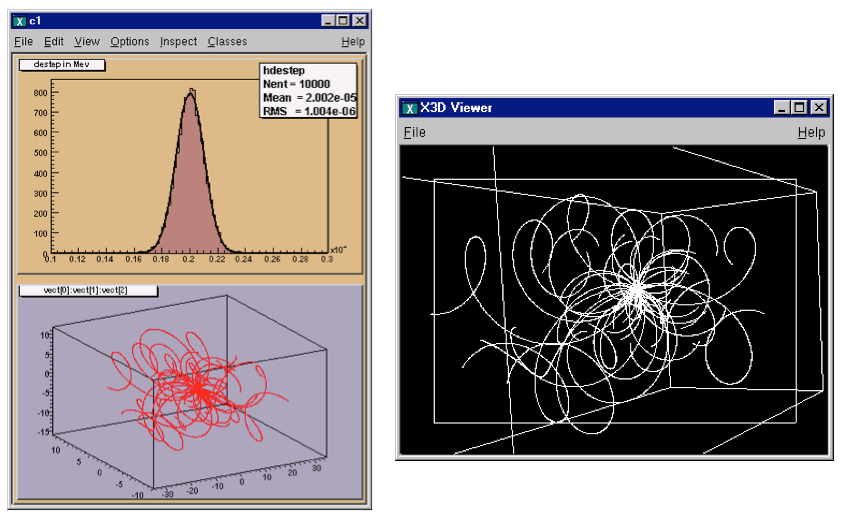
Adding a Branch to Hold a List of Variables
The first parameter is the branch name.
The second parameter is the address from which the first variable is to be read. In the code above, “event” is a structure with one float and three integers and one unsigned integer. You should not assume that the compiler aligns the elements of a structure without gaps. To avoid alignment problems, you need to use structures with same length members. If your structure does not qualify, you need to create one branch for each element of the structure.
The leaf name is NOT used to pick the variable out of the structure, but is only used as the name for the leaf. This means that the list of variables needs to be in a structure in the order described in the third parameter.
This third parameter is a string describing the leaf list. Each leaf has a name and a type separated by a “/” and it is separated from the next leaf by a “:”.
The example on the next line has two leafs: a floating-point number called temp and an integer named ntrack.
The type can be omitted and if no type is given, the same type as the previous variable is assumed. This leaf list has three integers called ntrack, nseg, and nvtex.
There is one more rule: when no type is given for the very first leaf, it becomes a float (F). This leaf list has three floats called temp, mass, and px.
The symbols used for the type are:
C: a character string terminated by the 0 characterB: an 8 bit signed integerb: an 8 bit unsigned integerS: a 16 bit signed integers: a 16 bit unsigned integerI: a 32 bit signed integeri: a 32 bit unsigned integerL: a 64 bit signed integerl: a 64 bit unsigned integerG: a long signed integer, stored as 64 bitg: a long unsigned integer, stored as 64 bitF: a 32 bit floating pointD: a 64 bit floating pointO: [the letter ‘o’, not a zero] a boolean (Bool_t)
By default, a variable will be copied with the number of bytes specified in the type descriptor symbol. However, if the type consists of two characters, the number specifies the number of bytes to be used when copying the variable to the output buffer. The line below describes ntrack to be written as a 16-bit integer (rather than a 32-bit integer).
You can also add an array of variable length:
See “Example 2: A Tree with a C Structure” below ($ROOTSYS/tutorials/tree/tree2.C) and staff.C at the beginning of this chapter.
Orders of Root
Primary Roots
The roots grow directly from the radicle. It is the most important part of the root present in the center. The tap root system is from the primary roots.
Secondary Roots
Lateral roots are the other name for secondary roots. Primary roots give rise to secondary roots.
Tertiary Roots
The tertiary root is raised from the secondary roots. Some of the roots lost the geotropism. The tips of the roots have some root hairs which are covered with root caps.
Root Structure
Historically, developing roots have been categorized into four zones of development. These are not strict zones, but rather regions of cells that gradually develop into those of the next region. The zones vary widely as far as extent and levels of development.
Regions of root development:
- Root cap
- Region of cell division
- Region of elongation
- Region of maturation
We will discuss each region in greater detail.
Root cap
In some plants, the root cap is quite large and obvious, while in others it is nearly impossible to find. The root cap is made of parenchyma cells that form a thimble shape, as a covering for the tip of each root. The cap serves several functions. The main function being protection as the delicate root tip pushes through soil particles. In the outer cells of the root cap, the Golgi bodies secrete a slimy substance that lodges in the walls and eventually pass to the outside. As the cells slough off, replaced from the inside, they form a slimy lubricant that aids root tip movement through the soil. In addition, to aiding movement, the slime is a supportive medium for beneficial bacteria.
The root cap serves in additional capacity in determining the root growth direction. As the root cap has a life span of about one week, it can serve for some interesting experiments. Whether the cap sloughs off or is cut off, the root will grow in random directions, as opposed to downward, until a new root cap is formed. This lends support to the notion that the root cap functions in the perception of gravity. On the sides of the root cap amyloplasts, or plastids containing starch grains, collect facing the direction of gravitational force. In documented experiments, when the root is tipped horizontally from its vertical growing position, the amyloplasts will reshift themselves to the “bottom” of the cells in which they are found. In a short time or 30 minutes to a few hours, the root will resume growing downward. While the exact nature of this gravitational response, or gravitropism, is not fully known, there is some evidence that the calcium ions found in amyloplasts do influence the distribution of growth hormones in plant cells.
Region of cell division
The region of cell division is the next zone in the root cap. The root cap arises from the cells in this zone. This inverted cup-shaped region is composed of an apical meristem at its edges. The cells divide every 12 to 36 hours at the tip of the meristem, while the ones at the base of the meristem may divide once every 200 to 500 hours. Interestingly enough, the divisions are rhythmic and peak usually twice a day around noon and midnight. In the interim, the cells are not usually dividing. Most of the cells in this region are cube-shaped with fairly large nuclei and few, if any, small vacuoles. As in stems as well, the apical meristem in the roots will subdivide and give rise to three meristematic areas: the protoderm, which gives rise to the epidermis; just to the inside of the protoderm, the ground meristem, which produces parenchyma cells of the cortex; and the solid-looking cylinder in the center of the root, the procambium, which produces primary xylem and phloem. The central pith tissue is found in many monocots, such as grasses, but is generally not seen in mature dicot plants due to compression by the vascular cylinder.
Region of elongation
This region is merged with the upper (toward the soil surface), region of the root apical meristem. It is in this region that the cells become several times their original length, and somewhat wider. The tiny vacuoles in each cell will merge and become one or two large vacuoles. In their final state, the enlarged vacuoles will account for up to 90% or more of the cellular volume. As only the root cap and apical meristem are actually moving through the soil, no further increase in cell size occurs above the region of elongation. While the elongated portions of the root generally remain stationary for the rest of their life, if a cambium is present there may be secondary growth and an increase in root girth.
Region of maturation
The region of maturation is sometimes also called the region of differentiation or root-hair zone. In this region, cells mature into the various types of primary tissues. Recall that root hairs are extensions of the epidermis that serve to increase surface area and aid in the absorption of water and soil nutrients. If the region of maturation is examined carefully, it would be noted that the cuticle is very thin on the root hairs and epidermal cells of roots. It is understood that any significant amount of fatty substance would interfere with the ability to absorb water, as fats are hydrophobic—or water-repelling. A root in cross-section would have an epidermis, cortex, endodermis, xylem, phloem, and a pericycle. The cortex is the tissue at the immediate inside of the epidermis that functions in storing food. Generally, the cortex is many cells thick and similar to the cortex of stems, with the exception of the presence of a root endodermis at the inner boundary. In stems, an endodermis is quite rare, while in roots only three species of plants are known to lack a root endodermis. The endodermis is a cylinder formed by a single layer of tightly arranged cells. The primary walls of these cells contain suberin. The waterproof suberin forms bands, called Casparian strips, around the cell walls perpendicular to the root’s surface. The barrier that is formed forces all water and dissolved substances entering and leaving the central tissue core to pass through the plasma membrane or their plasmodesmata. This entire structure serves to regulate the types of minerals absorbed and transported by the root to the stems.
Next to the inside of the endodermis is a cylinder of parenchyma cells called the pericycle. The pericycle is generally one cell wide, however, it can extend for several cells depending on the plant. It is a vital tissue, as the pericycle is the point of origin for the lateral branch roots, and if it is a dicot, part of the vascular cambium. The cells in the pericycle retain their ability to divide even after they have matured. Primary xylem, which contains water-conducting cells, forms at the core of the root and may or may not have observable ‘branches’ which extend like an ‘x’ to the pericycle. The primary phloem, which contains the food conducting cells, fills in the spaces between the branches of xylem. Any branch roots will usually arise in the pericycle opposite the xylem branches.
Chains
The name of the TChain will be the same as the name of the tree; in this case it will be "T". Note that twoobjects can have the same name as long as they are not histograms in the same directory, because there, the histogram names are used to build a hash table. The class TChain is derived from the class TTree. For example, to generate a histogram corresponding to the attribute “x” in tree “T” by processing sequentially the three files of this chain, we can use the TChain::Draw method.
When using a TChain, the branch address(es) must be set with:
TChain::AddFriend
ATChain has a list of friends similar to a tree (see TTree::AddFriend). You can add a friend to a chain with the TChain::AddFriend method. With TChain::GetListOfFriends you can retrieve the list of friends. The next example has four chains each has 20 ROOT trees from 20 ROOT files.
Now we can add the friends to the first chain.
The parameter is the name of friend chain (the name of a chain is always the name of the tree from which it was created). The original chain has access to all variables in its friends. We can use the TChain::Draw method as if the values in the friends were in the original chain. To specify the chain to use in the Draw method, use:
If the variable name is enough to identify uniquely the variable, you can leave out the chain and/or branch name. For example, this generates a 3-d scatter plot of variable “var” in the TChain ch versus variable v1 inTChain t1 versus variable v2 in TChaint2.
When a TChain::Draw is executed, an automatic call to TTree::AddFriendconnects the trees in the chain. When a chain is deleted, its friend elements are also deleted.
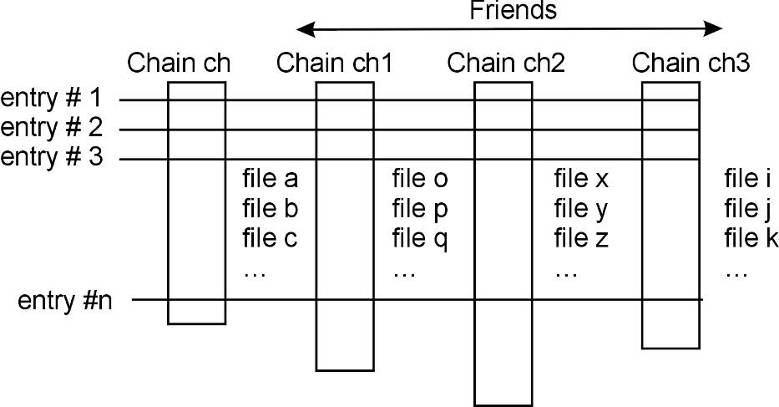
The number of entries in the friend must be equal or greater to the number of entries of the original chain. If the friend has fewer entries a warning is given and the resulting histogram will have missing entries. For additional information see TTree::AddFriends(). A full example of a tree and friends is in Example #3 ($ROOTSYS/tutorials/tree/tree3.C) in the Trees section above.
Characteristics of Root
- Chlorophyll is not present in roots, and because of that, they are not green in color.
- They don’t have nodes and internodes.
- Root hair is present on the roots, which helps in the absorption of nutrients.
- Root shows different types of movements
- Positive Geotrophism-Growth of roots towards gravity.
- Positive Hydrotropism-Growth towards the water.
- Negative Phototropism-Movement of roots away from sunlight.
- Roots are protected via root caps at the tips of the root.
The actual tip of the root is covered by a thimble-formed root cap, which protects the developing tip as it clears its path through the dirt. Apical meristem is present directly under the root cap, a tissue of effectively partitioning cells. A portion of the cells created by the apical meristem are added to the root cap, yet the majority of them are added to the area of extension, which lies simply over the meristematic district.
Structure of Roots
Root Cap
The root is covered at the tip by a thimble-like design. This is known as called a root cap. The root cap protects the delicate root zenith when it clears its path through the dirt.
Region of Meristematic Activity
This area is also known as the region of cell division. This area lies a couple of millimeters over the root cap. This is the district of meristematic action. The cells in this district are tiny and have a slender divider and thick cellular material. Since this is the meristematic area, the cells partition quickly.

Region of Elongation
This area lies over the locale of the meristematic movement. The cells close to this district go through quick extension and growth. These cells are answerable for the development of roots long.
Region of Maturation
This area is simply over the locale of the extension. The cells from the locale of extension separate and mature, and afterward structure the district of development. The root hairs turn out around here. Root hairs are essential for the root epidermis.
Modification of Root
Modification for Food capacity
Tap underlying foundations of turnip and carrot and unusual underlying foundations of yam are instances of alteration of root for food capacity.
Modification for Support
In banyan trees, hanging uncovers come from branches. The hanging roots then go into the dirt to offer extra help to the gigantic banyan tree. Such roots are called prop roots. If there should be an occurrence of a maize plant, uncovers rise up out of the lower hub of the stem and go into the ground. Such roots are called brace roots and offer extra help.
Modified for Respiratory
In plants that fill in swamps, many roots come out upward over the ground. These are empty roots are called pneumatophores. They work with the trade of gases in the roots. Due to waterlogging in swamps, it is beyond the realm of possibilities for roots to inhale air. Pneumatophores make up for this deficiency and permit the trade of gases. Rhizophora is a tree of mangrove timberland, which shows the presence of pneumatophores.
A Simple TTree
This script builds a TTree from an ASCII file containing statistics about the staff at CERN. This script, cernbuild.C and its input file cernstaff.dat are in $ROOTSYS/tutorials/tree.
{ // Simplified version of cernbuild.C. // This macro to read data from an ascii file and // create a root file with a TTree Category; Flag; Age; Service; Children; Grade; Step; Hrweek; Cost; Division[]; Nation[]; *fp = fopen(,); TFile *hfile = hfile = TFile::Open(,); TTree *tree = TTree(,"CERN 1988 staff data"); tree->Branch(,&Category,); tree->Branch(,&Flag,); tree->Branch(,&Age,); tree->Branch(,&Service,); tree->Branch(,&Children,); tree->Branch(,&Grade,); tree->Branch(,&Step,); tree->Branch(,&Hrweek,); tree->Branch(,&Cost,); tree->Branch(,Division,); tree->Branch(,Nation,); line[]; (fgets(line,,fp)) { sscanf(&line[], , &Category,&Flag,&Age,&Service,&Children,&Grade,&Step,&Hrweek,&Cost,Division,Nation); tree->Fill(); } tree->Print(); tree->Write(); fclose(fp); hfile;}The script opens the ASCII file, creates a ROOT file and a TTree. Then it creates branches with the TTree::Branch method. The first parameter of the Branch method is the branch name. The second parameter is the address from which the first leaf is to be read. Once the branches are defined, the script reads the data from the ASCII file into C variables and fills the tree. The ASCII file is closed, and the ROOT file is written to disk saving the tree. Remember, trees (and histograms) are created in the current directory, which is the file in our example. Hence a f->Write()saves the tree.
Differences between Monocot and Dicot roots
Show an Entry with TTree
An easy way to access one entry of a tree is the use the TTree::Show method. For example to look at the 10th entry in the cernstaff.root tree:
")




")