
The root is conventionally indicated using the mathematical symbol √; for instance, the Sanskrit root «» means the root «».
Consider the root √š-m-n (ש-מ-נ).
Although all words vary semantically, the general meaning of a greasy, fatty material can be attributed to the root.
Linguistics is the study of language, and there is a lot to unpack about language, so why not start small? Words are the smallest unit of meaning in a language, right? Guess again! Small segments of sound that carry meaning—many even smaller than words—are called morphemes. There are many types of morphemes that can come together to make a single word.
Morphology is the study of these sub-word sounds and how they function to create meaning in language.
The root of a word is a unit of meaning (morpheme) and, as such, it is an abstraction, though it can usually be represented alphabetically as a word. For example, it can be said that the root of the English verb form running is run, or the root of the Spanish superlative adjective amplísimo is ampli-, since those words are derived from the root forms by simple suffixes that do not alter the roots in any way. In particular, English has very little inflection and a tendency to have words that are identical to their roots. But more complicated inflection, as well as other processes, can obscure the root; for example, the root of mice is mouse (still a valid word), and the root of interrupt is, arguably, rupt, which is not a word in English and only appears in derivational forms (such as disrupt, corrupt, rupture, etc.). The root rupt can be written as if it were a word, but it is not.
This distinction between the word as a unit of speech and the root as a unit of meaning is even more important in the case of languages where roots have many different forms when used in actual words, as is the case in Semitic languages. In these, roots (semitic roots) are formed by consonants alone, and speakers elaborate different words (belonging potentially to different parts of speech) from the root by inserting different vowels. For example, in Hebrew, the root ג-ד-ל g-d-l represents the idea of largeness, and from it we have gadol and gdola (masculine and feminine forms of the adjective «big»), gadal «he grew», higdil «he magnified» and magdelet «magnifier», along with many other words such as godel «size» and migdal «tower».
- Katamba, Francis (2006). Morphology (2nd ed.). Houndsmills, Basingstoke, Hampshire: Palgrave Macmillan. p. 42. ISBN 9781403916440.
- «Root». Glossary of Linguistic Terms. 3 December 2015.
- Kemmer, Suzanne. «Words in English: Structure». Words in English. Retrieved 2018.
- Wehr, Hans (1976). Cowan, J Milton (ed.). Dictionary of Modern Written Arabic (3rd ed.). Ithaca, N.Y.: Spoken Language Services. p. 358. ISBN 0-87950-001-8. Retrieved 2020.
- ^ a b c d Zuckermann, Ghil’ad 2003, Language Contact and Lexical Enrichment in Israeli Hebrew, Houndmills: Palgrave Macmillan. ISBN 1-4039-1723-X. pp 65–66.
- ^ a b c d e f Lohndal, Terje (28 February 2020). «Syntactic Categorization of Roots». Oxford Research Encyclopedia of Linguistics. doi:10.1093/acrefore/9780199384655.013.257. ISBN 978-0-19-938465-5.
- Levinson, Lisa (27 November 2014). «The ontology of roots and verbs». The Syntax of Roots and the Roots of Syntax: 208–229. doi:10.1093/acprof:oso/9780199665266.003.0010. ISBN 978-0199665273.
- Acquaviva, Paolo (May 2009). «Roots and Lexicality in Distributed Morphology». York Papers in Linguistics. University of York. Department of Language and Linguistic Science. 2 (10). hdl:10197/4148.
- Coon, Jessica (1 February 2019). «Building verbs in Chuj: Consequences for the nature of roots». Journal of Linguistics. 55 (1): 35–81. doi:10.1017/S0022226718000087. S2CID 149423392.
- ^ a b c Arad, Maya (2003). «Locality Constraints on the Interpretation of Roots: The Case of Hebrew Denominal Verbs». Natural Language and Linguistic Theory. 21 (4): 737–778. doi:10.1023/A:1025533719905. S2CID 35715020.
- Alexiadou, Artemis; Lohndal, Terje (18 May 2017). «On the division of labor between roots and functional structure». The Verbal Domain. 1. doi:10.1093/oso/9780198767886.003.0004. hdl:.
Secondary roots are roots with changes in them, producing a new word with a slightly different meaning. In English, a rough equivalent would be to see conductor as a secondary root formed from the root to conduct. In abjad languages, the most familiar of which are Arabic and Hebrew, in which families of secondary roots are fundamental to the language, secondary roots are created by changes in the roots’ vowels, by adding or removing the long vowels a, i, u, e and o. (Notice that Arabic does not have the vowels e and o.) In addition, secondary roots can be created by prefixing (m−, t−), infixing (−t−), or suffixing (−i, and several others). There is no rule in these languages on how many secondary roots can be derived from a single root; some roots have few, but other roots have many, not all of which are necessarily in current use.
Consider the Arabic language:
- مركز [mrkz] or [markaza] meaning ‘centralized (masculine, singular)’, from [markaz] ‘centre’, from [rakaza] ‘plant into the earth, stick up (a lance)’ ( ر-ك-ز | r-k-z). This in turn has derived words [markaziy], meaning ‘central’, [markaziy:ah], meaning ‘centralism’ or ‘centralization’, and , [la:markaziy:ah] ‘decentralization’[5]
- أرجح [rjh] or [ta’arjaħa] meaning ‘oscillated (masculine, singular)’, from [‘urju:ħa] ‘swing (n)’, from [rajaħa] ‘weighed down, preponderated (masculine, singular)’ ( ر-ج-ح | r-j-ħ).
- محور [mhwr] or [tamaħwara] meaning ‘centred, focused (masculine, singular)’, from [mihwar] meaning ‘axis’, from [ħa:ra] ‘turned (masculine, singular)’ (ح-و-ر | h-w-r).
- مسخر [msxr], تمسخر [tamasxara] meaning ‘mocked, made fun (masculine, singular)’, from مسخرة [masxara] meaning ‘mockery’, from سخر [saxira] ‘mocked (masculine, singular)’ (derived from س-خ-ر[s-x-r]).»[6] Similar cases may be found in other Semitic languages such as Hebrew, Syriac, Aramaic, Maltese language and to a lesser extent Amharic.
According to Ghil’ad Zuckermann, «this process is morphologically similar to the production of frequentative (iterative) verbs in Latin, for example:
- iactito ‘to toss about’ derives from iacto ‘to boast of, keep bringing up, harass, disturb, throw, cast, fling away’, which in turn derives from iacio ‘to throw, cast’ (from its past participle iactum).[6]
The smallest meaningful unit in a language. A morpheme cannot be divided without altering or destroying its meaning. For example, the English word kind is a morpheme. If the d is removed, it changes to kin, which has a different meaning. Some words consist of one morpheme, e.g. kind, others of more than one. For example, the English word unkindness consists of three morphemes: the STEM1 kind, the negative prefix un-, and the noun-forming suffix -ness. Morphemes can have grammatical functions. For example, in English the –s in she talks is a grammatical morpheme which shows that the verb is the third-person singular present-tense form.
any of the different forms of a MORPHEME. For example, in English the plural morpheme is often shown in writing by adding -s to the end of a word, e.g. cat /kæt/ – cats /kæts/. Sometimes this plural morpheme is pronounced /z/, e.g. dog /díg/ – dogs /dígz/, and sometimes it is pronounced /Iz/, e.g. class /klæs/ – classes /`klæsız/. /s/, /z/, and /Iz/ all have the same grammatical function in these examples, they all show plural; they are all allomorphs of the plural morpheme.
also base form
D. base form
another term for ROOT OR STEM1.
For example, the English word helpful has the base form help.
also base form
that part of a word to which an inflectional AFFIX is or can be added. For example, in English the inflectional affix -s can be added to the stem work to form the plural works in the works of Shakespeare. The stem of a word may be:
a simple stem consisting of only one morpheme (ROOT), e.g. work
a root plus a derivational affix, e.g. work _ -er _ worker
c. two or more roots, e.g. work _ shop _ workshop.
Thus we can have work _ -s _ works, (work _ -er) _ workers, or
_ shop) _ -s _ workshops.
F. Stem versus roots
STEM and ROOT are used to refer to the ‘base’ of a word. The part to which affixes attach. The distinction between them is based on the distinction between inflectional and derivational.
Consider a word like ‘kickers’, it contains two suffixes, one derivational (-er), the other inflectional (-s). strip both affixes off and you are left with kick, which we call a ROOT. Add back on the derivational suffix –er and you get kicker, we call the STEM.

More generally, a root is any single morpheme which is not an affix. Normally, you can find a root by removing all the affixes (both derivational and inflectional) from a word. The stem of a word, on other hand, is found by removing all the inflectional affixes, but leaving any derivational affixes in place.
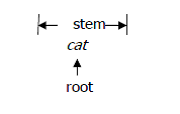
A root is always a single morpheme. A stem on the other hand, may consists of more than one morpheme. Many stems, like cat consists of only a single root. The stem and the root are identical.
other stems consists of two or more roots, as in view-point. Neither view nor point is an affix and both are single morphemes. So they are both considered to be roots.

a stem containing more than one root is called a COMPOUND STEM or simply a COMPOUND; the process of forming such stems is called COMPOUNDING.

and stem may contain more than one derivational affix, as in interlinearizer (a type of computer program that is used by linguists for inserting interlinear word-by-word or morpheme-by-morpheme glosses in a text)

thus, a stem consist of one or more roots, plus zero or more derivational affixes. A root, in contrast, is always a single morpheme.
All stems serve as the base to which inflectional affixes attach. So, for example, all the nouns mentioned above have plural forms.

virtually all roots are also stems and the simplest stems (those consisting of only one morpheme) are also roots.
Главная | Случайная страница | Контакты
Classification of morphemes
Morphemes may be classified from the semantic and structural points of view.
Semantically morphemes fall into two classes: root-morphemes and non-rootmorphemes.
The root-morpheme is the lexical nucleus of a word. It has its individual lexical meaning and all other types of meaning proper to a morpheme except the part-of-speech meaning. The root-morpheme is isolated as the morpheme common to a set of words making up a word-cluster. E.g.: to read, read er, read ing.
Non-root morphemes include inflectional morphemes or inflections and affixational morphemes or affixes.
Inflections carry only grammatical meaning and are used to form word-forms. They are the object of morphology.
Affixes possess a part-of-speech meaning and a generalized lexical meaning and are used for building word-stems and word-formation. The stem is the part of a word that remains unchanged throughout its paradigm. Lexicology is concerned only withaffixational morphemes.
By the position within the word-structure affixes are subdivided into prefixes, suffixes and infixes.
A prefix precedes the root-morpheme; e.g.: dis charge.
An infix is inside the root-morpheme; e.g.: sta n d as compared to stood.
Structurally morphemes fall into three types: free morphemes, bound morphemes and semi-free or semi-bound morphemes.
A free morpheme is defined as the one that coincides with the stem of a word-form. Generally root-morphemes are free morphemes; e.g.: read er, friend ship, ship wreck.
A bound morpheme occurs only as a constituent part of a word. All affixes and unique and pseudo-roots are bound morphemes; e.g.: good ness, dis charge, friend ship, theor y, de ceive.
Semi-free or semi-bound morphemes can function in a morphemic sequence both as an affix and as a free morpheme. E.g.: the morphemes well and half occur as free morphemes that coincide with the stem and the word-form in utterances like sleep well, half an hour. But they occur as bound morphemes in words like well-known, half-done.
There are two more types of morphemes: combining forms and semi-suffixes.
Bound root-morphemes of Latin and Greek origin are called combining forms. E.g.: tele phone, tele graph and micro phone, photo graph.
A semi-suffix is termed as a word-building element formally coinciding with the stem or word-form of a free separate word but acting as an affix. E.g.: cab man, bar- happy.
Segmentable words can allow of the analysis of their word-structure on the morphemic level.
The operation of breaking a segmentable word into the constituent morphemes is referred to as morphological or morphemic analysis, or the analysis of word-structure on the morphemic level.
The morphemic analysis is aimed at splitting a segmentable word into its constituent morphemes and determining their number, types and arrangement.
The procedure employed for segmenting words into constituent morphemes is the method of Immediate (IC s) and Ultimate Constituents (UC s). This method is based on a binary principle. Each stage of the procedure involves two components into which the word immediately breaks. At each stage these two components are referred to as the ICs. Each IC at the next stage of analysis is in turn broken into two smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes which are referred to as the UCs.
The analysis of the morphemic composition of words defines the ultimate meaningful constituents, their number, types, sequence and arrangement within the word-structure.
Chapter 5: Morphology
- Affixes vs roots
- Circumfix
- Infix
- Simultaneous affix
- Free and bound morphemes
- Check your understanding
- References
- Morpheme Types
- Free Morphemes
- Lexical Morphemes
- Functional Morphemes
- Bound Morphemes
- Derivational Morphemes
- Inflectional Morphemes
- Compound words contain at least two root- morphemes, the number of derivational morphemes being insignificant.
- Morphology and Semantics
- Morphology — Key takeaways
- Morphology and Syntax
- Morphology Examples
- WORD STRUCTURE IN MODERN ENGLISH
- Morphology Definition
Affixes vs roots
Morphemes can be of different types, and can come in different shapes. Some morphemes are affixes: they can’t stand on their own, and have to attach to something. The morphemes -s (in cats) and inter– and -al (in international) are all affixes.
The thing an affix attaches to is called a base. Just like whole words, some bases are morphologically simple, while others are morphologically complex.
For example, consider the word librarian. This word is formed by attaching the affix -ian to the base library.
Librarian can then itself be the base for another affix: for example, the word librarianship, the state or role of being a librarian, is formed by attaching the affix -ship to the base librarian.
There is a special name for simple bases: root. A root is the smallest possible base, which cannot be divided, what we might think of as the core of a word. Roots in English we’ve seen so far in this chapter include cat, library, and nation.
If you look at the history of the words library and nation, they both trace back to Latin (by way of French), and in Latin the relevant words were morphologically complex: library traces back to the Latin root libr- (meaning “book”), and nation traces back to the Latin root nat- (meaning “be born”). When a child first encounters a word like library or nation, however, the word doesn’t come annotated with this historical information! In the minds of most contemporary English speakers, it is likely that library and nation are treated as simple roots; in Chapter 13, you’ll learn about how this kind of hypothesis could be tested experimentally.
Turning back to affixes, an affix is any morpheme that needs to attach to a base. We use the term “affix” when we want to refer to all of these together, but we often specify what type of affix we’re talking about.
- A prefix is an affix that attaches before its base, like inter- in international.
- A suffix is an affix that follows its base, like -s in cats.
- A circumfix is an affix that attaches around its base.
- An infix is an affix that attaches inside its base.
- A simultaneous affix is an affix that takes place at the same time as its base.
Prefixes and suffixes are very common, not only in English but also in other languages. Circumfixes, infixes, and simultaneous affixes are less common, and so we’ll look at examples of each in order.
Circumfix
What you can see here is that the singular possessor in “my daughters” is marked only by a prefix, but the plural possessor in “our daughters” is marked by the combination of the prefix ni- and the suffix -ena·n—or, in other words, by a circumfix.
These examples have morpheme-by-morpheme glosses, which means that the morphological analysis has been done for you; in Section 5.11 we’ll discuss how we figure out the boundaries between morphemes in a language we aren’t already familiar with.
Glossed examples include at least three lines: the first line gives the example in the original language, usually in either a phonetic transcription or the language’s own orthography. The second line gives the meaning or function of each word or each morpheme (if the words are divided into morphemes). The third line gives a translation of the whole example into the language the author is writing in, which in this textbook is English.
Morpheme-by-morpheme glosses use standard abbreviations:
- 1 stands for “first person” (I, me, my / we, us, our)
- PL stands for “plural” (so 1PL means “we, us, our”)
- AN stands for “animate”. Algonquian languages distinguish all nouns as “animate” or “inanimate”, and this is reflected in its morphology.
Infix
Infixes are affixes that appear in the middle of another morpheme. For example, in Tagalog (a language with about 24 million speakers, most of them in the Philippines) the infix -um- appears immediately after the first consonant of the base to which it attaches. This infix expresses perfective aspect for verbs. Perfective aspect indicates completed action, usually translated with the English simple past:
For an affix to be an infix, it must appear inside another another morpheme, not just in the middle of a word. If you look at the word unluckiness (un-luck-y-ness), for example, -y is a suffix that just happens to appear in the middle of the word because another suffix (-ness) attaches after it. But -y still isn’t an infix, because it attaches after its base (luck), not inside its base.
Simultaneous affix
Simultaneous affixes are common in signed languages and in languages with tone. When signing, it’s possible to do things with multiple articulators (a second hand, or your face), or to add motion on top of a sign, in a way that is not possible with oral articulations in spoken languages.
For example, in ASL there is a morpheme that attaches to verbs to express continuative aspect (the meaning that something happens continuously for a while, or for a long time). This morpheme involves adding a particular circular motion to the base sign for the verb; this circular motion doesn’t happen before or after the verb, but simultaneously with it. You can see the application of this affix in the first and last videos for the verb STUDY in this linked article from the online Handspeak ASL dictionary (Lapiak 1995–2022) (the second video in that post shows the application of a different simultaneous affix, one for iterative aspect).
There is morphology in some spoken languages that has a similar profile. For example, languages with tone sometimes have tonal morphemes, where a change in tone expresses grammatical information, while the consonants and vowels of the base stay the same.
English isn’t a tonal language, but we have some pairs of words that clearly involve the same root, but where the stress has shifted. These are noun-verb pairs where the noun has stress on the first syllable, but the verb has stress on the second syllable.
Not all English speakers have stress shift in the same pairs of words. For example, while I pronounce address with stress on the first syllable when it’s a noun, many people pronounce it with stress on the second syllable (addréss) for both the noun and the verb.
Free and bound morphemes
Another way to divide morphemes is by whether they are free or bound. A free morpheme is one that can occur as a word on its own. For example, cat is a free morpheme. A bound morpheme, by contrast, can only occur in words if it’s accompanied by one or more other morphemes.
Because affixes by definition need to attach to a base, only roots can be free. In English most roots are free, but we do have a few roots that can’t occur on their own. For example, the root -whelmed, which occurs in overwhelmed and underwhelmed, can’t occur on its own as *whelmed.
By contrast, in many other languages all (or most) roots are bound, because they always have to occur with at least some morphology. This is the case for verbs in French and the other Romance languages, for example; it was also the case for Latin, which is why the roots nat- and libr- were shown with hyphens above.
We show that morphemes are bound by putting hyphens either before or after them, on the side that they attach to other morphemes. This applies to bound roots as well as to affixes.
Check your understanding
References
Lapiak, Jolanta. 1995–2022. Handspeak. https://www.handspeak.com/
Oxford, William R. 2020. Algonquian. In Routledge handbook of North American languages, ed. Daniel Siddiqi , Michael Barrie, Carrie Gillon, and Éric Mathieu. Routledge.
Viewed structurally words appear to be divisible into smaller units which are called morphemes. Morphemes do not occur as free forms but only as constituents of words. The morpheme is the smallest meaningful unit of form. Morphemes cannot be segmented into smaller units without losing their constitutive essence, i.e. association of a certain meaning with a certain sound pattern. Morphemes can have different phonetic shapes, e.g. in such words as ‘please, pleasure, pleasant’ the same morpheme ‘pleas-‘ has different phonetic shapes and these various representations of the morpheme are called allomorphs, or morphemic variants.
Classification of morphemes (semantic and structural). Free and bound morphemes.
Structurally morphemes fall into three types: 1) free morphemes; 2) bound morphemes; 3) semi-bound, or semi-free, morphemes.
Free morphemes are those that coincide with the stem or a word-form. For example, the root-morpheme youth- of the adjective youthful is a free morpheme as it coincides with one of the forms of the word youth.
A bound morpheme occurs only as a constituent part of a word. Affixes are bound morphemes for they always make part of a word, e.g. the suffixes –ment, -ness in the words government, kindness, or the prefixes un-, il- in the words unreal, illegal.
Some root morphemes also belong to the class of bound morphemes. They are as a rule roots which can be found in a small number of words such as goose- in gooseberry or –ceive in conceive, or for example, the word telephone consists of two bound roots of Greek origin – tele- and –phone.
Semi-bound morphemes can function in a morphemic sequence both as an affix and as a free morpheme, e.g. the morphemes well, half, proof are free morphemes coinciding with the stem and the word-form in the word utterances to sing well, half a loaf, the proof of the pudding, on the other hand they occur as bound morphemes in the words well-educated, half-known, waterproof.
Types of words: simple, derived, compound and compound-derived.
According to the number of morphemes words are classified into monomorphic and polymorphic ones. Monomorphic, or root-words, consist only of one root-morpheme (little, doll, baby, make).
Root words mostly belong to the original English stock or to earlier borrowings, such as house, room, book, work, port, street, pen. Modern English has been greatly enlarged by the type of word-building called conversion, e.g. to hand< a hand, to can< a can, to pale < pale (adj.), a go< to go etc.
Polymorphic words according to the number of root-morphemes are classified into a) monoradical, containing one root-morpheme and b) polyradical, consisting of two or more roots.
Monoradical words fall into:
1) radical-suffixal words, such as acceptable, acceptability;
2) radical-prefixal words, such as unbutton, reread;
3) prefixo-radical-suffixal words, such as disagreeable, misinterpretation.
Words which consist of a root and an affix (or several affixes) are called derived words, or derivatives, and are produced by the process of word-building known as affixation or derivation.
Derived words are numerous in the English language successfully competing with root words.
Polyradical words fall into:
1) polyradical words consisting of two or more roots with no affixational morphemes, such as bookstall, lampshade;
2) polyradical words containing at least two roots and one or more affixational morphemes, such as safety-pin, handwriting.
This wide-spread word structure is a compound word consisting of two or more stems, i.e. part of the word formed by a root and an affix /affixes. In English words roots and stems can often coincide, e.g. dining-room, bluebell, mother-in-law etc. words of this type are produced by the word-building process called composition.
Such words as ‘pram, flu, doc, M.P., H-bomb’ are called shortenings, contractions or curtailed words and are produced by the way of word-building called shortening, or contraction.
Root-words, derivatives, compounds and shortenings represent the main structural types of modern English words and conversion, derivation and composition are the most productive ways of word-building.
Classification of compounds.
According to the relations between the ICs compound words fall into two classes: 1) coordinative compounds and 2) subordinative compounds.
In coordinative compounds the two ICs are semantically equally important. There are three groups in coordinative compounds:
a) reduplicative compounds which are made up by the repetition of the same base, e.g. pooh-pooh, fifty-fifty;
b) compounds formed by joining the phonetically variated rhythmic twin forms, e.g. chit-chat, zig-zag, walkie-talkie, dilly-dally, riff-raff, ping-pong;
c) additive compounds which are built on stems of the independently functioning words of the same part of speech, e.g. actor-manager, queen-bee.
In subordinative compounds the components are neither structurally nor semantically equal in importance but are based on the domination of the head member which is as a rule the second IC, e.g. stone-deaf, age-long. The second IC preconditions the part-of-speech meaning of the whole compound.
According to the part of speech compounds represent, they fall into: 1) compound nouns, e.g. sunrise, housemaid; 2) compound adjectives, e.g. care-free, far-going; 3) compound pronouns, e.g. somebody, anybody; 4) compound adverbs, e.g. nowhere, inside; 5) compound verbs, e.g. to bypass, to mass-produce.
From the diachronic point of view many compound verbs of the present-day language are treated not as compounds proper but as polymorphic verbs of secondary derivation. They are called pseudo-compounds and are represented by two groups: a) verbs formed by means of conversion from the stems of compound nouns, e.g. to spotlight (>spotlight, n.); b) verbs formed by back-derivation from the stems of compound nouns, e.g. to babysit (>baby-sitter).
However synchronically compound verbs correspond to the definition of a compound as a word consisting of two free stems and functioning in the sentence as a separate lexical unit.
According to the means of composition compound words are classified into: 1) compounds composed without connecting elements, e.g. backache, school girl; 2) compounds composed with the help of a linking vowel or consonant, e.g. salesgirl, handicraft; 3) compounds composed with the help of linking elements represented by preposition or conjunction stems, e.g. son-in-law, pepper-and-salt.
According to the type of bases that form compounds two classes can be singled out: 1) compounds proper that are formed by joining together bases built on the stems or on the word-forms with or without a linking element, e.g. door-step, street-fighting; 2) derivational compounds that are formed by joining affixes to the bases built on the word-groups or by converting the bases built on the word-groups into other parts of speech, e.g. blue-eyed < (blue eyes) + -ed, a turnkey< (to turn key) + conversion. Thus derivational compounds fall into two groups: a) derivational compounds mainly formed with the help of suffixes –ed and –er applied to bases built on attributive phrases, e.g. doll-faced, left-hander; b) derivational compounds formed by conversion applied to bases built on three types of phrases – verbal-adverbial (a breakdown), verbal-nominal (a kill-joy) and attributive (a sweet-tooth).

Мы поможем в написании ваших работ!
Главная | Случайная страница | Контакты
Root morphemes carry the lexical meaning of the word. Affixational morphemes fall into derivational morphemes, which carry the lexico-grammatical meaning and serve to form new words, and functional morphemes having grammatical meaning (inflexions). Lexicology deals only with roots and derivational affixes, while inflexions are studied by grammar. Root and derivational morphemes constitute the stem of the word.
Roots are usually free morphemes: they often coincide with independently functioning words: pen, walk, good. Some roots may be bound as well: they may not coincide with separate word-forms as in poss ible, for ty. All affixes are bound morphem-es. There are also semi-affixes which stand between roots and derivational morphemes: fire proof, water proof, kiss proof, lady like, business like, star like, etc.; -worthy, -man, -ful, etc.).
As far as the morphemic composition of words is concerned, words are classified into monomorphic and polymorphic. Monomorphic words consist of one morpheme – the root morpheme only. These words are called simple: dog, cat, boy, girl, etc. Polymorphic words consist of a root and one or several affixes or of two or several root morphemes. Accordingly, polymorphic words fall into three subgroups:
1) derived words, which contain a root and one or several affixes: hardship, unbelievable.
2) compound words, which consist of at least two root morphemes: handbag, merry-go-round.
3) compound derivatives, or derivational compounds, which are constituted by two or more roots modified by an affix: old-maidish, long-nosed.
Simple words are the most frequent lexical units in English. The most widely used words, such as pronouns, prepositions, conjunctions, articles, are simple words. The least frequent in usage are compound words, though their number is steadily growing.
Some words that were compound in Old English are known as simple words in Modern English: woman – OE wif+man, window – OE wind+eage, etc. This process is named the simplification of the stem (опрощение морфологической структуры слова).
There are three levels of analysis of the morphological structure of the word.
1. Morphemic analysis, which states the number of morphemes in a word and their types. At this level, the word friendliness, for instance, is characterized as a word containing three morphemes: one root morpheme (friend) and two derivational morphemes (ly, ness).
2. Derivational analysis, which reveals the pattern according to which the word is built. Thus, the word friendliness is built by adding to the stem friendly the suffix ness (not friend + liness as there is no suffix liness in English). Derivational analysis shows the structural correlation of the word with other words: friendly vs friendliness = happy vs happiness = easy vs easiness, etc.
3. Analysis into Immediate Constituents (непосредственные составляющие), which reveals the history of the word, the stages of the process of its formation. The analysis is binary: at each stage we split the word into two constituents. Thus, the word friendliness is first divided into friendly and ness, then the part friendly is further subdivided into friend and ly. So, the Ultimate Constituents (конечные составляющие) look this way: friend+ly+ness. The results of the analysis coincide with the result of the morphemic analysis of the same word.
The most productive ways of word-building in Modern English are:
The types of word-building that are less productive are sound imitation and reduplication.
The ways of word-formation that are non-productive are sound and stress interchange.
Affixation is building new words by adding affixes to the stem of the word. The two main types of affixation are prefixation and suffixation.
Affixes can be classified according to different principles.
According to the part of speech formed affixes (suffixes, to be exact) are divided into noun-forming (-er, -ness, -ship, -hood, -ance, -ist, etc.), adjective-forming (-ful, -less, -ic, — al, -able, -ate, -ish, -ous, etc.), verb-forming (-en, -ate, -fy, — ize, etc.), adverb-forming (-ly, -wide, etc.).
According to their origin affixes are classified into native and borrowed. The native suffixes are -er, -ed, -dom, -en, -ful, -less, -hood, -let, -ly, -ness, -ship, -some, -teen, -th, -y, ward, -wise, -lock. Prefixes: un-, mis-, up-, under-, over-, out-.
Borrowed affixes are by their origin Latin (-or, -ant, -able), French (-ard, -ance, -ate), or Greek (-ist, -ism, -oid). There exist numerous prefixes of Latin and Greek origin used to form new words in English: anti-, contra-, sub-, super-, post-, vice-, etc.
According to their productivity (the ability to form new words) affixes may be divided into productive (- er, -ish, -less, etc.) and non-productive (- ard, -ive, -th, -ous, fore-, etc.). Productive affixes are always frequent, but not every frequent affix is productive (- ous, for example, is a very frequent affix as it is found in many words, but it is not productive).
According to their connotational characteristics affixes may be emotionally coloured (stink ard, drunk ard, gang ster, young ster, etc. – derogatory emotional charge) and neutral (-er, able, -ing); stylistically marked (ultra-, -oid, -eme, -tron, etc. – bookish) and neutral (-er, able, -ing).
The semantic relations between the members of converted pairs are various.
Composition consists in making new words by combining two or more stems which occur in the language as free forms. It is most characteristic of adjectives and nouns. Compound words may be divided into several groups.
According to the type of composition compounds are divided into those formed by juxtaposition without linking elements (skyblue), into compounds with a linking vowel or consonant (Anglo-saxon, saleswoman) and compounds with a linking element represented by a preposition or conjunction (up-to-date, bread-and-butter). Compounds may also be formed by lexicalized phrases: forget-me-not, stick-in-the-mud (отсталый, безынициативный). Such words are called syntactic compounds. There also exist derivational compounds (compound derivatives) which represent the structural integrity of two free stems with a suffix referring to the combination as a whole: honey-mooner, teen-ager, kind-hearted.
According to the structure of their ICs compounds are classified into those containing:
1) two simple stems: pen-knife, bookcase;
2) one derived stem: chainsmoker, cinema-going;
3) one clipped stem: B-girl, H-bomb;
4) one compound stem: wastepaper-basket.
There is a problem of differentiation of compounds and homonymous word combinations. There are five criteria which help to solve this problem:
1) graphical criterion: the majority of English words are spelled either solidly or are hyphenated;
2) phonological criterion: compounds usually have a heavy stress on the first syllable (cf.: ` blackbird vs ` black ` bird);
3) semantic criterion: the meaning of a compound word is not a total sum of the meanings of its components but something different. There are compound words the semantic motivation of which is quite clear (table-cloth, shipwreck, etc.), but many compounds are idiomatic (non-motivated): butterfinger (a person who can’t do things well), blue-stocking (a pedantic woman);
4) morphological criterion (criterion of formal integrity (A. I. Smirnitsky)): a compound word has a paradigm of its own: inflexions are added not to each component but to the whole compound (handbags, handbag’s)
5) syntactic criterion: the whole compound but not its components fulfils a certain syntactic function. Nothing can be inserted between the components of a compound word.
It should be noted that a single criterion is not sufficient to state whether we deal with a compound word or a combination of words.
More than ⅓ of neologisms in English are compound words, so it’s a highly productive way of word-building.
Shortening (Clipping or Curtailment) is building new words by subtraction (отнятие, удаление) of a part of the original word. Shortenings are produced in two main ways: a) by clipping some part of the word; b) by making a new word from the initial letters of a word group.
According to the position of the omitted part, shortenings are classified into those formed by:
According to their reading, initial shortenings, or abbreviations are classified into:
1) abbreviations which are pronounced as a series of letters: FBI, CIA, NBA (National Basketball Association), etc.
2) abbreviations which are read as ordinary English words (acronyms): UNO, NATO, radar (radio detection and ranging), etc.
A special group is represented by graphical abbreviations used in written speech: N.Y., X-mas, PhD, etc. A number of Latin abbreviations are used in writing: e.g., p.m., i.e., P.S., etc.
The minor ways of word-building are blending, sound imitation, reduplication and ellipsis.
Blending is a way bulding words by merging parts of words (not morphemes) into one new word. Thus, the noun smog is composed of the parts of the nouns smoke and fog, the noun brunch – of breakfast and lunch, motel – of motor and hotel. Such words are called blends (сращения), fusions, telescope words.
Reduplication (Repetition) consists in a complete or partial repetition of the stem or of the whole word (bye-bye), often with a variation of the root vowel or consonant (ping-pong
These words are always colloqual or slang, among them there many nursery words. There exist three types of such words: 1) the words in which the same stem is repeated without any changes (pretty-pretty, goody-goody, never-never (утопия); 2) words with a vowel variation (chit-chat (сплетни), ping-pong, tip-top); 3) words with pseudomorphemes (rhyme combinations) (lovey-dovey, walkie-talkie, willy-nilly); the parts of such words don’t exist as separate words.
Non-productive ways of word-building are sound interchange and distinctive stress which are regarded as a means of word-building only diachronically because in Mod. English not a single word is formed by changing the root sound or by shifting the place of stress.
Distinctive stress is found in groups like `present – pres`ent, `conduct – con`duct, `abstract – abstr’act, etc. These words were French borrowings with the original stress on the last syllable. Verbs retained it, while in nouns and adjectives it was shifted. The place of stress helps to distinguish verbs and nouns or pronouns in speech
Morpheme Types
There are two major types of morphemes: free morphemes and bound morphemes. The smallest example is made up of one of each of these types of morphemes.
Small – is a free morpheme
-est – is a bound morpheme
Free Morphemes
A free morpheme is a morpheme that occurs alone and carries meaning as a word. Free morphemes are also called unbound or freestanding morphemes. You might also call a free morpheme a root word, which is the irreducible core of a single word.
These examples are all free morphemes because they cannot be subdivided into smaller pieces that hold significance. Free morphemes can be any type of word—whether an adjective, a noun, or anything else—they simply have to stand alone as a unit of language that conveys meaning.
You might be tempted to say that free morphemes are simply all words and leave it at that. This is true, but free morphemes are actually categorized as either lexical or functional according to how they function.
Lexical Morphemes
Lexical morphemes carry the content or meaning of a message.
You might think of them as the substance of language. To identify a lexical morpheme, ask yourself, “If I deleted this morpheme from the sentence, would it lose its meaning?” If this answer is yes, then you almost certainly have a lexical morpheme.
Functional Morphemes
As opposed to lexical morphemes, functional morphemes do not carry the content of a message. These are the words in a sentence that are more functional, meaning that they coordinate the meaningful words.
Remember that functional morphemes are still free morphemes, which means they can stand alone as a word with meaning. You wouldn’t categorize a morpheme such as re- or -un as a grammatical morpheme because they aren’t words that stand alone with meaning.
Bound Morphemes
Unlike lexical morphemes, bound morphemes are those that cannot stand alone with meaning. Bound morphemes must occur with other morphemes to create a complete word.
Many bound morphemes are affixes.
An affix is an additional segment added to a root word to change its meaning. An affix may be added to the beginning (prefix) or the end (suffix) of a word.
Not all bound morphemes are affixes, but they are certainly the most common form. Here are a few examples of affixes you might see:
Bound morphemes can do one of two things: they can change the grammatical category of the root word (derivational morpheme), or they can simply alter its form (inflectional morpheme).
Derivational Morphemes
When a morpheme changes the way you’d categorize the root word grammatically, it’s a derivational morpheme.
Poor (adjective) + ly (derivational morpheme) = poorly (adverb)
The root word poor is an adjective, but when you add the suffix -ly—which is a derivational morpheme—it changes to an adverb. Other examples of derivational morphemes include -ness, non-, and -ful.
Inflectional Morphemes
When a bound morpheme is attached to a word but does not change the root word’s grammatical category, it is an inflectional morpheme. These morphemes simply modify the root word in some way.
Fireplace + s = fireplaces
Adding the -s to the end of the word fireplace did not change the word in any significant way—it simply modified it to reflect multiple rather than one single fireplace.
Compound words contain at least two root- morphemes, the number of derivational morphemes being insignificant.
Derivational compound is a word formed by a simultaneous process of composition and derivational.
Compound words proper are formed by joining together stems of word already available in the language.
Morphology and Semantics
Semantics is one level removed from morphology in the grand scheme of linguistic study. Semantics is the branch of linguistics responsible for understanding meaning in general. To understand the meaning of a word, phrase, sentence, or text, you might rely on semantics.
Morphology also deals with meaning to a degree, but only in as much as the smaller sub-word units of language can carry meaning. To examine the meaning of anything larger than a morpheme would fall under the domain of semantics.
Morphology — Key takeaways
- Morphology is the study of the smallest segments of language that carry meaning.
- Morphemes are the smallest units of language that have meaning and can’t be further subdivided.
- There are two main types of morphemes: bound and free.
- Bound morphemes must be combined with another morpheme to create a word.
- Free morphemes can stand alone as a word.
Morphology and Syntax
Morphology and syntax are close to one another in terms of the linguistic domain. While morphology studies the smallest units of meaning in language, syntax deals with how words are linked together to create meaning.
The difference between syntax and morphology is essentially the difference between studying how words are formed (morphology) and how sentences are formed (syntax).
Morphology Examples
Sometimes it’s easier to see a visual representation of something than to explain it. Morphological trees do exactly that.
Unreachable – the inability to be reached or contacted
Un (inflectional morpheme) reach (lexical morpheme) able (free morpheme)
This example shows how the word unreachable can be broken into individual morphemes.
The morpheme able is an affix that changes the word reach (a verb) to reachable (an adjective.) This makes it a derivational morpheme.
After you add the affix un- you get the word unreachable which is the same grammatical category (adjective) as reachable, and so this is an inflectional morpheme.
Motivation – the reason or reasons why someone does something
Motiv (lexical morpheme) ate (derivational morpheme) ion (derivational morpheme)
The root word is motive (a noun) which, with the addition of the affix —ate becomes motivate (a verb). The addition of the bound morpheme —ion changes the verb motivate to the noun motivation.
WORD STRUCTURE IN MODERN ENGLISH
I. The morphological structure of a word. Morphemes. Types of morphemes. Allomorphs.
II. Structural types of words.
III. Principles of morphemic analysis.
IV. Derivational level of analysis. Stems. Types of stems. Derivational types of words.
I. The morphological structure of a word. Morphemes. Types of Morphemes. Allomorphs.
There are two levels of approach to the study of word- structure: the level of morphemic analysis and the level of derivational or word-formation analysis.
Word is the principal and basic unit of the language system, the largest on the morphologic and the smallest on the syntactic plane of linguistic analysis.
It has been universally acknowledged that a great many words have a composite nature and are made up of morphemes, the basic units on the morphemic level, which are defined as the smallest indivisible two-facet language units.
The term morpheme is derived from Greek morphe “form ”+ -eme. The Greek suffix –eme has been adopted by linguistic to denote the smallest unit or the minimum distinctive feature.
The morpheme is the smallest meaningful unit of form. A form in these cases a recurring discrete unit of speech. Morphemes occur in speech only as constituent parts of words, not independently, although a word may consist of single morpheme. Even a cursory examination of the morphemic structure of English words reveals that they are composed of morphemes of different types: root-morphemes and affixational morphemes. Words that consist of a root and an affix are called derived words or derivatives and are produced by the process of word building known as affixation (or derivation).
The root-morpheme is the lexical nucleus of the word; it has a very general and abstract lexical meaning common to a set of semantically related words constituting one word-cluster, e.g. (to) teach, teacher, teaching. Besides the lexical meaning root-morphemes possess all other types of meaning proper to morphemes except the part-of-speech meaning which is not found in roots.
Affixational morphemes include inflectional affixes or inflections and derivational affixes. Inflections carry only grammatical meaning and are thus relevant only for the formation of word-forms. Derivational affixes are relevant for building various types of words. They are lexically always dependent on the root which they modify. They possess the same types of meaning as found in roots, but unlike root-morphemes most of them have the part-of-speech meaning which makes them structurally the important part of the word as they condition the lexico-grammatical class the word belongs to. Due to this component of their meaning the derivational affixes are classified into affixes building different parts of speech: nouns, verbs, adjectives or adverbs.
Roots and derivational affixes are generally easily distinguished and the difference between them is clearly felt as, e.g., in the words helpless, handy, blackness, Londoner, refill, etc.: the root-morphemes help-, hand-, black-, London-, fill-, are understood as the lexical centers of the words, and –less, -y, -ness, -er, re- are felt as morphemes dependent on these roots.
Distinction is also made of free and bound morphemes.
It should also be noted that morphemes may have different phonemic shapes. In the word-cluster please , pleasing , pleasure , pleasant the phonemic shapes of the word stand in complementary distribution or in alternation with each other. All the representations of the given morpheme, that manifest alternation are called allomorphs/or morphemic variants/ of that morpheme.
The combining form allo- from Greek allos “other” is used in linguistic terminology to denote elements of a group whose members together consistute a structural unit of the language (allophones, allomorphs). Thus, for example, -ion/ -tion/ -sion/ -ation are the positional variants of the same suffix, they do not differ in meaning or function but show a slight difference in sound form depending on the final phoneme of the preceding stem. They are considered as variants of one and the same morpheme and called its allomorphs.
Allomorph is defined as a positional variant of a morpheme occurring in a specific environment and so characterized by complementary description.
Complementary distribution is said to take place, when two linguistic variants cannot appear in the same environment.
Different morphemes are characterized by contrastive distribution, i.e. if they occur in the same environment they signal different meanings. The suffixes –able and –ed, for instance, are different morphemes, not allomorphs, because adjectives in –able mean “ capable of beings”.
Allomorphs will also occur among prefixes. Their form then depends on the initials of the stem with which they will assimilate.
Two or more sound forms of a stem existing under conditions of complementary distribution may also be regarded as allomorphs, as, for instance, in long a: length n.
II. Structural types of words.
The morphological analysis of word- structure on the morphemic level aims at splitting the word into its constituent morphemes – the basic units at this level of analysis – and at determining their number and types. The four types (root words, derived words, compound, shortenings) represent the main structural types of Modern English words, and conversion, derivation and composition the most productive ways of word building.
According to the number of morphemes words can be classified into monomorphic and polymorphic. Monomorphic or root-words consist of only one root-morpheme, e.g. small, dog, make, give, etc. All polymorphic word fall into two subgroups: derived words and compound words – according to the number of root-morphemes they have. Derived words are composed of one root-morpheme and one or more derivational morphemes, e.g. acceptable, outdo, disagreeable, etc. Compound words are those which contain at least two root-morphemes, the number of derivational morphemes being insignificant. There can be both root- and derivational morphemes in compounds as in pen-holder, light-mindedness, or only root-morphemes as in lamp-shade, eye-ball, etc.
These structural types are not of equal importance. The clue to the correct understanding of their comparative value lies in a careful consideration of: 1)the importance of each type in the existing wordstock, and 2) their frequency value in actual speech. Frequency is by far the most important factor. According to the available word counts made in different parts of speech, we find that derived words numerically constitute the largest class of words in the existing wordstock; derived nouns comprise approximately 67% of the total number, adjectives about 86%, whereas compound nouns make about 15% and adjectives about 4%. Root words come to 18% in nouns, i.e. a trifle more than the number of compound words; adjectives root words come to approximately 12%.
But we cannot fail to perceive that root-words occupy a predominant place. In English, according to the recent frequency counts, about 60% of the total number of nouns and 62% of the total number of adjectives in current use are root-words. Of the total number of adjectives and nouns, derived words comprise about 38% and 37% respectively while compound words comprise an insignificant 2% in nouns and 0.2% in adjectives. Thus it is the root-words that constitute the foundation and the backbone of the vocabulary and that are of paramount importance in speech. It should also be mentioned that root words are characterized by a high degree of collocability and a complex variety of meanings in contrast with words of other structural types whose semantic structures are much poorer. Root- words also serve as parent forms for all types of derived and compound words.
III. Principles of morphemic analysis.
In most cases the morphemic structure of words is transparent enough and individual morphemes clearly stand out within the word. The segmentation of words is generally carried out according to the method of Immediate and Ultimate Constituents. This method is based on the binary principle, i.e. each stage of the procedure involves two components the word immediately breaks into. At each stage these two components are referred to as the Immediate Constituents. Each Immediate Constituent at the next stage of analysis is in turn broken into smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes. These are referred to Ultimate Constituents.
A synchronic morphological analysis is most effectively accomplished by the procedure known as the analysis into Immediate Constituents. ICs are the two meaningful parts forming a large linguistic unity.
Breaking a word into its Immediate Constituents we observe in each cut the structural order of the constituents.
1. un- / gentlemanly
2. un- / gentleman / — ly
3. un- / gentle / — man / — ly
4. un- / gentl / — e / — man / — ly
A similar analysis on the word-formation level showing not only the morphemic constituents of the word but also the structural pattern on which it is built.
Morphemic analysis under the method of Ultimate Constituents may be carried out on the basis of two principles: the so-called root-principle and affix principle.
According to the affix principle the splitting of the word into its constituent morphemes is based on the identification of the affix within a set of words, e.g. the identification of the suffix –er leads to the segmentation of words singer, teacher, swimmer into the derivational morpheme – er and the roots teach- , sing-, drive-.
According to the root-principle, the segmentation of the word is based on the identification of the root-morpheme in a word-cluster, for example the identification of the root-morpheme agree- in the words agreeable, agreement, disagree.
As a rule, the application of these principles is sufficient for the morphemic segmentation of words.
IV. Derivational level of analysis. Stems. Types of Stems. Derivational types of word.
The morphemic analysis of words only defines the constituent morphemes, determining their types and their meaning but does not reveal the hierarchy of the morphemes comprising the word. Words are no mere sum totals of morpheme, the latter reveal a definite, sometimes very complex interrelation. Morphemes are arranged according to certain rules, the arrangement differing in various types of words and particular groups within the same types. The pattern of morpheme arrangement underlies the classification of words into different types and enables one to understand how new words appear in the language. These relations within the word and the interrelations between different types and classes of words are known as derivative or word- formation relations.
The analysis of derivative relations aims at establishing a correlation between different types and the structural patterns words are built on. The basic unit at the derivational level is the stem.
The stem is defined as that part of the word which remains unchanged throughout its paradigm, thus the stem which appears in the paradigm (to) ask ( ), asks, asked, asking is ask-; thestem of the word singer ( ), singer’s, singers, singers’ is singer-. It is the stem of the word that takes the inflections which shape the word grammatically as one or another part of speech.
The structure of stems should be described in terms of IC’s analysis, which at this level aims at establishing the patterns of typical derivative relations within the stem and the derivative correlation between stems of different types.
There are three types of stems: simple, derived and compound.
Derived stems are built on stems of various structures though which they are motivated, i.e. derived stems are understood on the basis of the derivative relations between their IC’s and the correlated stems. The derived stems are mostly polymorphic in which case the segmentation results only in one IC that is itself a stem, the other IC being necessarily a derivational affix.
Derived stems are not necessarily polymorphic.
Compound stems are made up of two IC’s, both of which are themselves stems, for example match-box, driving-suit, pen-holder, etc. It is built by joining of two stems, one of which is simple, the other derived.
In more complex cases the result of the analysis at the two levels sometimes seems even to contracted one another.
The derivational types of words are classified according to the structure of their stems into simple, derived and compound words.
Morphology Definition
Consider the word smallest from the paragraph above. This word can be broken down into two segments that carry significance: small and -est. While -est isn’t a word in and of itself, it does carry significance that any English-speaking person should recognize; it essentially means “the most.”
A division of linguistics, morphology is the study of the smallest segments of language that carry meaning.
Language includes everything from grammar to sentence structure, and the segments of language that we use to express meaning are most often words. Morphology deals with words and their makeup. But what are words made of?
There is an even smaller unit of language than morphemes—phonemes. Phonemes are the distinct components of sound that come together to build a morpheme or word. The difference between morphemes and phonemes is that morphemes carry significance or meaning in and of themselves, whereas phonemes do not. For example, the words dog and dig are separated by a single phoneme—the middle vowel—but neither /ɪ/ (as in dig) nor /ɒ/ (as in dog) carries meaning by itself.
Morphemes are the smallest units of language that have meaning and can’t be further subdivided.
When we put together the morphemes small (which is a word by itself) and -est (which is not a word but does mean something when added to a word) we get a new word that means something different from the word small.
Small – something slight in size.
Smallest – the most slight in size.
But what if we wanted to make a different word? There are other morphemes we can add to the root word small to make different combinations and, therefore, different words.
")




")